 英特尔BigDL深挖大数据价值 助力分布式人工智能广泛落地
英特尔BigDL深挖大数据价值 助力分布式人工智能广泛落地
“没说就是零卡。”近日,网络健身博主@秃顶吴彦祖的金句意外走红,揭开了无数撸铁干饭王的最强自我欺骗套路——只要食物包装上没有注明卡路里,吃了它我就不会发胖!除此之外,“冰可乐没有热量”、“卡路里正正得负”等高频弹幕也常常令人忍俊不禁。实际上,它们并不仅仅是几句戏言,通过Transformer Cross Transformer (TxT)人工智能推荐系统,汉堡王发现,当人们把高热量食物而非低热量食物加入购物车时,他们更愿意再点一份甜点。也就是说,高热量食物和高热量食物更配哦!另外,TxT还发现,即使天气很冷,汉堡王的顾客都会点上一份奶昔——而此前人们一般认为,低温天气会使冷饮销量降低。
其实,想要在客户服务中使用人工智能,尤其是快餐推荐,线下快餐门店面临着自己独特的挑战。相比电子商务、搜索引擎等能够在较为充裕的时间内通过大量推理与训练,掌握用户偏好的行业,对于快餐品牌而言,目前仍然没有什么简单的方法可以在瞬间识别客户并检索到他们的档案,因为所有食物推荐都是在线下完成的。此外,在把位置、上下文特征加载到模型之前,还必须对此类数据进行预处理,对于要求快速响应的线下快餐门店来说,这着实是一个不小的难题。
为了应对这些挑战,汉堡王的Transformer Cross Transformer (TxT)人工智能推荐系统应运而生。该系统采用了所谓的“双”Transformer架构,既能够学习实时订单序列数据,也能够学习位置、天气和订单行为等特征。TxT可以利用餐馆中所有可用的数据点,而无需在接单流程开始之前识别顾客。例如,如果顾客在其购物车内加入的第一款商品是奶昔,那么这将影响TxT的推荐,这些推荐基于顾客过去购买的商品、当下购买的商品以及商店售卖的商品。这是从模型方面的创新。
另一方面的创新则是统一的大数据处理和模型训练的流水线。目前,大多数企业的做法是建立两个模型,一个模型做大数据处理,一个模型做深度学习,但这一方式效率低下,拷贝文件就占了整个训练20%以上的时间。而英特尔和汉堡王合作创建的端到端推荐流水线将整个端到端的数据处理和模型训练迁移到基于BigDL的统一的平台上,其中包括分布式Apache Spark数据处理和在英特尔至强集群上进行的Apache MXNet训练,能够让企业直接在现有集群上运行程序,从而大大提高了人工智能的工作效率。
说到这里,你会发现,想要将AI部署于现实的应用,其中所面临的一个重大挑战就是针对生产数据集进行数据分析、机器学习和深度学习。生产数据集来源于庞大的分布式数据仓库,而按照传统方法,企业需要设立两个单独的集群,一个用于大数据,导出数据并转移到另外一个深度学习集群进行建模,该集群运行TensorFlow、PyTorch等。在这种架构下,首先会产生大量与数据移动相关的开销,其次,它会产生隔离的工作流,从而大大降低开发效率。
而针对上述难题,英特尔BigDL 2.0有着清晰的解决思路——提供一个统一的大数据架构,为分布式AI提供统一的端到端管道。如此一来,企业就可以在同一个集群、同一个应用内使用Spark等处理数据仓库中的数据。在此基础上,人们可以针对内存Spark Dataframes直接使用TensorFlow、PyTorch、OpenVINO等深度学习AI模型。Spark Dataframes是驻留在内存中的数据集,分布在整个集群上,客户可以透明地在分布式数据集上使用这些AI模型、AI算法——都在一个集群内,更重要的是,一个程序,只需一个工作流。
通过这种方法,英特尔的一些客户,如中国最大的软硬件厂商之一的浪潮,已经成功将研发周期从几个季度缩短到几个月。毋庸置疑,这一显著的进步极大推动了人工智能现实应用的进一步发展。
而在这一成就的背后,是英特尔BigDL 2.0所凝结的大量创新。分布式模式运行本地笔记本上的代码。实际上,这一直是很多数据科学家的痛点,他们没法简单地获取一个单节点PythonNotebook,并在集群上以分布式模式运行,因此,他们通常需要重写代码。
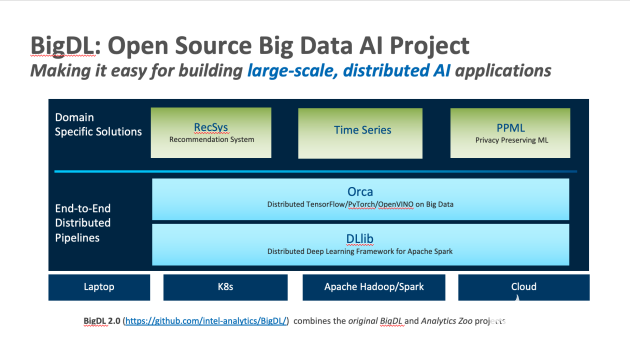
在Orca中,英特尔BigDL尝试让用户可以把笔记本电脑上运行的Notebook部署到分布式集群,云中托管的Kubernetes集群、或者Hadoop集群。在Notebook的一开始,只需调用Orca下文中的一个方法,它会告诉程序用户希望运行哪个环境,可以是在本地笔记本电脑上,也可以是本地集群或者Kubernetes集群等。只需改变一行代码,这个Notebook就可以在本地笔记本电脑上运行,模拟分布式集群规模,在分布式环境中处理大型数据集。
而在更高层级的运用,即基于这些管道开发更垂直的行业解决方案中,用户可以通过BigDL PPML,在云上创建一个支持大数据和AI的可信平台环境。在把数据或者模型转移到云上之前,用户可以使用加密技术保护内容,然后通过BigDL PPML直接在加密数据上运行应用软件、模型、Spark数据分析等,PPML会在可信环境中读取加密数据,解密并运行相应的应用,同时确保数据的安全性和应用的完整性。在此基础下,BigDL PPML还可以提供可信的联邦学习(也被称为联合学习)——每一方只拥有一部分信息和功能,但他们可以联合训练一个模型,而不需要向另一方披露数据。通过SGX提供的硬件级的安全环境,联邦学习场景中的性能和安全性能够得到有效保证。
此外,BigDL之上构建的其他垂直行业解决方案还包括Chronos项目——一个利用AutoML技术构建大规模、分布式时间序列分析的应用框架,可用于时序数据的处理,滑动窗口取样、缩放、重采样、补全,以及自动的特征提取。同时,其中内置了大量时序预测和异常检测模型,用户可以直接使用TSDataset构建时序应用进行数据处理,使用对应的模型进行预测或者异常检测。AutoML技术帮助用户搜索最佳的模型参数以提高模型预测的准确性。 Chronos同时内置了Intel的分类加速工具可以帮助用户取得更好的训练与推理速度;以及Friesian项目——用于构建大规模端到端推荐解决方案的应用框架,提供了丰富的内置特征工程操作、推荐算法和参考样例,帮助用户快速构建一个完整的推荐系统来应对离线或者在线的推荐场景。
总而言之,作为一个开源项目,BigDL能够提供端到端大数据人工智能管道,让用户、科学家和数据工程师更容易构建大规模分布式人工智能解决方案,并使其变得更加容易。它还提供各种垂直框架,如推荐、时间序列分析、隐私保护机制,以帮助用户快速整合他们的AI解决方案。或许在并不遥远的未来,伴随着人工智能在人类生活中更加深度的渗透,BigDL与大数据的结合将为我们揭示更多意想不到的神奇真相。
-
英特尔
+关注
关注
61文章
9911浏览量
171583 -
人工智能
+关注
关注
1791文章
46927浏览量
237794 -
机器学习
+关注
关注
66文章
8382浏览量
132464 -
大数据
+关注
关注
64文章
8865浏览量
137327
发布评论请先 登录
相关推荐
IC China 2024北京开幕:英特尔分享洞察,促智能计算应用落地

嵌入式和人工智能究竟是什么关系?
人工智能技术跃进:英特尔引领AI无处不在新纪元
探秘IO分布式模块设计:让大数据处理更高效

浪潮信息分布式存储AS13000完成英特尔至强6能效核处理器适配


英特尔人工智能创新应用大赛最终奖项揭晓!酷睿Ultra助力选手创意开发

爱立信与英特尔携手推动Open RAN与人工智能发展
分布式存储与计算:大数据时代的解决方案
嵌入式人工智能的就业方向有哪些?
英特尔人工智能创新应用大赛开启!为更多用户带来 AI PC 生产力及娱乐体验跃升
分布式IO工业自动化数据采集与分析的核心
用AI PC助力创新无限想象,英特尔人工智能创新应用大赛正式启动
第五代英特尔至强可扩展处理器 AI 性能大幅提升,英特尔加注推动人工智能无处不在





 工商网监
工商网监
评论