 AI训练势起,GPU要让位了?
AI训练势起,GPU要让位了?
电子发烧友网报道(文/周凯扬)人工智能在进化的过程中,最不可或缺的便是模型和算力。训练出来的通用大模型省去了重复的开发工作,目前不少大模型都为学术研究和AI开发提供了方便,比如华为的盘古、搜狗的BERTSG、北京智源人工智能研究院的悟道2.0等等。
那么训练出这样一个大模型需要怎样的硬件前提?如何以较低的成本完成自己模型训练工作?这些都是不少AI初创企业需要考虑的问题,那么如今市面上有哪些训练芯片是经得起考验的呢?我们先从国外的几款产品开始看起。
英伟达A100
英伟达的A100可以说是目前AI训练界的明星产品,A100刚面世之际可以说是世界上最快的深度学习GPU。尽管近来有无数的GPU或其他AI加速器试图在性能上撼动它的地位,但综合实力来看,A100依然稳坐头把交椅。

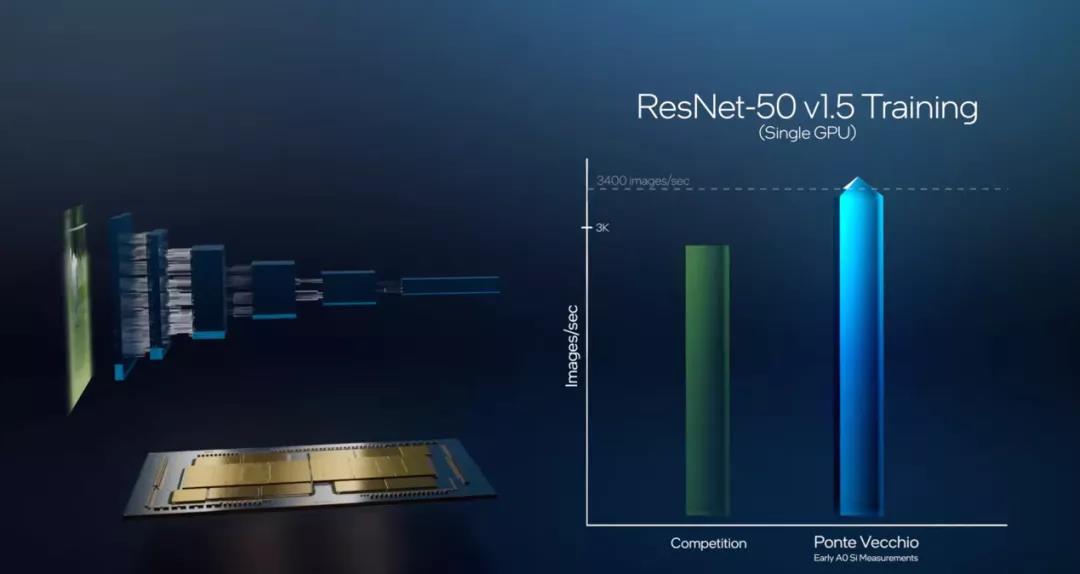
英特尔Gaudi和Ponte Vecchio
19年12月,英特尔收购了以色列的Habana Labs,将其旗下的AI加速器产品线纳入囊中。Habana Labs目前推出了用于推理的Goya处理器和用于训练的Gaudi处理器。尽管Habana Labs已经隶属英特尔,但现有的产品仍然基于台积电的16nm制程,传言称其正在开发的Gaudi2将用上台积电的7nm制程。 目前Gaudi已经用于亚马逊云服务AWS的EC2 DL1训练实例中,该实例选用了AWS定制的英特尔第二代Xeon可扩展处理器,最多可配置8个Gaudi处理器,每个处理器配有32GB的HBM内存,400Gbps的网络架构加上100Gbps的互联带宽,并支持4TB的NVMe存储。

亚马逊Trainium
最后我们以亚马逊的训练芯片收尾,亚马逊提供的服务器实例可以说是最多样化的,也包含了以上提到的A100和Gaudi。亚马逊作为云服务巨头,早已开始部署自己的服务器芯片生态,不仅在今年推出了第三代Graviton服务器处理器,也正式发布了去年公开的训练芯片Trainium,并推出了基于该芯片的Trn1实例。


小结
GPU一时半会不会跌落AI训练的神坛,但其他训练芯片的推陈出新证明了他们面对A100和Ponte Vecchio这种大规模芯片同样不惧,甚至还有自己独到的优势。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
gpu
+关注
关注
28文章
4828浏览量
129728 -
AI
+关注
关注
87文章
32329浏览量
271430
发布评论请先 登录
相关推荐
GPU是如何训练AI大模型的
在AI模型的训练过程中,大量的计算工作集中在矩阵乘法、向量加法和激活函数等运算上。这些运算正是GPU所擅长的。接下来,AI部落小编带您了解GPU
训练AI大模型需要什么样的gpu
训练AI大模型需要选择具有强大计算能力、足够显存、高效带宽、良好散热和能效比以及良好兼容性和扩展性的GPU。在选择时,需要根据具体需求进行权衡和选择。
PyTorch GPU 加速训练模型方法
在深度学习领域,GPU加速训练模型已经成为提高训练效率和缩短训练时间的重要手段。PyTorch作为一个流行的深度学习框架,提供了丰富的工具和
GPU服务器AI网络架构设计
众所周知,在大型模型训练中,通常采用每台服务器配备多个GPU的集群架构。在上一篇文章《高性能GPU服务器AI网络架构(上篇)》中,我们对GPU

AI大模型的训练数据来源分析
AI大模型的训练数据来源广泛且多元化,这些数据源对于构建和优化AI模型至关重要。以下是对AI大模型训练数据来源的分析: 一、公开数据集 公开
GPU服务器在AI训练中的优势具体体现在哪些方面?
GPU服务器在AI训练中的优势主要体现在以下几个方面: 1、并行处理能力:GPU服务器拥有大量的并行处理核心,这使得它们能够同时处理成千上万个计算任务,极大地加速
苹果承认使用谷歌芯片来训练AI
苹果公司最近在一篇技术论文中披露,其先进的人工智能系统Apple Intelligence背后的两个关键AI模型,是在谷歌设计的云端芯片上完成预训练的。这一消息标志着在尖端AI训练领域
AI训练的基本步骤
AI(人工智能)训练是一个复杂且系统的过程,它涵盖了从数据收集到模型部署的多个关键步骤。以下是对AI训练过程的详细阐述,包括每个步骤的具体内容,并附有相关代码示例(以Python和sc
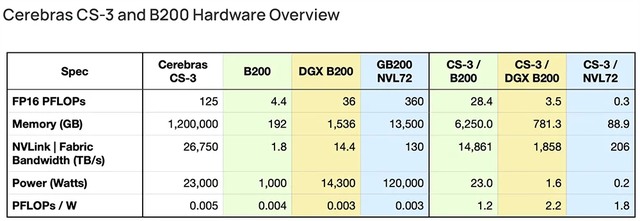
AI初出企业Cerebras已申请IPO!称发布的AI芯片比GPU更适合大模型训练
美国加州,专注于研发比GPU更适用于训练AI模型的晶圆级芯片,为复杂的AI应用构建计算机系统,并与阿布扎比科技集团G42等机构合作构建超级计算机。基于其最新旗舰芯片构建的服务器可轻松高
摩尔线程与师者AI携手完成70亿参数教育AI大模型训练测试
近日,国内知名的GPU制造商摩尔线程与全学科教育AI大模型“师者AI”联合宣布,双方已成功完成了一项重要的大模型训练测试。此次测试依托摩尔线程夸娥(KUAE)千卡智算集群,充分展现
AI训练,为什么需要GPU?
随着由ChatGPT引发的人工智能热潮,GPU成为了AI大模型训练平台的基石,甚至是决定性的算力底座。为什么GPU能力压CPU,成为炙手可热的主角呢?要回答这个问题,首先需要了解当前人

国产GPU在AI大模型领域的应用案例一览
不断推出新品,产品也逐渐在各个领域取得应用,而且在大模型的训练和推理方面,也有所建树。 国产GPU在大模型上的应用进展 电子发烧友此前就统计过目前国内主要的GPU厂商,也介绍了

FPGA在深度学习应用中或将取代GPU
对神经网络进行任何更改,也不需要学习任何新工具。不过你可以保留你的 GPU 用于训练。”
Zebra 提供了将深度学习代码转换为 FPGA 硬件指令的抽象层
AI 硬件前景
发表于 03-21 15:19





 工商网监
工商网监
评论