 华为云推出自研企业级Key-Value数据库 提供企业级的稳定可靠的Redis服务能力
华为云推出自研企业级Key-Value数据库 提供企业级的稳定可靠的Redis服务能力
点的外卖总能让离店近的外卖小哥送来,双11秒杀结束后产品能立刻下架,12306火车票保证从来不超卖,微博下拉就能刷新出好友动态……这些日常碎片的背后都有着Redis的身影。提起Redis,互联网从业者无人不知,无人不晓。毕竟,开源Redis作为一款经典的“缓存”产品,能支撑众多业务架构搭建,在游戏、电商、社交媒体等行业中发挥着重要的作用,广受开发者青睐。然而近年来,随着各行业规模逐渐扩大,几乎只能依附于关系型数据库的传统“缓存”逐渐难以支撑上层业务,越来越力不从心。一旦业务规模扩大后数据量逼近内存上线,开源Redis轻则发生重要数据逐出,重则导致节点OOM宕机。而且开源Redis为了访问快速,全部数据都保存在内存中,其独有的fork机制,更让平时的内存使用不得高于50%,使得内存价格一直居高不下,导致部署成本非常高。为了解决这些难题,华为云推出了自研的企业级Key-Value数据库——云原生分布式数据库GaussDB(for Redis)(下文简称高斯Redis),让开发者用更低的成本构建依赖缓存的应用,且性能更高,运行更稳定。本文将从高斯Redis的技术架构和应用场景出发,一一道来为什么高斯Redis比开源香,以及它是如何做到又快又好的。
开源不够,自研顶上
开门见山,先看看开发者最关心的性能和成本。如下图所示,与开源Redis相比,高斯 Redis在成本、可用容量、吞吐、压缩上都有非常大的优势:

注:比较相同数据容量(约200G)的成本开销核算下来,高斯Redis以1/4的价格拥有10倍以上的可用空间,整体成本相当于是开源Redis自建数据库的1/40,这里还不包括自建Redis数据库需要额外的搭建、运维、监控、升级扩容等各项成本。同样,对比高斯Redis和开源Redis集群在X86架构下的性能测试,结果显示,它能较开源Redis集群能提供更高的QPS,更低的访问延迟,以及更低的数据存储成本。
性能优势:在相同测试条件下,高斯Redis的QPS较开源Redis集群提高了11%~19%,平均延迟和P99比Redis集群降低了70%以上,p9999比Redis集群降低了15%以上。
抗写优势:在数据量大于内存的写测试中,原生Redis集群因内存限制而OOM,高斯Redis依然可以提供不俗的性能服务,它的可用的存储空间由底层SSD大小决定的,相比原生Redis集群抗写优势显著。
数据存储成本更低:高斯Redis提供了高效的数据压缩服务,其占用的存储空间只有开源Redis集群的十分之一,相当于数据存储成本降低了10倍。
那么,高斯Redis的优势源自什么?从它的架构中或许可以窥见一斑。
存算分离,突破瓶颈 高斯Redis有两个跟业界完全不一样的特性,第一个便是独有的存算分离架构, 计算层实现热数据缓存,存储层实现全量数据的落盘,中间通过RDMA高速网络互连,通过算法预测用户的访问规律,实现数据的自动冷热交换,最终达到性能提升。该架构基于华为内部的自研分布式共享存储池, 它也是华为全栈数据服务的基石,比如文件EVS、对象存储OBS、块存储,还有数据库族、大数据族都依赖于此,可想它的强大及稳定性。
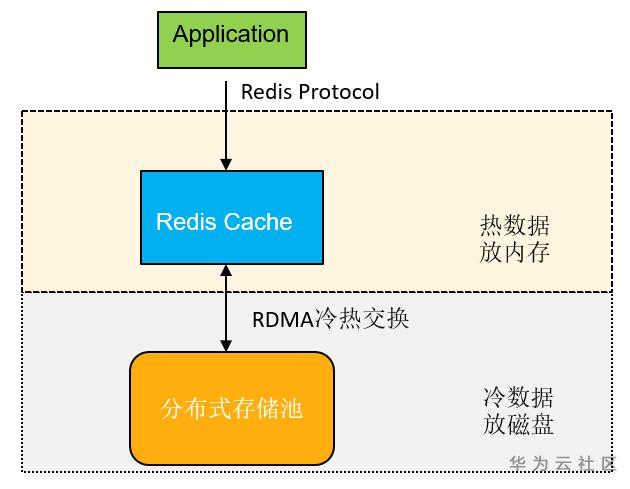
高斯Redis基于共享存储池实现了一套Shared Everything的云原生架构,充分发挥了云原生的弹性伸缩、资源共享的优势,使得它具备强一致、秒扩容、低成本、超可用等特性,完美避开了开源Redis的主从堆积、主从不一致、fork抖动、内存利用率只有50%、大key阻塞、gossip集群管理等问题。在存算分离的架构下,高斯Redis的优势可以总结为:强一致、高可用、弹性伸缩、高性能。
强一致
高斯Redis将全量数据下沉到强一致的共享存储池,得益于共享存储池的3副本机制,因此写入高斯Redis的数据,在客户端收到回复时,数据也将是3副本强一致的,保证宕机的时候数据不会丢失,从而为业务提供前后一致的状态,再也不用担心主从切换后的数据一致性和丢失问题。
高可用
其次是高可用,受益于分布式共享存储池,高斯Redis的每个计算节点都可以看到并共享所有数据,当某一个计算节点发生故障挂掉,其维护的slot路由信息,会被剩下的节点自动接管。由于不涉及底层数据的迁移,这个接管过程非常快。所以N个节点下,最多可以容忍挂掉N-1个节点。
弹性伸缩
再就是弹性伸缩带来的秒扩容能力,实现按需扩容计算和存储。计算资源的扩容只涉及到元数据的修改,把相应的slot路由信息迁移到新的节点上,迁移速度非常快。由于采用的共享存储,大多数情况下存储扩容只要进行逻辑扩容,不涉及数据的搬迁,在后台修改存储配额即可。
高性能
存算分离的架构看似比较重,链路比较复杂,实则在硬件采用、软件优化上,可以做的更大胆更激进,比如RDMA网络、用户态协议、持久化内存等等。因此受益于这些专属的存储设备,加上计算层全负荷分担架构(不引入从节点,因此性能轻松翻倍),对比同类商业数据库产品,在数据量大于内存的存储场景下,高斯Redis的性能表现很好。另外,对比开源Redis,在数据小于内存的点查场景下,高斯性能也有很大优势。第二个特性是多模架构带来的产品使用便捷性。高斯Redis是多模数据库Gauss NoSQL的一员,Gauss NoSQL提供了全栈的分布式KV引擎、用户态文件系统、存储池等技术,只需要在接口上封装Redis协议,即可轻松实现一个全新的NoSQL产品。类似的,华为还提供了MongoDB、Cassandra、Influx等NoSQL引擎。也正是得益于高斯Redis的独特优势,使得它在一些典型的应用场景下,能够应对各种突发情况,最大化发挥出Redis的特性。
互联网业务神器,支撑海量存储场景 Redis最常见的应用场景是缓存,用来存放秒杀、热点事件的数据,比如微博热搜。同时,凭借其优异的存储能力,缓存场景之外的诸多应用Redis也可以轻松应对,比如:流:feed、消息队列、IM聊天、IoT心跳上报;只读状态: 历史订单、日志审计、归档信息、历史轨迹、消费记录、物流详情;可变状态:BI报表、金融风控、智能客服、广告推荐、标签工程、用户画像、地理位置、路径规划、知识图谱等。下面,以其中的一些场景为例,具体看看高斯Redis到底有多强大?
Geo
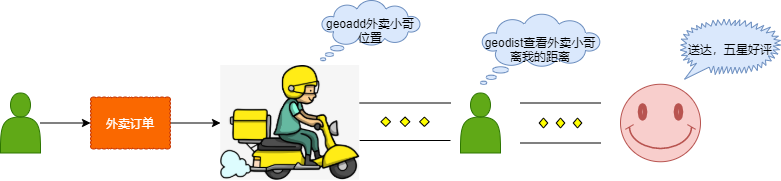
饭点时打开大众点评查看附近的餐馆,外卖小哥根据距离远近来决定配送的路径规划……这些都依靠LBS服务,它的实现又需要Redis来存储地理位置数据。但开源版本Redis因为内存限制,一直没有大规模应用支持地理位置信息存储管理的Geo功能。高斯Redis使用磁盘替代内存,解决了这些难题,它的Geo功能适用于数据量大、读写频繁的场景,可以应对诸如外卖平台、点评平台、找房平台中,随着用户增长而对应的地理位置信息的数据量的增长,最高可达TB级别。以下图为例,可以看到在高斯Redis支持下,外卖系统可以使用Geo的相关命令,让用户获取骑手的实时位置,骑手也能找到附近可配送的订单,最终顺利将用户的外卖送到用户。
计数
社交平台每条热搜记录的搜索量数值;用户注册一个帐号后,网站记录的关注数、粉丝数、动态数;一个接口一分钟被限制100次请求等。这些数据背后,是一个个计数器在工作。计数是典型的强一致应用场景,比如电商在秒杀活动中,往往会搭建Redis主从集群给下层MySQL做缓存,用Redis的计数器功能抵住流量压力。所以如果数据发生不一致,计数器就会得到错误的信息,整个数据库可能面临崩溃的危险。但原生Redis的主从同步是异步的,当主节点写入数据后,从节点不保证立刻更新数据,如果此时读取数据,读到的就是过期的旧数据,产生数据不一致问题。高斯Redis则可以把全量数据下沉到强一致共享存储池,彻底摒弃了开源Redis的异步复制机制。另外,计算层将海量数据进行分片,在故障场景下,自动进行接管,实现了服务的高可用。
即时通讯
即时通讯(简称IM)是一个实时通信系统,允许两人或多人使用网络实时的传递文字消息、文件、语音与视频。它最核心的是消息系统,包括聊天消息的同步、存储和检索。而消息存储库和同步库又对存储层的性能有很高的要求:要能支撑海量消息数据的永久存储,具备极高的写入吞吐能力,尽可能低的读取延迟等等。综上,存储层的性能会直接影响到IM系统的用户体验。高斯Redis在性能和规模上可以满足IM系统对存储层的严格要求,它作为IM系统的存储层,可以将大量的随机写转换为顺序写,提升数据写入性能,再通过读缓存、bloom filter优化读取性能。下图是一个基于高斯Redis的IM应用案例,使用的是Stream作为基本数据结构。创建一个群聊时,在Redis中对应地为该群聊创建一个Stream队列。在发送消息时,每个用户都将消息按照时间顺序添加到Stream队列中,保证了消息的有序性。
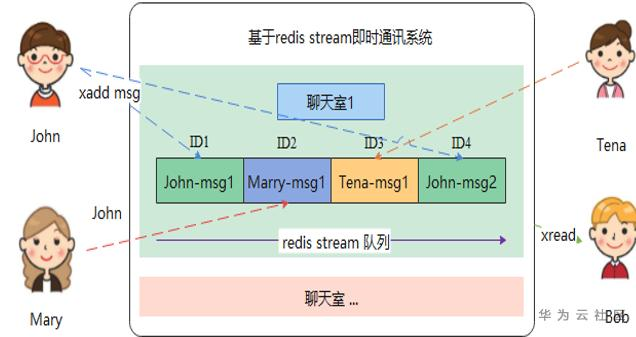
这个应用中涉及到了一种数据类型——Redis Stream,它也是一种消息队列,提供消息的落地存储功能,让每个客户端可以访问任意时刻的消息,并记录访问位置,保证消息不会丢失,以IM中的文字聊天为例,使用Stream作为中间件,实现聊天室的发言和信息查看。高斯Redis可以存储和处理大规模的Stream数据,鲁棒性强的同时成本相对更低,适用于海量消息队列的场景。所以,相较于原生Redis,是更为理想的Stream队列承载方案。
Feed流
互联网时代,微博、抖音、头条等都在通过Feed流(信息流)将关注的好友或感兴趣的内容及时推送给用户,吸引用户的兴趣,提高产品的商业价值。Feed流系统是Feed生成者将生产的Feed经过存储分发系统传递给Feed消费者,最终以某种展现形式。整个系统最关键的是同步存储系统,首先是内容存储模块,由它来存储最原始的内容,比如用户发的一条微博;其次是关联关系存储模块,存储的是用户之间的关系;最后是信箱模块,也叫消息传递模块 ,通过它将消息传递到每个关联用户手中。在Feed流场景下,高斯Redis能够支撑海量消息内容的存储和低延迟访问,以及关联关系的增删查改。在同步存储系统中的信箱存储模块,高斯Redis的Stream数据结构可以实现队列能力,实现Feed流消息读取。
推荐系统
电商、社交等领域的推荐系统非常发达,追溯其背后技术,不外乎这三个环节:分布式计算、特征存储、推荐算法。其中,特征数据的存储起到关键的衔接作用,由于KV形式的数据抽象与特征数据极为接近,因此推荐系统里往往少不了Redis的身影。由于开源Redis在大数据场景下的一些固有痛点,高斯Redis是不少客户首选的数据库选型。由高斯Redis负责核心的特征数据存储,提供稳定、可靠的KV存储能力。加上它的高性能持久化技术和细粒度存储池,可帮助企业将数据库使用成本降低75%以上。高斯Redis独特的多线程设计和全部节点可写,抗写能力强,可从容应对Spark灌库压力和实时更新。而且因为高斯Redis完全兼容Redis协议,即开即用,用户可使用熟悉的Spark SQL语法轻松访问,完成特征数据灌库、更新、提取等关键任务。与此同时,数据源经过Flink加工后,也可轻松存入高斯Redis中。
成为VMALL智能推荐背后的英雄 当电商平台对AI算法模型的需求越来越多,特征数据平台的统一建设是不少开发团队头疼的事情。只有通过统一的特征数据存储,才能改变原有的“数据孤岛”,解决生产重复造轮子的窘境。华为商城(VMALL)就有这样的困扰,VMALL使用了大量的AI和大数据技术,用来支撑智能推荐、精准营销、智能搜索、选品投放等业务的高效开展。但因为特征数据准备阶段缺乏通用平台,严重影响研发效率。特征数据库需要承担打通线上/线下多个场景,对接批式/流式多种数据源,满足训练/推理多样消费需求,相应地对存储也提出了高要求:既能提供低成本的海量数据存储并方便扩容, 又能保证数据的绝对可靠和服务的高可用;既要满足低时延的线上推理,又要满足高吞吐的线下训练; 既能提供简洁的KV接口供下游轻松消费,又要兼容主流的批式/流式处理引擎(Spark/Flink等)供上游快速接入。为了满足这些要求,深入调研后,VMALL大数据团队最终选择了高斯Redis作为特征数据库。
在线上推理的特征生产(抽取、处理、存储)中,特征平台会定时调度Spark作业,从各种数据仓库、数据湖中提取数据,进行特征工程处理后,存入高斯Redis。至于实时特征,则由Flink消费Kafka,或流式存储中的数据,持续更新到高斯Redis中。在特征消费的推理环节,对于使用实时特征的场景(如实时推荐系统),由Flink从Kafka中实时取得用户请求记录,并从高斯Redis查询取得特征,将记录和特征拼接成训练样本,存储到文件中,供线下训练使用。目前VMALL已完成一期的特征数据迁移,包括“特征生产”业务中的“Spark离线特征生产”,以及“特征消费”业务中的“线下训练Flink特征查询”。迁移后的运行结果显示,高斯Redis在业务高峰时段时延稳定,能够满足VMALL当前业务要求。其中,读平均时延0.2ms(p99《0.4ms),写入平均时延0.6ms(P99《2ms)。费用方面,按照VMALL的特征体量测算,亿级用户,每个用户的特征数量是数K-数10K,高斯Redis一年的费用仅3W出头,如果选用社区Redis,费用在20W+。综上,高斯Redis在VMALL特征工程平台建设中,起到了关键作用。它在成本,可靠性,可扩展性等方面具有优势,可作为特征数据存储的理想方案,提供企业级的稳定可靠的Redis服务能力。
最后作为一款KV数据库,高斯Redis即保留了开源Redis的能力,同时凭借其存算分离的架构,在成本、稳定性、可靠性、一致性等方面做出了新的突破,它也更加适用于当下数据规模庞大的互联网业务,包括电商平台的秒杀、推荐系统、社交平台的信息流等等。
原文标题:【大厂内参】技术架构+应用场景揭秘,为什么高斯Redis比开源香?
文章出处:【微信公众号:华为开发者社区】欢迎添加关注!文章转载请注明出处。
责任编辑:pj
-
AI
+关注
关注
87文章
31054浏览量
269404 -
数据库
+关注
关注
7文章
3821浏览量
64503 -
华为云
+关注
关注
3文章
2588浏览量
17473
原文标题:【大厂内参】技术架构+应用场景揭秘,为什么高斯Redis比开源香?
文章出处:【微信号:Huawei_Developer,微信公众号:华为开发者社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
EMQX Platform 旗舰版:面向企业级 AI 和物联网应用的高级 MQTT 消息服务

企业级数据库的配置和管理要求汇总
忆联推出企业级SATA SSD UM311b,提供稳定可靠的存储服务
忆联推出高性能企业级SATA SSD UM311b

Snowflake推出企业级AI模型
兆芯携手智云创新推出高性能NVMe企业级存储系统
芯盛智能发布搭载自研控制器芯片的企业级SS2000SE固态硬盘
江波龙企业级SSD再度通过OpenCloudOS兼容性认证,产品力获认可

GaussDB(for Redis) 特性揭秘:多租户管理

GaussDB(for Redis) 特性揭秘:大 key 治理

深度解析企业级服务器选用何种工业级连接器!

企业级SSD-高性能系列固态硬盘推荐






 工商网监
工商网监
评论