 NVIDIA RDMA网络方案助力远端计算和存储网络优化
NVIDIA RDMA网络方案助力远端计算和存储网络优化
云原生数据库 TDSQL-C (原 CynosDB,TDSQL for Cloud Native Database) 是腾讯云自研的新一代高性能高可用的企业级分布式云数据库, TDSQL-C 使用 NVIDIA UCX RDMA 优化了关键路径系统性能,实现了超百万级 QPS 的高吞吐,128TB 海量分布式智能存储,保障了数据安全可靠。
云原生数据库 TDSQL-C 实现高性能面临挑战
TDSQL-C 采用计算存储分离的架构,可以快速进行节点的扩容,节点的迁移,但其引入的网络开销对实现高性能提出了更高的挑战。因此需要采用软件优化与新硬件相结合,通过基于 SPDK 和 UCX RDMA 的零拷贝技术,减少了操作系统上下文切换以及数据在用户态和内核态之间拷贝引起的性能损耗,进一步优化关键路径的系统性能,降低请求延迟。
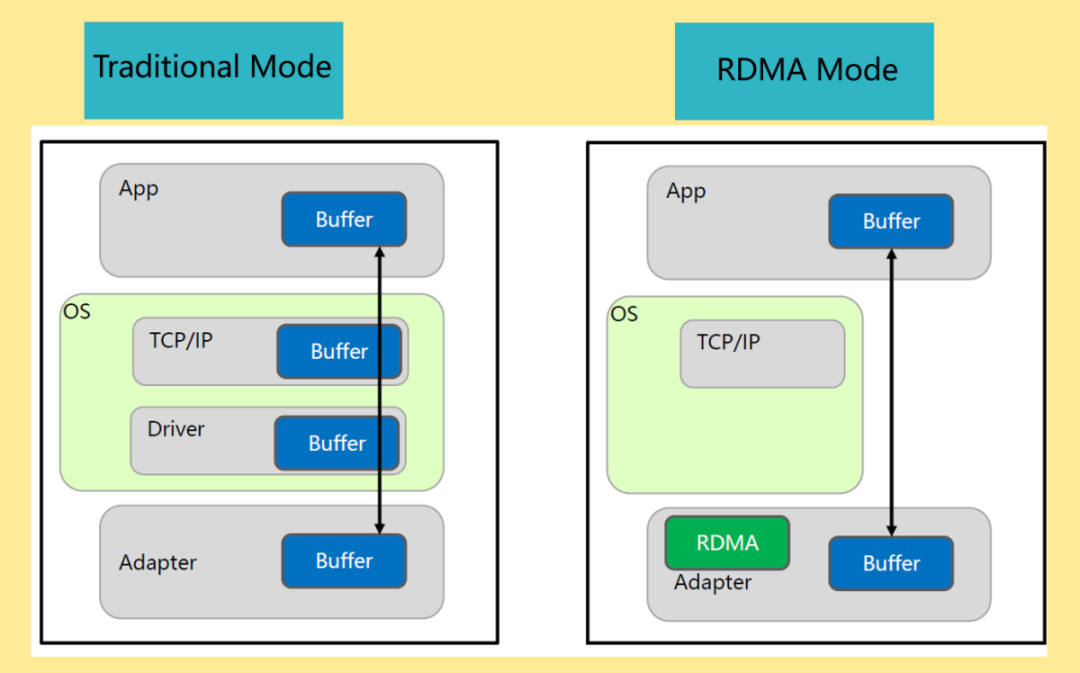
传统的 TCP/IP 网络,存在以下几个缺点:应用的 buffer 发送到对端,需要经过多次拷贝,对端收到数据到接收到应用的接收 buffer,也需要多次拷贝;应用的 buffer 拷贝到 TCP/IP 的 buffer,需要从用户态进入到内核态,会有上下文切换;网络协议栈完全由 CPU 执行,耗费 CPU。
NVIDIA RDMA 网络方案+ConnectX 系列网卡
“软硬” 兼施,赋能数据库业务持续发展
充分利用软硬件资源做系统级别 Scale Out、Scale Up、 RDMA 等 Kernel ByPass 的低延时网络基础。以底层高性能硬件能力作为支柱,给腾讯云数据库业务发展提供持续不断的系统源动力。
根据业务部门需求和服务器新产品导入团队多年来在 RDMA 技术上的沉淀, 推荐使用搭载 NVIDIA ConnectX 系列网卡的服务器,使用 NVIDIA RDMA 网络方案来对数据库场景进行专项优化,充分利用 RDMA 天然的性能优势:
RDMA 技术是用户空间进程绕过内核直接调用 RDMA 网卡,实现和远端进程的高效快速通讯。RDMA 伴生于 InfiniBand 网络技术,由 IBTA 组织对其进行标准化定义和维护。RDMA 技术优势可以解决 TCP 传输方式中的各种缺点:
整个数据传输过程内存零拷贝。
网络传输完全卸载到网卡硬件,不占用 CPU 资源。
使用 RDMA 技术可以 100% 利用网络带宽。
整个数据传输过程由硬件完成,降低了系统延时。
NVIDIA RDMA 网络方案
助力远端计算和存储网络优化
NVIDIA RDMA 网络方案搭在硬件上使远端计算和存储网络的优化效果达到最优。
在 RDMA 与 TCP 性能的关键指标的对比测试中,RDMA 体现了其优势。例如从oplog msg 性能数据上看,RDMA 测延迟比 TCP 降低 71.7%,吞吐提高 43.2%;在 page 性能数据方面(page 大小为16KB),RDMA 测延迟比 TCP 降低 70.3%,吞吐提高 52.3%。
“腾讯云数据库是腾讯服务的基础架构,网络的延迟和带宽对于性能至关重要, RDMA 技术的 Kernel Bypass 和 CPU Offload 可以带来极低的延迟和极高的带宽。在 NVIDIA 网络产品上部署的推荐系统将为腾讯用户提供业界一流的性能,使用户充分享受 RDMA 带来的技术红利。
—— 腾讯云数据库TDSQL-C负责人
李志阳
“NVIDIA 作为 RDMA 技术的推动者和领跑者,很高兴看到这项技术在腾讯得到越来越广泛的应用,并正在从传统的 HPC/AI 业务拓展到高性能存储和数据库领域。UCX 的使用大幅度提高了 RDMA 应用的开发效率和吞吐率,并且使得 RoCE 跟客户应用能迅速整合,从而帮助客户更快走向市场,并提供差异化的云产品和服务。
——NVIDIA 副总裁Vadim Balahovski
了解更多 NVIDIA RDMA 网络助力腾讯云数据库突破性能瓶颈的案例信息,欢迎点击“阅读原文”。
NVIDIA DOCA 现已开放接受申请,扫描下方海报二维码,即可注册加入,抢先体验,走在技术前沿!
原文标题:NVIDIA RDMA 网络助力腾讯云数据库突破性能瓶颈
文章出处:【微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
审核编辑:汤梓红
-
NVIDIA
+关注
关注
14文章
5087浏览量
103934 -
网络
+关注
关注
14文章
7605浏览量
89368 -
数据库
+关注
关注
7文章
3856浏览量
64802
原文标题:NVIDIA RDMA 网络助力腾讯云数据库突破性能瓶颈
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
NVIDIA Spectrum-X网络平台助力提升AI存储性能
MPLS网络性能优化技巧
加速网络性能:融合以太网 RDMA (RoCE) 的影响
Supermicro推出直接液冷优化的NVIDIA Blackwell解决方案

如何优化emc存储性能
NVIDIA助力xAI打造全球最大AI超级计算机
NVIDIA Colossus超级计算机集群突破10万颗Hopper GPU
NVIDIA 以太网加速 xAI 构建的全球最大 AI 超级计算机

以太网RDMA RoCE的技术局限
基于RDMA技术的Mayastor解决方案

神经网络优化器有哪些
如何训练和优化神经网络
降本增效:NVIDIA路径优化引擎创下多项世界纪录!
NVIDIA 发布全新交换机,全面优化万亿参数级 GPU 计算和 AI 基础设施






 工商网监
工商网监
评论