 机器学习模型的可解释性算法详解
机器学习模型的可解释性算法详解
本文介绍目前常见的几种可以提高机器学习模型的可解释性的技术,包括它们的相对优点和缺点。我们将其分为下面几种:
1. Partial Dependence Plot (PDP);
2. Individual Conditional Expectation (ICE)
3. Permuted Feature Importance
4. Global Surrogate
5. Local Surrogate (LIME)
6. Shapley Value (SHAP)
六大可解释性技术
01. Partial Dependence Plot (PDP)
PDP是十几年之前发明的,它可以显示一个或两个特征对机器学习模型的预测结果的边际效应。它可以帮助研究人员确定当大量特征调整时,模型预测会发生什么样的变化。
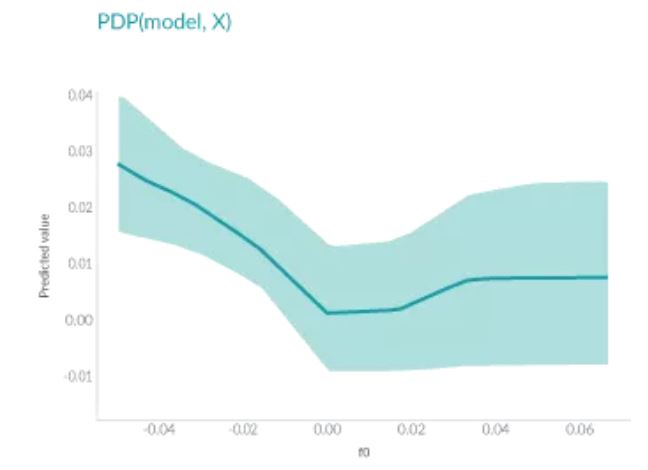
上面图中,轴表示特征的值,轴表示预测值。阴影区域中的实线显示了平均预测如何随着值的变化而变化。PDP能很直观地显示平均边际效应,因此可能会隐藏异质效应。
例如,一个特征可能与一半数据的预测正相关,与另一半数据负相关。那么PDP图将只是一条水平线。
02. Individual Conditional Expectation (ICE)
ICE和PDP非常相似,但和PDP不同之处在于,PDP绘制的是平均情况,但是ICE会显示每个实例的情况。ICE可以帮助我们解释一个特定的特征改变时,模型的预测会怎么变化。
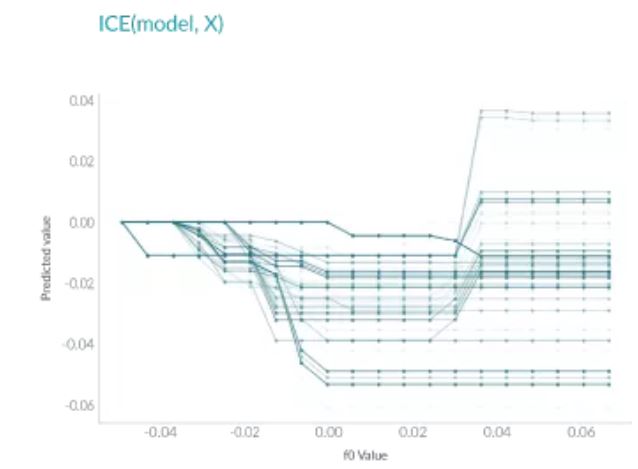
如上图所示,与PDP不同,ICE曲线可以揭示异质关系。但其最大的问题在于:它不能像PDP那样容易看到平均效果,所以可以考虑将二者结合起来一起使用。
03. Permuted Feature Importance
Permuted Feature Importance的特征重要性是通过特征值打乱后模型预测误差的变化得到的。换句话说,Permuted Feature Importance有助于定义模型中的特征对最终预测做出贡献的大小。
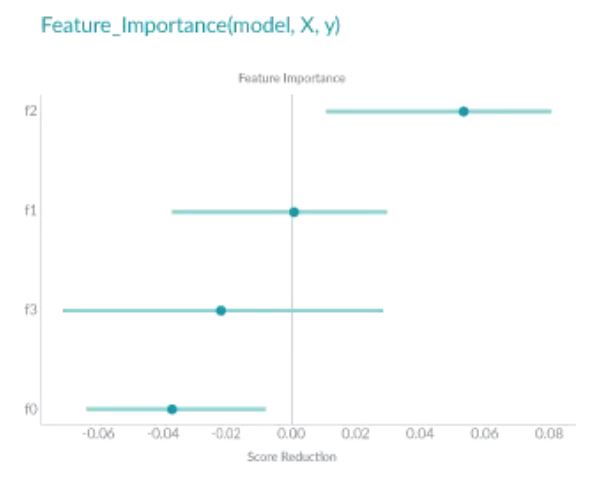
如上图所示,特征f2在特征的最上面,对模型的误差影响是最大的,f1在shuffle之后对模型却几乎没什么影响,生息的特征则对于模型是负面的贡献。
04. Global Surrogate
Global Surrogate方法采用不同的方法。它通过训练一个可解释的模型来近似黑盒模型的预测。
首先,我们使用经过训练的黑盒模型对数据集进行预测;
然后我们在该数据集和预测上训练可解释的模型。
训练好的可解释模型可以近似原始模型,我们需要做的就是解释该模型。
注:代理模型可以是任何可解释的模型:线性模型、决策树、人类定义的规则等。
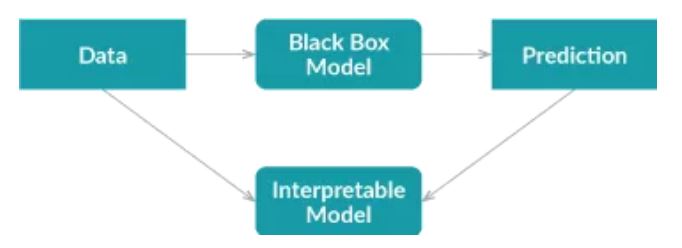
使用可解释的模型来近似黑盒模型会引入额外的误差,但额外的误差可以通过R平方来衡量。
由于代理模型仅根据黑盒模型的预测而不是真实结果进行训练,因此全局代理模型只能解释黑盒模型,而不能解释数据。
05. Local Surrogate (LIME)
LIME(Local Interpretable Model-agnostic Explanations)和global surrogate是不同的,因为它不尝试解释整个模型。相反,它训练可解释的模型来近似单个预测。LIME试图了解当我们扰乱数据样本时预测是如何变化的。
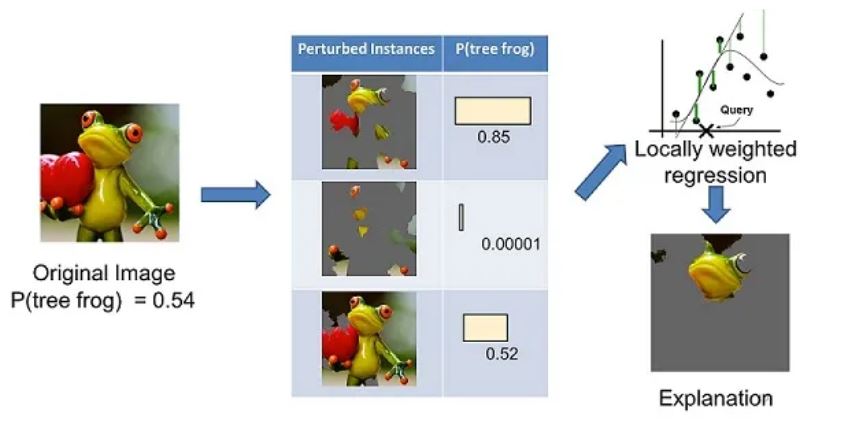
上面左边的图像被分成可解释的部分。然后,LIME 通过“关闭”一些可解释的组件(在这种情况下,使它们变灰)来生成扰动实例的数据集。对于每个扰动实例,可以使用经过训练的模型来获取图像中存在树蛙的概率,然后在该数据集上学习局部加权线性模型。最后,使用具有最高正向权重的成分来作为解释。
06. Shapley Value (SHAP)
Shapley Value的概念来自博弈论。我们可以通过假设实例的每个特征值是游戏中的“玩家”来解释预测。每个玩家的贡献是通过在其余玩家的所有子集中添加和删除玩家来衡量的。一名球员的Shapley Value是其所有贡献的加权总和。Shapley 值是可加的,局部准确的。如果将所有特征的Shapley值加起来,再加上基值,即预测平均值,您将得到准确的预测值。这是许多其他方法所没有的功能。
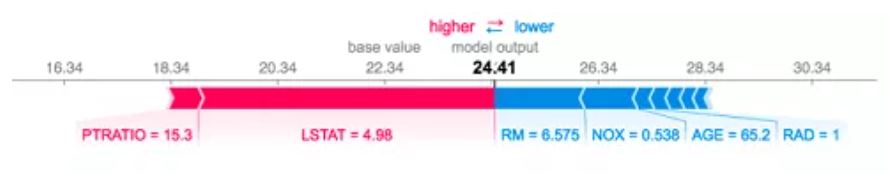
该图显示了每个特征的Shapley值,表示将模型结果从基础值推到最终预测的贡献。红色表示正面贡献,蓝色表示负面贡献。
小结
机器学习模型的可解释性是机器学习中一个非常活跃而且重要的研究领域。本文中我们介绍了6种常用的用于理解机器学习模型的算法。大家可以依据自己的实践场景进行使用。
参考文献
https://www.twosigma.com/articles/interpretability-methods-in-machine-le...
【免责声明】本文转载自:Datawhale,转载此文目的在于传播相关技术知识,版权归原作者所有,如涉及侵权,请联系小编删除(联系邮箱:service@eetrend.com )。
审核编辑:符乾江
-
PDP
+关注
关注
0文章
53浏览量
36243 -
机器学习
+关注
关注
66文章
8438浏览量
132989
发布评论请先 登录
相关推荐
《具身智能机器人系统》第7-9章阅读心得之具身智能机器人与大模型
NPU与机器学习算法的关系
一种基于因果路径的层次图卷积注意力网络

鲁棒性在机器学习中的重要性
常见AI大模型的比较与选择指南
AI大模型与深度学习的关系
《AI for Science:人工智能驱动科学创新》第二章AI for Science的技术支撑学习心得
Al大模型机器人
机器学习算法原理详解

【大规模语言模型:从理论到实践】- 阅读体验
【大语言模型:原理与工程实践】核心技术综述
Meta发布SceneScript视觉模型,高效构建室内3D模型
AI算法在矿山智能化中的应用全解析





 工商网监
工商网监
评论