 FPGA工程师的核心竞争力 — 方法篇(二)
FPGA工程师的核心竞争力 — 方法篇(二)
在上篇文章《FPGA工程师的核心竞争力-方法篇(一)》中,针对UltraFast设计方法论进行了概述,并根据设计指南UG949介绍了前面三章的主要内容,本篇将重点学习解读后面三章内容:设计约束、设计实现和设计收敛。
设计约束
设计约束用于定义各项要求,编译流程必须满足这些要求才能在硬件中正常运行设计。对于较为复杂的设计,这些约束通常用于定义工具指南,以帮助实现收敛。并非所有约束都要在编译流程中的所有步骤中使用。例如,物理约束仅在执行实现步骤(最优化、布局和布线)期间使用。
由于综合与实现算法均由时序驱动,因此必须创建正确的时序约束。对设计进行过约束或欠约束都会导致难以实现时序收敛。为了方便设计分析,Xilinx官方指南给出的《Vivado Design Suite 用户指南:设计分析与收敛技巧》(UG906)可以参照。
5.1 对设计约束进行组织
通常约束按类别和/或按设计模块组织到 1 个或多个文件中。无论采用何种组织方式,都必须了解其整体依赖关系,并在载入存储器后复查其最终时序。
如何进行约束组织和管理呢?有的工程很小、简单,几个模块就完成了,这时候约束文件不多,不复杂。但很多时候,系统很复杂,几十个模块,多个时钟,管脚也多,约束文件最好根据类别放几个,管理起来也方便。对于IP,通常采用OOC方式进行综合,并形成独自的约束文件。
(1)建议的约束文件
根据工程大小和复杂性,有多种适用于约束组织的方法可供选择。Xilinx给出的建议是:
对于小型设计团队开发的简单设计:
• 1 个文件存储所有约束
• 1 个文件存储物理约束 + 1 个文件存储时序约束
• 1 个文件存储物理约束 + 1 个文件存储时序(综合)+ 1 个文件存储时序(实现)
对于复杂设计(含多个 IP 核或多个设计团队):
• 1 个文件存储顶层时序 + 1 个文件存储顶层物理 + 1 个文件对应 1 个 IP 或主块
(2)验证读取顺序
完成工程约束文件的组织后,必须根据文件内容验证文件读取顺序。在“工程模式”下,可在 Vivado® IDE 中或者使用 reorder_files Tcl 命令来修改约束文件的顺序。在“非工程模式”下,顺序直接由编译流程 Tcl 脚本中的read_xdc 命令(针对 XDC 文件)和 source 命令(针对由 Tcl 脚本生成的约束)来定义。
(3)建议的约束顺序
约束语言 (XDC) 基于 Tcl 语法和解读规则。与 Tcl 一样,XDC 属于顺序语言:
• 必须先定义变量,然后才能加以使用。同样,必须先定义时序时钟,然后才能将其用于其它约束中。
• 对于覆盖相同路径并具有相同优先级的等效约束,适用最后一项约束。
当考虑以上优先规则时,时序约束总体上应遵循以下顺序:
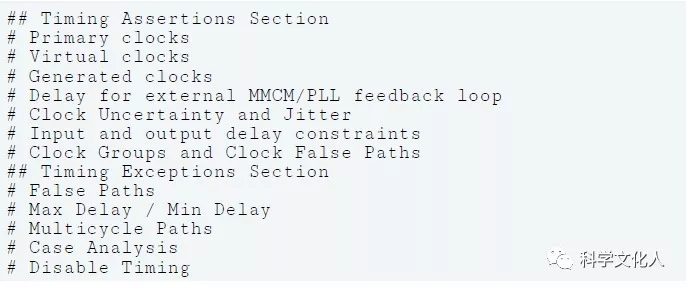
当使用多个 XDC 文件时,必须特别留意时钟定义,并验证从属关系排序是否正确。比如主时钟、生成时钟关系。
物理约束可能位于任意约束文件中的任意位置。综合工具一般会自动放在时钟约束后面,XDC文件也可手动编写,也可由工具生成。Tcl命令也能用于创建约束文件。
(4)创建综合约束
综合将提取设计的 RTL 描述,并使用时序驱动的算法将其变换为经优化的技术所映射的网表。结果质量受 RTL 代码质量和提供的约束的影响。在编译流程的这个阶段,信号线延迟建模采用近似法,无法反映布局约束或复杂影响(例如拥塞)。建模的主要目的是通过真实且简单的约束获取满足时序约束要求或者接近满足要求的网表。
重要提示!与实现阶段不同,综合可能会将用于定义时序约束的 RTL 网表对象优化掉以便实现更好的面积QoR。一般这不会导致问题,前提是对约束进行更新和验证以满足实现要求。但如果需要,仍可使用 KEEP 约束来保留任何对象以便在综合和实现期间应用约束。
(5)创建实现约束
实现约束必须准确反映最终应用的要求。物理约束(例如 I/O 位置和 I/O 标准)取决于开发板设计(包括开发板走线延迟)以及源自总体系统要求的设计内部要求。物理约束就是对管脚进行约束,包括管脚位置和电压配置等。
多数情况下,在综合与实现阶段可以使用相同的约束。但是,由于设计对象在综合阶段可能消失或发生名称变化,因此必须确认所有综合约束都可正确应用于实现网表。
(6)创建块级约束
开发多团队工程时,为方便起见,可为顶层设计的每个主要块创建独立的约束文件。通常每个主要块都会先独立开发并验证,最后再整合到 1 个或多个顶层设计中。
块级约束必须独立于顶层约束单独开发,并且必须尽可能采用通用设计以便应用于各种环境中。此外,这些约束不得影响块边界外的任何逻辑。
当实现子块时,最好在时序分析中包含全时钟网络,以确保偏差和时钟域交汇分析的准确性。这可能需要 1 个包含时钟组件的 HDL 封装器和另一个约束文件以便复制顶层时钟约束。它仅用于子模块的时序验证。
这么做的主要原因,我们可以将其叫做“去耦合”,保持相对独立性。
5.2 定义时序约束的四个步骤
合格的约束的定义过程分为四个主要步骤,如下图所示。这些步骤遵循时序约束先后顺序和从属关系规则,并采用符合逻辑的方式来向时序引擎提供信息以执行分析。
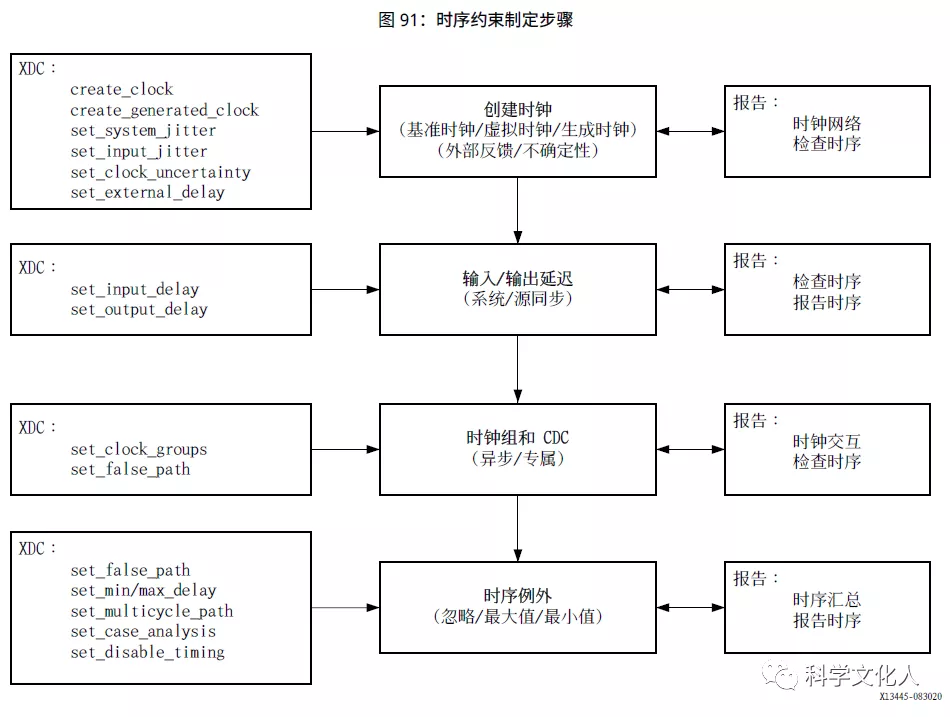
• 前 2 个步骤与时序断言有效有关,期间将从时钟波形和 I/O 延迟约束中衍生出默认时序路径要求。
• 在第 3 个步骤中,将对至少共享 1 条逻辑路径的异步或专属时钟域之间的关系进行审核。根据关系的性质,可输入时钟组或伪路径约束以忽略这些路径上的时序分析。
• 最后一个步骤对应于时序例外,设计人员可在此判定如何更改默认时序路径要求,包括利用特定约束来忽略、放宽或收紧时序要求。
从逻辑上讲,完成这四步,我们的时序约束就完成了。关于这四步详细的约束文件创建,可参考UG949第四章的4.3节至4.6节。另外,针对多周期路径约束和物理约束,可参考4.7和4.8节。
设计实现
选定器件、选择并配置 IP 且编写 RTL 和约束条件后,下一步即为实现。实现通过综合和布局布线来编译设计,然后生
成用于对器件进行编程的文件。实现过程可能包含一些迭代循环。
6.1 运行综合
综合步骤将采用 RTL 和时序约束,并生成功能上等同于 RTL 的最优化网表。通常,综合工具可以采用任何合法 RTL,并为其创建逻辑。综合需要现实的时序约束。
(1)综合流程
a.全局综合
在全局综合流程中,整个设计通过单次运行来完成综合,其优势如下:
• 允许综合工具执行最大程度地最优化。由于综合工具已发现整个设计,该工具可在层级间进行最优化,这是其它流
程无法做到的。
• 简化综合运行后的分析操作。
此流程的缺点在于编译时间较长。每次运行综合后,都会重新运行整个设计。但可通过使用增量综合来缓解此缺点的不
利影响。
b.非关联综合
在非关联综合流程中,某些层级与顶层分离,单独进行综合。非关联层级首先进行综合。然后,运行顶层综合,并且每次非关联运行都作为黑盒来处理。这就是我们所说的OOC综合方式,通常对IP和无需改动的模块采用这种方式。
此流程具有以下优点:
•缩短后续综合运行的编译时间。仅对您指定的运行进行重新综合,其它运行保持不变。•确保进行设计更改时的稳定性。仅对包含更改的运行进行重新综合。
此流程的缺点在于需要额外进行设置。您必须谨慎选择将哪些模块设置为非关联综合模块。任何额外 XDC 约束都必须单独定义,并且仅限用于非关联综合运行。
c.块设计综合
块设计综合流程支持您使用定制 IP 和赛灵思 IP 创建复杂系统。在此流程中,将使用 Vivado IP integrator 创建块设计(BD) 文件。赛灵思 IP 或定制 IP 将被添加到此 .bd 文件中并作为系统进行连接。此流程具有以下优点:
• 将大量功能封装到小型设计中。
• 支持集中精力处理整个系统,而不是系统的各部分。
• 简化并加速设计的设置和综合。
块设计中,主要涉及调用处理器,设计完成后,一般不会再去修改,在顶层文件中直接调用。
d.增量综合流程
您可使用增量综合来复用现有综合结果。此方法具有以下优点:
• 将典型综合编译时间缩短 50%。
• 配合增量实现流程一起使用时,可缩短总体编译时间并提升时序收敛一致性。
当顶层设计为 RTL 并且 RTL 在设计中所占比重较大时,增量综合将具有最高的价值。在此模式下,综合编译时间将得到最优化,并将复用结果。对于包含大量块设计和/或 IP 的设计,Vivado Design Suite 会在这些块上自动拆分综合,并以非关联模式运行综合。因此,增量综合对这些设计的价值较小。
增量综合可通过复用来自参考综合运行的未经修改的层级来缩短编译时间。要使增量综合发挥作用,设计必须包含至少5 个分区,每个分区至少 10,000 个实例。此外,必须尽可能减少任何设计更改所影响的分区数量,并且不得在设计顶层执行更改。
注意:某些更改可能会影响跨边界最优化,从而导致其它分区需要重新进行综合。
所以,当改动很小,不影响跨边界优化时,可采用增量综合。
(2)综合最优化
默认情况下,Vivado 综合将应用能够为最大量的设计产生最佳结果的最优化措施。大部分情况下,我们都按默认综合进行优化,当然,也可根据实际需要进行综合设置。
很多时候,我们比较关注有些关键信号是否被优化掉,需要使用相关综合属性。使用 KEEP、DONT_TOUCH 和 MAX_FANOUT 属性时,需要特别注意对综合带来的影响。
6.2 综合后的步骤
确保综合过程中您已获得的网表质量优良,这样它就不会在下游造成问题。
(1)检查和清理 DRC
report_drc 命令可运行设计规则检查 (DRC) 以寻找常见设计问题和错误。默认规则检查如下:
• 综合后网表
• I/O、BUFG 和其它特定的布局需求。
• 属性和 MGT、IODELAY、MMCM、PLL 的连线以及其它原语。
(2)运行 Report Methodology
Vivado 工具中提供了“方法论报告 (Report Methodology)”,专用于检查是否符合方法论指南要求。这些工具根据所处的设计进程阶段运行不同的检查。
• RTL 设计:RTL lint 风格检查
• 综合设计和实现设计:网表、约束和时序检查。
(3)复查综合日志
必须复查综合日志文件并确认该工具提供的所有消息与您期望的设计用途相匹配。请特别关注“严重警告 (CriticalWarnings)”和“警告 (Warnings)”。大多数情况下,需修复“严重警告 (Critical Warnings)”才能实现可靠的综合结果。
通常,在消息栏会给出错误或警告提示,对于严重警告,必须进行修复。
(4)检查时序约束
您必须提供简单标准的时序约束以及时序例外(如果适用)。错误的约束将导致编译时间过长、性能问题以及硬件故障。
6.3 实现设计
Vivado Design Suite 实现包括在器件资源上对网表进行布局布线,同时满足设计的逻辑、物理和时序约束所需的所有步骤。
通常,我们使用默认的实现策略,主要有以下三个过程:
• opt_design
• place_design
• route_design
在 Vivado Design Suite 中,可以使用增量实现来复用现有布局和布线数据,从而缩短实现的编译时间,并提升结果的可预测性。当所处理的设计复用比例达到甚至超过 95% 时,增量布局和布线编译时间通常仅为正常布局和布线运行时间的一半甚至更短,同时参考运行的 WNS 仍保持不变。
设计收敛
设计收敛包括满足所有时序、系统性能和功耗要求,并成功验证硬件中的功能。设计收敛通常需要在结果分析、设计修改和约束修改之间进行几次迭代。
7.1 时序收敛
时序收敛是指设计满足所有的时序要求。针对综合采用正确的 HDL 和约束条件就能更易于实现时序收敛。
要成功完成时序收敛,遵循下列常规准则进行操作:
• 最初不能满足时序要求时,请在整个流程中评估时序。
• 集中精力解决每个时钟的最差负时序裕量 (WNS) 是改进总体时序负裕量 (TNS) 的主要途径。
• 复查严重的最差保持时序裕量 (WHS) 违例 ( • 重新评估设计选择、约束和目标架构之间的利弊取舍。
• 了解如何使用工具选项和赛灵思设计约束 (XDC)。
• 请注意,满足时序要求后,工具就不会再尝试进一步改进时序(额外裕度)。
在实现完成后,会产生时序报告,要特别关注最差负时序裕量 (WNS)和总体时序负裕量 (TNS),需要检查正时序裕量。
以下是指示存在时序违例的时序指标。为了满足时序要求,数字必须为正。
• 建立/恢复(最大延迟分析):WNS > 0 ns 且 TNS = 0 ns
• 保持/移除(最小延迟分析):WHS > 0 ns 且 THS = 0 ns
• 脉冲宽度:WPWS > 0 ns 且 TPWS = 0 ns
7.2 功耗分析与最优化
鉴于功耗的重要性,Vivado 工具支持采用各种方法来获取准确的功耗估算以及各种功耗最优化功能。
(1)估算整个流程的功耗
随着设计流程进入综合与实现阶段,必须定期监控和检查功耗以确保热耗散保持在预算范围内。一旦功耗与预算值过于接近就可及时采取补救措施。
使用下列 XDC 约束指定功耗预算,以报告功耗裕度:
set_operating_conditions -design_power_budget
该值供 report_power 命令使用。计算所得片上功耗与功耗预算之差即为功耗裕度,超出功耗预算时,该值在Vivado IDE 中将以红色显示。这样更便于监控整个流程中的功耗状况。
功耗估算的精确性因估算时的设计阶段而异。要通过实现来估算综合后功耗,请运行 report_power 命令,或者在Vivado IDE 中打开“Power Report”。
(2)功耗最优化
如果功耗估算超出预算,那么必要采取措施来降低功耗。
a.分析功耗估算和最优化结果
使用 report_power 生成功耗估算报告后,赛灵思建议执行以下操作:
• 在“Summary”部分中检查总功耗。总功耗和结温是否符合热处理与功耗预算?
• 如果结果严重超出预算,应根据块类型和电源轨检查功耗分布汇总情况。这样便于您了解哪些块功耗最高。
• 复查“Hierarchy”部分。按层级细分后,功耗最高的模块将清晰可见。您可深入查看具体模块,以确定块的功能。
也可以在 GUI 中进行交叉探测,以确定模块特定部分的编码方式以及是否可通过能效更高的方法对其进行重新编码。
b.运行功耗最优化
功耗最优化适用于整体设计或部分设计(使用set_power_opt),用于最大限度降低功耗。
c.使用功耗最优化报告
为确定功耗最优化的影响,在 Tcl 控制台中运行如下命令以生成功耗最优化报告:
report_power_opt -file myopt.rep
7.3 配置与调试
成功完成设计实现后,下一步就是将设计加载到器件中并在硬件上运行。配置是指将特定应用的数据加载到器件内部存储器中的过程。
(1)配置
必须首先成功完成设计综合与实现,然后才能创建比特流镜像。生成比特流并且对所有 DRC 都完成分析和更正后,即可使用以下任一方法将比特流加载到器件上:
• 直接编程:
通过线缆、处理器或定制解决方案将比特流直接加载到器件。
• 间接编程:将比特流加载到外部闪存。闪存再将比特流加载到器件。
可使用 Vivado 工具来完成下列操作:
• 创建比特流(.bit 或 .rbt)。
• 可选择“Tools” → “Edit Device”以复查比特流生成的配置设置。
• 将比特流格式化为闪存编程文件 (.mcs)。
(2)调试
系统内调试允许您在目标器件上实时调试设计。遇到几乎无法复制仿真器的情况时,就需要执行此步骤。在上板调试前,最好先对工程进行仿真,起码的功能验证要通过,不然调试的结果并不理想。
调试步骤如下所述:
1. 探测:确定设计中要探测的信号和探测的方法。
2. 实现:完成设计实现,包括连接到所探测的信号线上的其它调试 IP。
3. 分析:与设计中包含的调试 IP 进行交互,以便对功能问题进行调试和验证。
4. 修复相位:修复所有缺陷,此步骤可按需重复。
a.使用ILA核
通常,我们会使用ILA核对待观察信号进行探测,捕获波形和数据,进行量化,导出.csv数据到MATLAB进行数据分析。
Vivado 工具提供了多种方法用于在设计中添加调试探针。下表逐一解释了这些方法,并介绍每种方法各自的优劣。
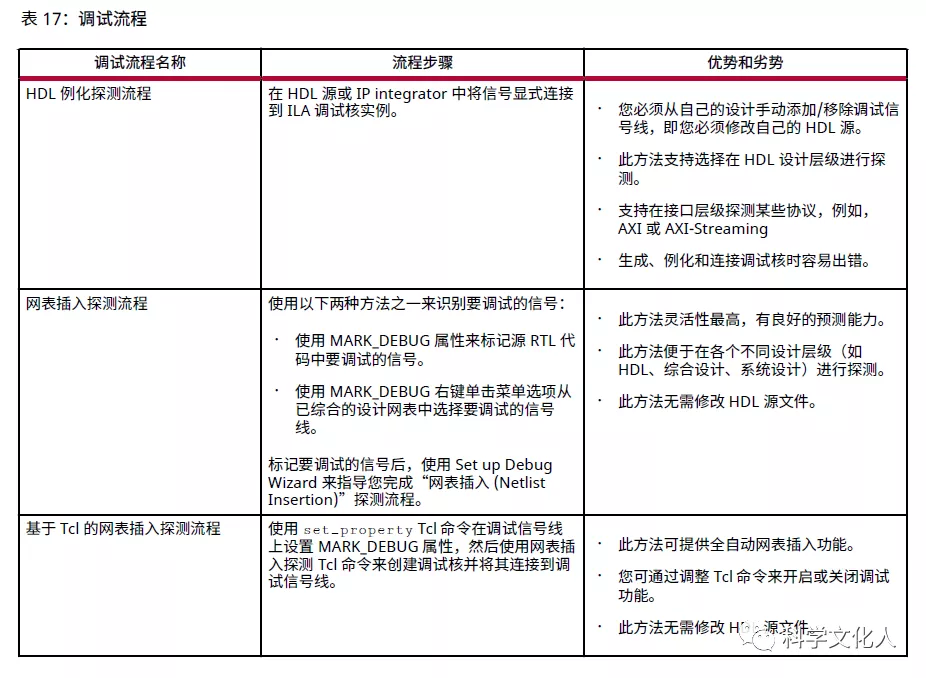
注意,ILA 核的配置会对能否满足整体设计时序目标产生影响。请根据下列建议进行操作,以便最大程度减少对时序的影响:
• 请审慎选择探针宽度。随探针宽度增加,对资源利用率和时序的影响也会增大。
• 请审慎选择 ILA 核数据深度。随数据深度增加,对块 RAM 资源利用率和时序的影响也会增大。
• 请确保为 ILA 核选择的时钟均为自由运行的时钟。否则可能造成在器件上加载设计时无法与调试核通信。
• 请确保提供给 dbg_hub 的时钟为自由运行的时钟。否则可能造成在器件上加载设计时无法与调试核通信。可使用
connect_debug_port Tcl 命令将调试中心的 clk 管脚连接到自由运行的时钟。
• 在添加调试核之前完成设计上的时序收敛。赛灵思不建议使用调试核来调试时序相关问题。
• 如果仍发现因添加 ILA 调试核而导致时序劣化,并且关键路径位于 dbg_hub 中,请执行以下步骤:
1. 打开综合设计。
2. 找到网表中的 dbg_hub 单元。
3. 转至 dbg_hub 的“Properties”选项卡。
4. 找到 C_CLK_INPUT_FREQ_HZ 属性。
5. 将其设置为链接到 dbg_hub 的时钟频率 (Hz)。
6. 找到 C_ENABLE_CLK_DIVIDER 属性并将其启用。
7. 重新执行设计实现。
• 请确保输入到 ILA 核的时钟与正在探测的信号同步。否则在设计编程到器件中时会产生时序问题并导致通信失败。
• 在硬件上运行设计之前请确保设计已满足时序要求。否则会导致探测到的波形不可靠。
下表列出了在设计时序和资源时使用特定 ILA 特性的影响。
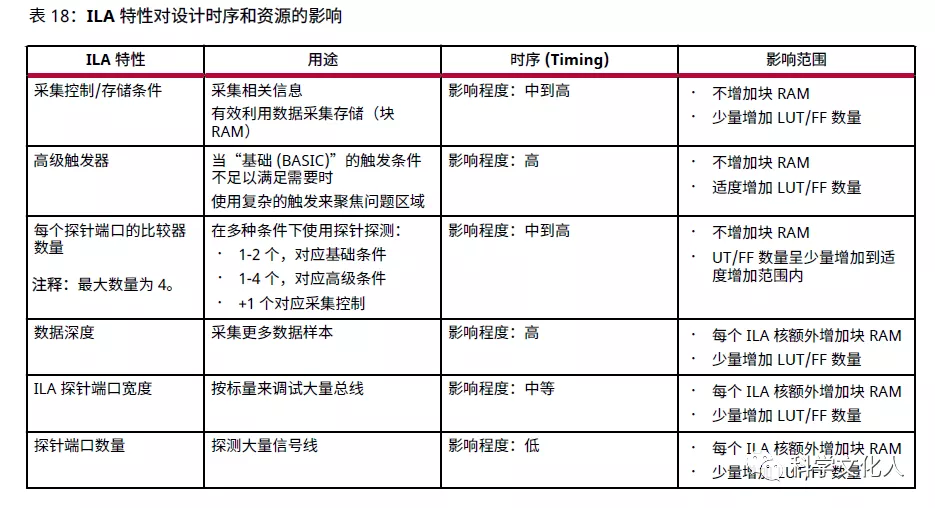
对于高速时钟设计,请注意如下事项:
• 限制调试的信号数量和宽度。
• 将输入探针通过流水线输送到 ILA (C_INPUT_PIPE_STAGES),可增加流水线阶段的层级。
b.使用VIO核
Virtual Input/Output (VIO) 核支持实时监控和驱动内部器件信号。如果需要启动或监控低速信号(如复位信号或状态信号),请使用此核。VIO 调试核必须在设计中例化,并且可在 Vivado IP integrator 块和 RTL 中使用。在 IP 目录中包含 VIO 核,可在基于 RTL 的设计和 IP integrator 中使用。
关于UltraFast设计方法论中的主要内容,就到此结束了,里面还有更详细的描述,有助于FPGA工程师进行更好的工程设计。总结一下:
(1)我们初步了解了什么是UlraFast设计方法论,及其包含的设计目与主要内容;
(2)重要参考文档有:UG949、UG1231、UG1292、UG1046、UG835、UG903等;
(3)我们重点学习了利用RTL创建设计、如何进行设计约束、如何设计实现以及如何实现设计收敛;
(4)设计方法论可进行实践指导,我们在具体工程项目中,需要灵活使用这些设计方法,以便高效设计,进而缩短开发周期,尽快推出产品。
后记:
花了一天的时间,粗略地把UltraFast设计方法过了一遍,说实话,挺累的。看文献和码字,除了体力劳动,还有脑力劳动。不管你能不能看懂,总会有一点点收获吧。
欢迎大家留言,如果觉得有所帮助,那今天的劳动也没有白费,你说呢。
参考文献
[1]Xilinx ,《UltraFast设计方法指南》(UG949)。
审核编辑:符乾江
-
FPGA
+关注
关注
1629文章
21748浏览量
603957 -
编程
+关注
关注
88文章
3621浏览量
93785
发布评论请先 登录
相关推荐
中国AI企业创新降低成本打造竞争力模型

FPGA算法工程师、逻辑工程师、原型验证工程师有什么区别?
学习SOLIDWORKS提高学生的就业竞争力


硬件工程师业余时间变现,应该从何处入手?
嵌入式软件工程师如何提升自己?


数据中台:如何构建企业核心竞争力






 工商网监
工商网监
评论