 智行者提出全新基于ivox激光雷达算法
智行者提出全新基于ivox激光雷达算法
近日,智行者高翔博士带领的定位团队撰写的论文《Faster-LIO: Lightweight Tightly Coupled Lidar-inertial Odometry using Parallel Sparse Incremental Voxels》被国际公认的自动驾驶领域TOP级期刊IEEE Robotics and Automation Letters收录刊登。
该文章主要对激光雷达算法进行了深入探讨,本文提出了一种基于iVox(incremental voxels)的算法,以快速跟踪旋转的激光雷达-惯性里程计(LIO)方法固态激光雷达扫描。在该算法中,智行者定位团队使用iVox作为点云空间数据结构,即从传统的体素修改,支持增量插入和并行近似k-NN查询。该算法可以有效的降低点云配准时的耗时,也不会影响LIO的精度表现。
干货内容如下:
前言
众所周知SLAM现在越来越卷了。卷来卷去,大概有几种卷的方向:
一是卷精度。然而同样传感器做成的数据集大体来说不会有数量级上的精度差异,大部分论文都会说在某个数据集上得到了百分之几的精度提升,然而原因比较玄学,不好归因,实际当中也不一定看的出来。
二是卷鲁棒性。鲁棒性倒是非常实在,别人跑丢了的数据我跑成功了,鲁棒性自然就好。不过开源的数据集相比真实数据来说九牛一毛。开源数据集有十来个数据就显得不错了,实际当中往往是几百几千的车辆和机器人在跑,数据集那几个包才哪到哪,能体现的鲁棒性指标很有限。
三是卷效率。效率也是实打实能看到的。别人算100ms,我算50ms,那效率就实实在在地快了一倍。别人要工控机,我用嵌入式;别人占满CPU,我跑一半的CPU,那整个系统就更流畅丝滑。而且卷效率没那么玄学,哪哪算的快了都可以找到原因,和数据集关系也不大。这就是我们这次选择卷效率的一个理由。
Lidar-inertial odometry (LIO)是SLAM这边卷的还不那么厉害的方向之一。纯Lidar的SLAM已经比较稳定了,几个开源方案(cartographer, Loam系列)跑得也挺顺,虽然大体上要慢一些。不过到了LIO,你会发现一些神奇的现象:开源的LIO大部分只能在自己的数据集上跑,换一个数据集就很容易飞或者挂。前期的方案考虑的东西太少,在后出的数据集上通常会出问题。近期的方案则相对要稳定一些,但依然没有纯Lidar方案那么稳定,各种指标也有一定的提升空间。
本文要谈的Faster-LIO是基于FastLIO2开发的。FastLIO2是开源LIO中比较优秀的一个,前端用了增量的kdtree(ikd-tree),后端用了迭代ESKF(IEKF),流程短,计算快。Faster-LIO则把ikd-tree替换成了iVox(后文介绍),顺带优化了一些代码逻辑,实现了更快的LIO。我们在典型的32线激光雷达中可以取得100-200Hz左右的计算频率,在固态雷达中甚至可以达到1000-2000Hz,能够达到FastLIO2的1.5-2倍左右的速度。当然具体数值和计算平台相关。读者也可以用自己的平台测试一下Faster-LIO在你机器上的表现。
介绍
我们就不聊LIO在什么自动驾驶或者无人机上的应用背景之类的话题了,直接切入主题。
大体来讲,LIO系统的整个计算流程是比较固定的:它们从IMU中得到一个粗略的估计,然后把雷达的数据与一些历史数据做配准,最后用某种状态估计算法进行滤波或者优化。IMU部分的处理差别不大,所以LIO系统的计算效率主要与点云算法和后端算法相关,我们大致分三个方面:
点云最近邻的数据结构。点云配准的基本问题是计算给定点与历史点云的最近邻,通常需要依赖一些最近邻的数据结构。这些数据结构又大体分为树类的(tree like)和体素类(voxel like)的。广义的,高维的最近邻问题是一个比较复杂的问题,但LIO里的最近邻则是低维的、增量式的问题。于是,像R*树、B* 树等静态的数据结构并不是非常适合LIO。FastLIO2里提出使用增量式的kdtree来处理最近邻,我们则认为增量的体素更适合LIO系统。
点云残差的计算方式。自动驾驶里普遍偏向不直接使用点到点的残差,而是使用点到线或点到面的残差。点到点的残差形式虽然简单,但雷达点云和RGBD点云相比,更加稀疏,在车辆运动过程中不见得都能打到同一个点,而且点云也往往会被降采样后再进行处理,所以并不太适合在自动驾驶中使用。LOAM系列会计算点云特征,实际当中特征提取要花的时间是不可忽略的,甚至是主要计算部分。
状态估计算法的选型。LIO和VIO中普遍会使用介于单帧EKF和批量优化之间的方案,例如IEKF、MSCKF、Sliding Window Filter等等。这其中又以IEKF算是最简单有效的一类,既有迭代来保证精度,又不需要像预积分系统那样算一堆雅可比矩阵。
所以这样一看,能进一步挖掘的地方主要是LIO的近邻结构。Kd树类结构的优势在于,可以严格地查询K近邻,不会多也不会少;也可以以范围或盒子形式来查询最近邻(range search/box search)。查询过程中也以设置附加条件比如最大距离,实现快速的近似最近邻查找(Aproximate Nearest Neighbor, ANN)。然而传统的Kd树是不带增量结构的。像ikd-tree这种带增量加点的结构,虽然不用完全重新构建,但也需要花额外的时间去维护这个树的结构。我们不禁要问:LIO里真的需要严格的K近邻搜索吗?能不能放宽一点,使用更简单的结构?
实际上点云配准往往不需要严格的K近邻。如果K近邻找到了一个很远的点,拿这个点过来做点面残差也是不合理的,这部分计算就是无效的。我们不妨让近邻结构本身就具有这种查找范围限制,而kd树即使带了范围限制,也需要一个节点一个节点地来遍历,这种遍历显然也是会耗时的。于是我们来考虑一种基于体素的近邻结构。考虑到点云的稀疏性,我们希望体素也能够以稀疏的形式存储。体素具备一些天然的优点:一是天然具有K近邻时的范围限制;二是增量构建的时候不需要额外的操作,删除的时候也很方便;三是最近邻的范围也可预先定义,想多搜点就多搜点,想快点就少搜点,丰俭由人;四是很容易并行化或者GPU化。
于是FasterLIO使用了一种基于稀疏体素的近邻结构iVox(incremental voxels)。我们会发现这种结构用来做LIO更加合适,可以有效的降低点云配准时的耗时,也不会影响LIO的精度表现。我们使用两个版本的iVox:一种是线性的,一种是基于空间填充曲线的(伪希尔伯特空间曲线,pseudo-Hilbert curve, PHC),下面来说明其原理。
iVox
iVox由空间中稀疏分布的体素组成。每个体素内部可以存在多个点,体素自身的网格坐标由空间哈希函数映射到哈希键值上,再组成哈希表。
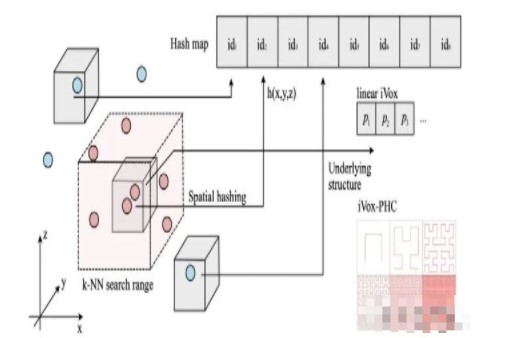
哈希函数可以取一些典型形式。由于实际存储的是三维点,我们使用简单的空间哈希即可:
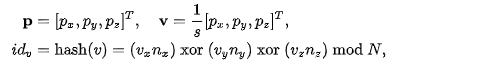
其中p为三维点,v为体素网络,id是它的哈希键值,xor表示异或。
iVox内部点的存储方式称为它的底层结构。最简单的底层结构是线性的,我们称为线性的iVox;如果要存的点很多,我们利用空间填充曲线来存,称为iVox-PHC。当然在LIO算法流程上,我们会避免在同一个体素中大量插入点而影响计算效率,所以两种算法实际用起来差异不大。
K近邻的查找
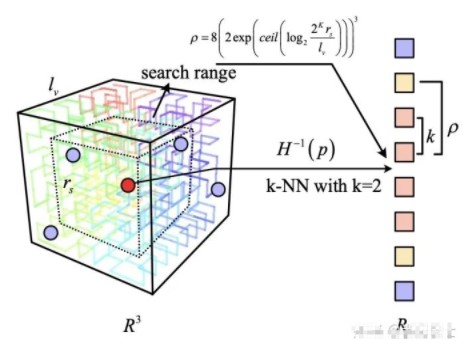
iVox里的K近邻相对简单。我们首先定义一个体素的近邻范围,典型的有0,6,18,26这几种。实际当中主要用18和26.
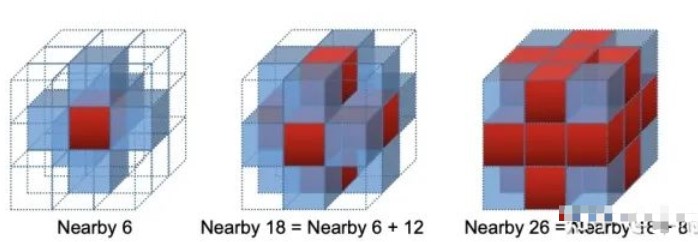
在查找K近邻时,先计算被查找的点落在哪个体素中,然后看预定义的范围内是否存在有效的iVox。如果有,就把这些iVox内部的点也考虑进来。我们在每个iVox内部查找至多K个最近邻,再进行合并即可。线性的iVox只须遍历内部点,然后进行部分排序,再进行汇总。PHC的iVox则可以根据空间填充曲线上的索引值来查找最近邻。
PHC是一种建立高维数据与低维数据映射的方法。离散的PHC可以看成把空间分成许多小格子,然后给每个格子找一个id的过程。于是,在查找某个点的最近邻时,可以先看它在这个iVox里的曲线上ID,然后在这个ID周边找到若干个近邻,再返回其结果即可。在点数较多时,PHC的查找会比线性查找的复杂度更低一些。
增量地图更新
iVox的增量地图更新比kd树简单很多。简而言之,算出增加点对应的体素网格,直接往里添加即可。如果是PHC的,则还需要算一下PHC的曲线位置。除此之外没有其他操作了。
在FastLIO2中,系统会删除一部分历史点云,让局部地图跟随车辆前进。在iVox里,由于遍历整个iVox局部地图是比较慢的,我们让这个过程变为被动删除,而不是主动地在每帧计算后进行删除。于是我们给局部地图添加一个LRU缓存(least recently used),在进行近邻搜索时,记录哪些体素是最近使用过的,那么不怎么使用的体素自然被移动到队尾。我们会设置一个局部地图的容量,超过最大容量时,就删除那些很久未使用的体素。删除操作是针对整个体素的,内部的点会被全部删除。这种局部地图缓存策略也会让局部地图跟随车辆运动,而实际操作的地方更少。
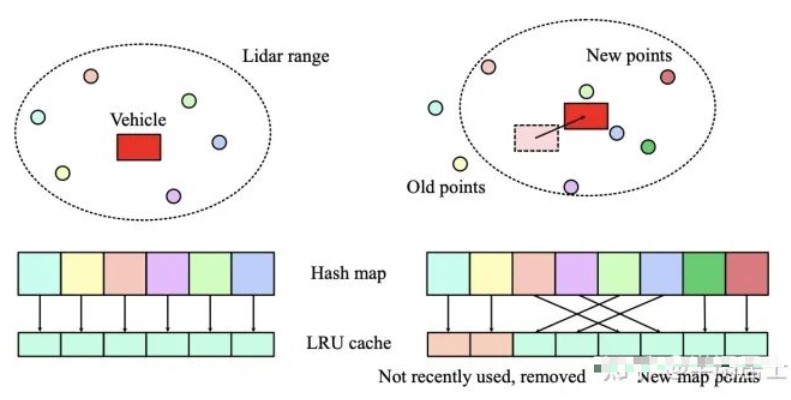
iVox的具体参数和复杂度等细节见论文和代码,这里不再描述。
实验
实验部分主要包含仿真实验和数据集实验。
仿真实验
仿真实验是在一个随机生成的点云里进行K近邻查找以及新增地图点的实验。我们对比了Kdtree flann, ikd-tree, nanoflann R-tree, faiss-IVF, nmslib几个库。耗时与地图点数的关系图如下:
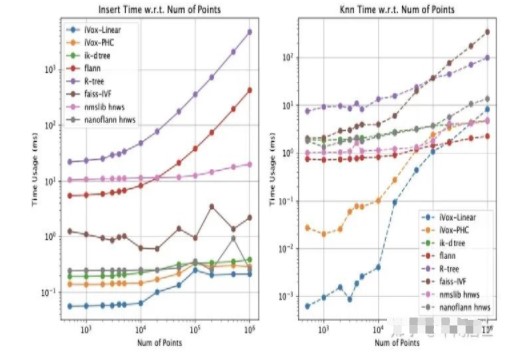
可以看到iVox在K近邻查找和新增的耗时都是很少的,但它们随地图点数的增长会更快,毕竟单个iVox里的点会变多。顺便说一句,PCL Kdtree的查询速度(这里写的flann)也是杠杠的,只是没有增量接口。
我们也比较了iVox的K近邻质量问题。大部分时候iVox的K近邻不是严格的,因为天然的有范围限制。我们把K近邻的结果与暴力搜索的结果进行比对,可以得到它的召回率(recall)。各算法的召回率与时间曲线如下:
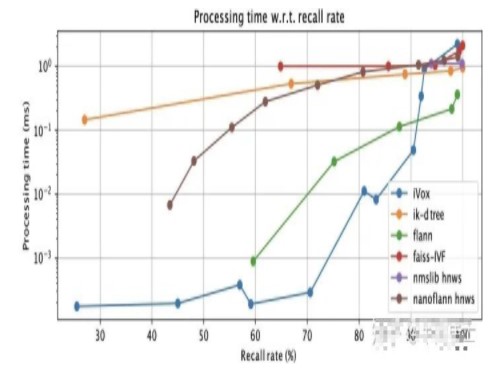
如果要求iVox有很高的召回,那就不得不设置很大的体素尺寸或者很大的搜索近邻,这时候iVox的查找时间会增长很快。不过LIO系统在70%左右的召回率下就能很好地工作,所以实际也没啥大不了的。
数据集实验
数据集实验主要比较整个LIO系统的耗时和计算精度。由于Faster-LIO框架与FastLIO2基本相同,我们时间上对标的也主要是FastLIO2,其他系统主要是用来做个参考。32线雷达的详细步骤算法耗时如下图所示:
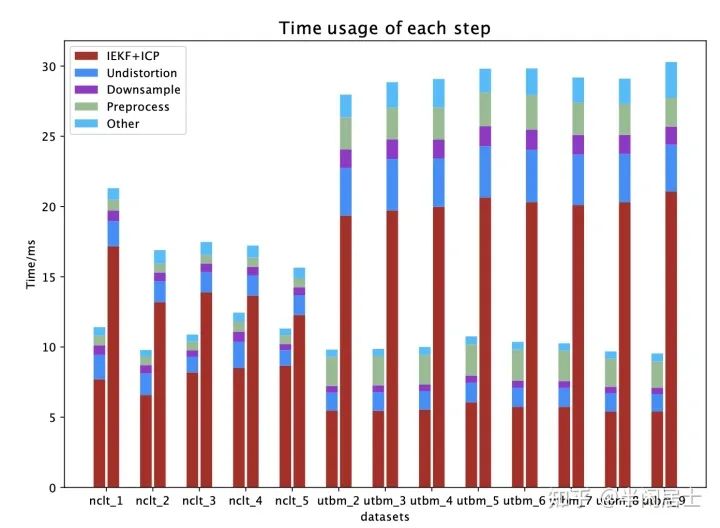
可见主要的耗时在IEKF+ICP的迭代过程。使用iVox替代iKd-tree时,我们缩短的也主要是这个过程。UTBM数据集要明显一些,我们可以把差不多20ms的IEKF迭代降到5-8ms左右,整个流程可以从30ms左右降到10ms左右,实现明显的效率提升。
我们也绘制了时间轴上的耗时曲线,如下:
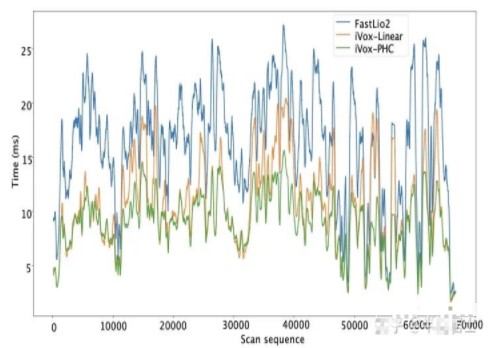
两个版本的LIO的运算效率不会随着时间有明显变化,而FasterLIO要明显用时更低一些。对LIO-SAM、LiLi-OM的一些计算用时指标可以参考论文的表格。
在精度方面,考虑到LIO默认不带回环检测,所以我们主要评价每百米的漂移误差指标(百分比形式),见下表。
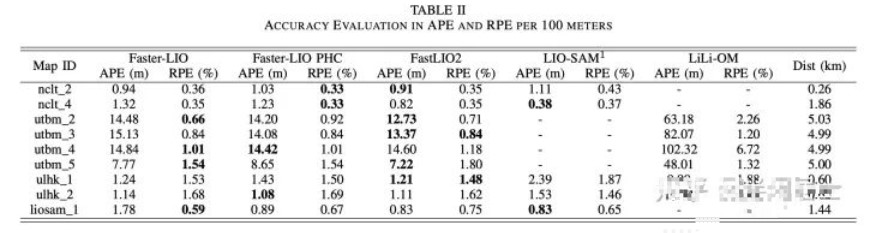
实际上,只要不漂,LIO精度都是差不多的,天下哪有改改算法就提升精度的事情(逃)。
iVox也可以被集成到其他LO或LIO里,但是大部分方案里,最近邻并不是主要的计算瓶颈,gtsam/ceres什么的耗时相比最近邻那可太多了。我们也尝试了把iVox集成到Lego-LOAM里,发现主要只是省了增量地图构建那部分时间,优化方面没什么变化(点少)。所以iVox与FastLIO倒是相性更好一些。
结论与声明
本文提出了一种更快速的LIO方法,使用iVox作为最近邻方案,在同等精度指标下可以明显提升LIO计算速度。
我们也欢迎读者自己测试Faster-LIO的计算性能。祝大家科研愉快。
同时,智行者还提供了开源代码以更方便社区使用。
原文标题:顶刊收录!智行者提出全新基于ivox激光雷达算法
文章出处:【微信公众号:智行者科技】欢迎添加关注!文章转载请注明出处。
审核编辑:汤梓红
-
算法
+关注
关注
23文章
4633浏览量
93474 -
激光雷达
+关注
关注
969文章
4041浏览量
190544 -
自动驾驶
+关注
关注
785文章
13954浏览量
167252
原文标题:顶刊收录!智行者提出全新基于ivox激光雷达算法
文章出处:【微信号:idriverplus,微信公众号:智行者科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
CES 2025激光雷达观察:“千线”激光雷达亮相,头部厂商布局具身智能

一则消息引爆激光雷达行业!特斯拉竟然在自研激光雷达?
激光雷达在SLAM算法中的应用综述
激光雷达会伤害眼睛吗?

激光雷达的维护与故障排查技巧
激光雷达技术的基于深度学习的进步
激光雷达技术的发展趋势
光学雷达和激光雷达的区别是什么
一文看懂激光雷达

基于FPGA的激光雷达控制板

硅基片上激光雷达的测距原理

激光雷达的探测技术介绍 机载激光雷达发展历程
亮道智能:发布全新一代激光雷达,未来主攻固态激光雷达低价市场
激光雷达LIDAR基本工作原理






 工商网监
工商网监
评论