 高速串行收发器的重要概念和注意事项
高速串行收发器的重要概念和注意事项
此篇文章深入浅出介绍了关于高速串行收发器的几个重要概念和注意事项,为方便知识点复习总结和后续查阅特此转载。
一、为什么要用Serdes
传统的源同步传输,时钟和数据分离。在速率比较低时(<1000M),没有问题。
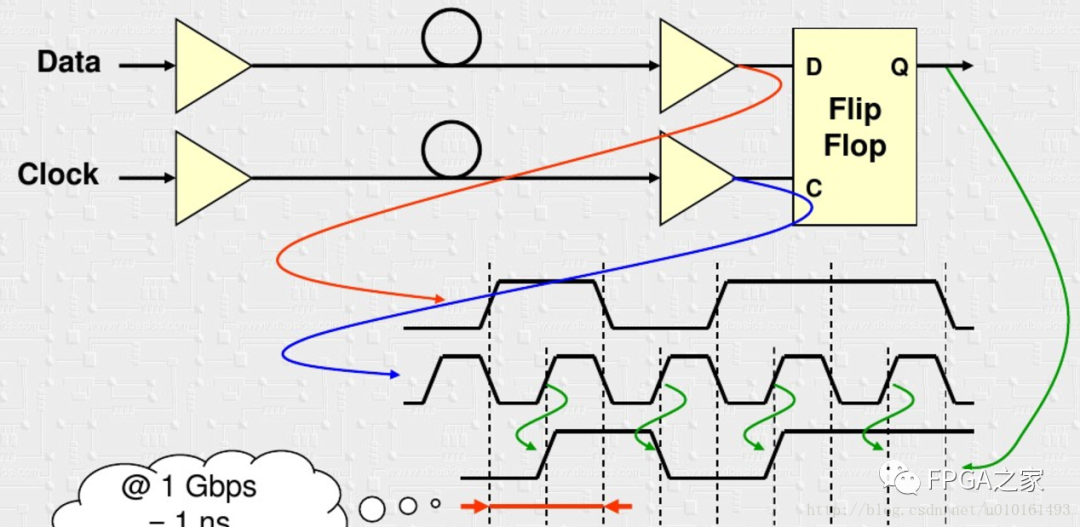
在速率越来越高时,这样会有问题
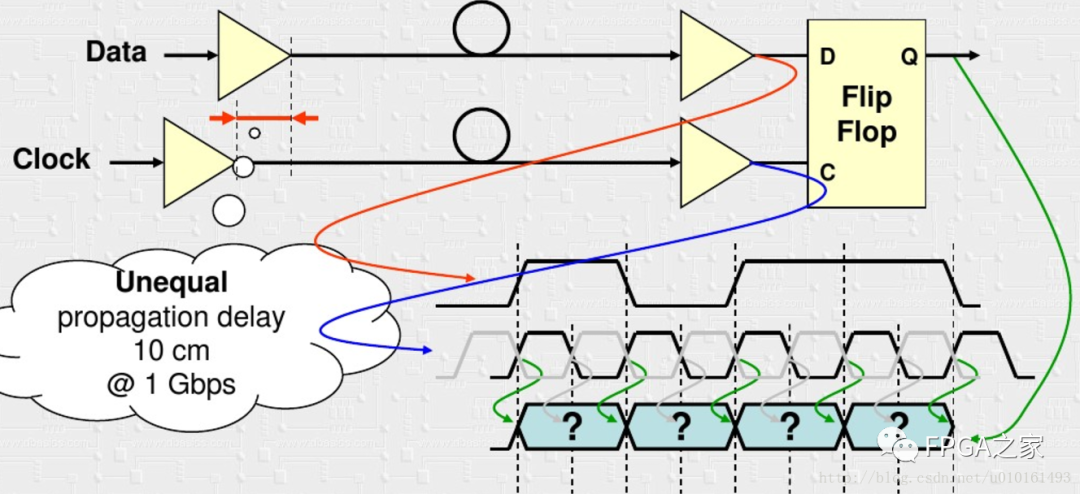
由于传输线的时延不一致和抖动存在,接收端不能正确的采样数据,对不准眼图中点。然后就想到了从数据里面恢复出时钟去采样数据,即CDR
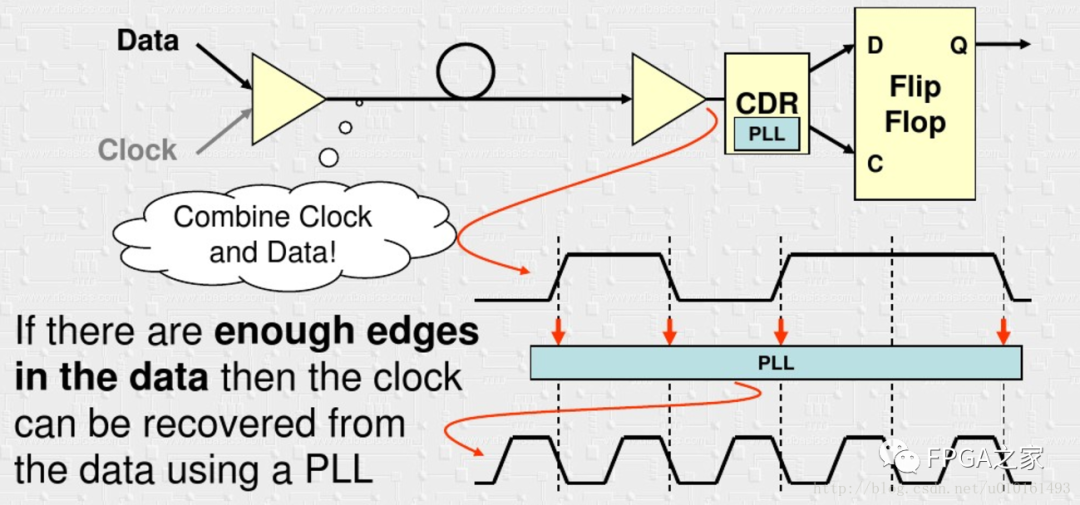
这样就不存在延迟不一致的情况,有轻微的抖动也不会影响采样(恢复的时钟会随着数据一起抖动)。
二 、为什么要用8b10b,64b66b?
1 提供足够的跳变来恢复时钟
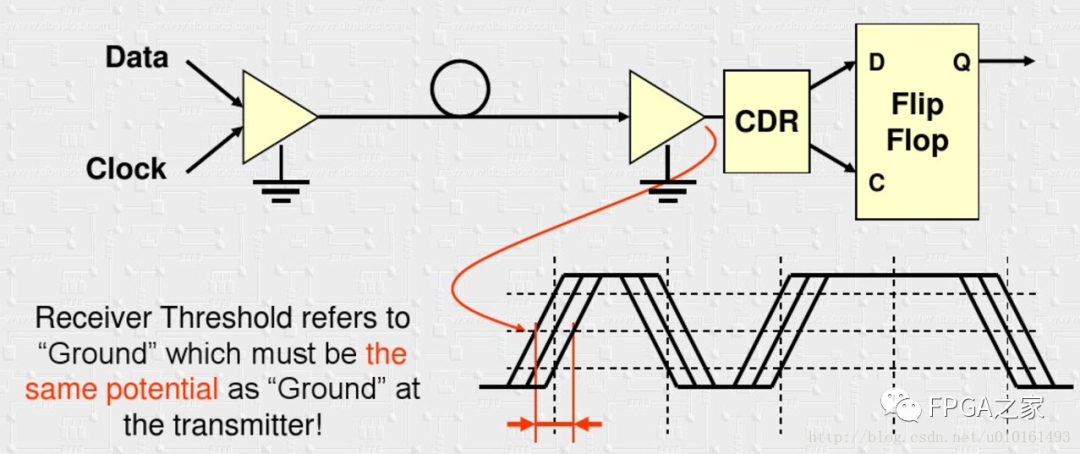
这样还有问题,收发两端必须共地,但往往很难实现。
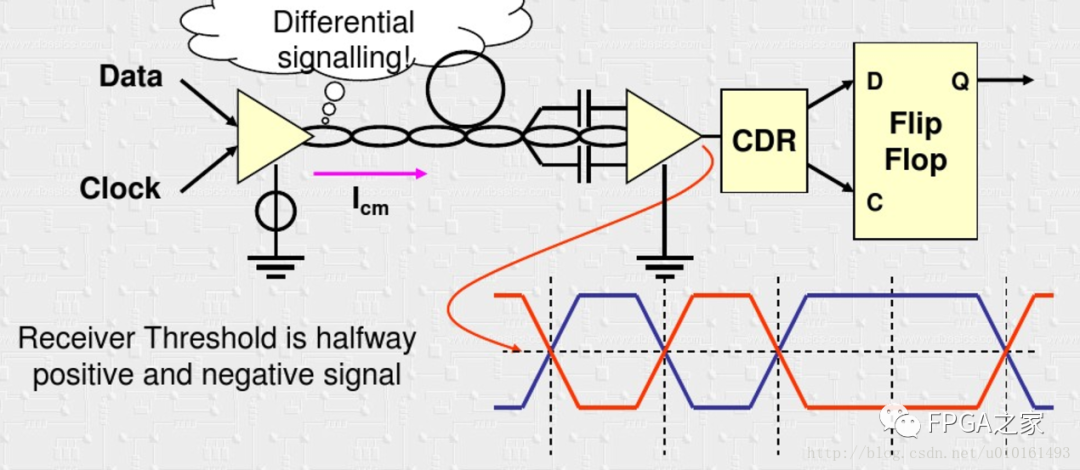
于是采样差分信号传输,为了防止共模电压在接收端导致电流过大,使用电流驱动模式。看到接收端有电容进行交流耦合,隔直流。这样又带来一个问题,需要DC平衡。所以有了下面另一个原因。
2 DC平衡,即0和1的数量要相等。
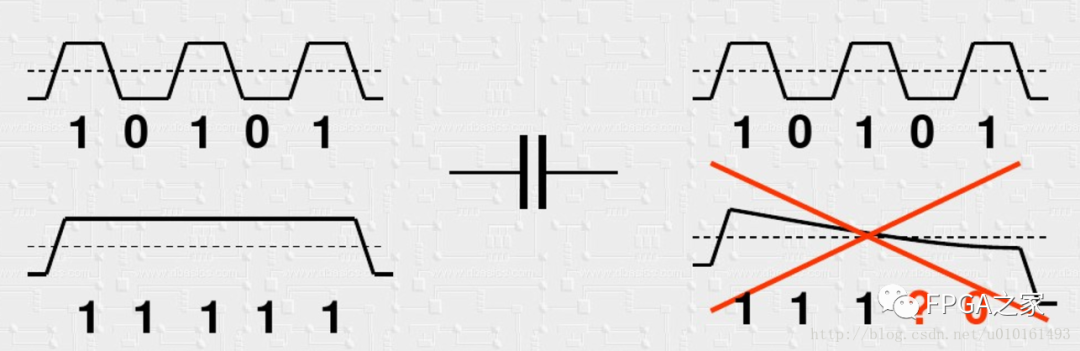
3 run length,0和1连续出现的最大长度
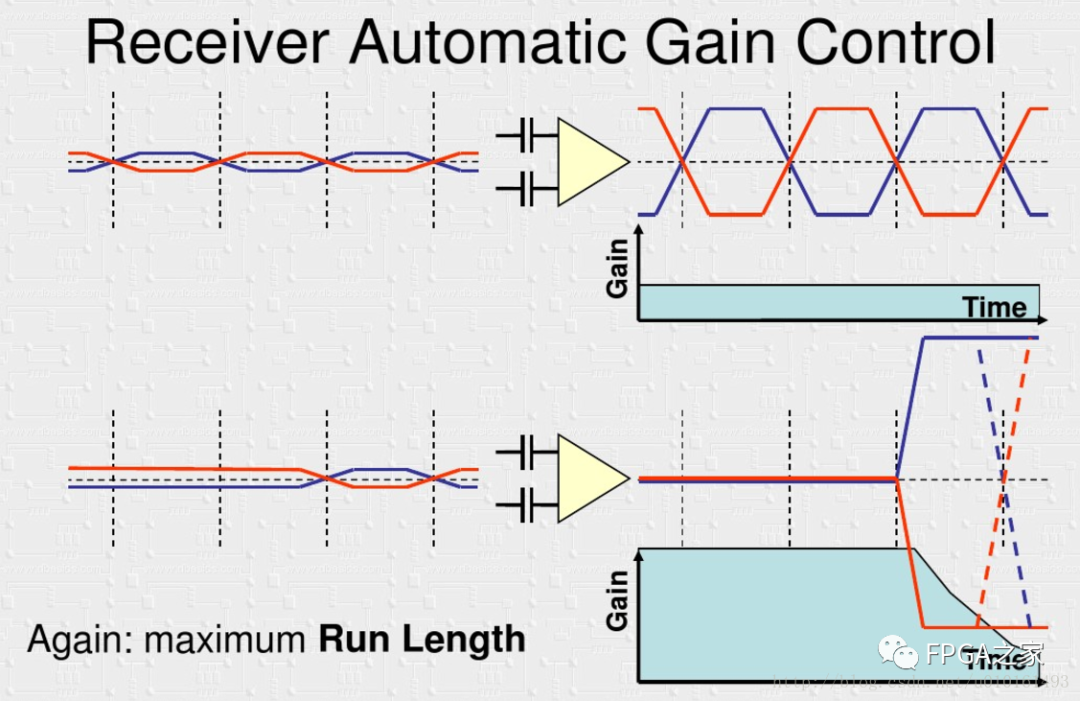
AGC自动增益控制需要交流分量才能实现放大
4 comma码,K码
在serdes上面的高速串行流在接收端需要重新串并转化成多字并行,怎么找到字的边界进行对齐呢?这就需要一个特殊的序列,这就是comma码。 传输过程中需要的一些控制,最好不要和数据冲突了,这就是K码。基于以上四个原因,就有了8b10b,64b66b的出现。
三 、8b10b编码
8b10b编码一句话概括起来就是把8bit的数据变成10bit的数据,其中所有1或0的个数不会超过6个,并且连续的1或0的个数不会超过4个。这样原本1024的汉明空间编码后就大大减小了。其中有256个data码和12K码控制码。这样数据和控制码不会重合。
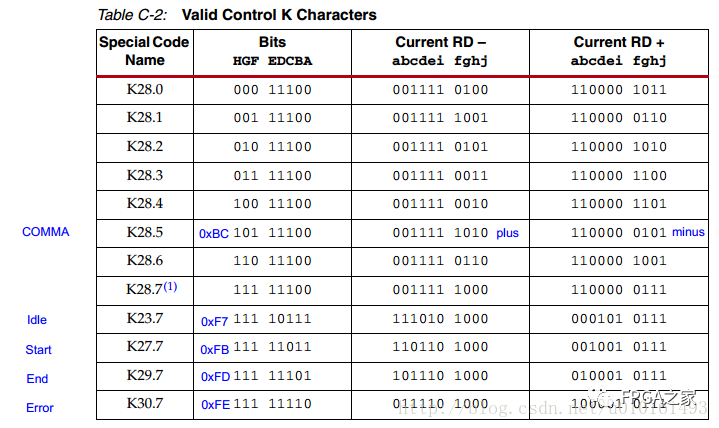
其中K28.1,K28.5,K28.7可以作为分隔码,也叫comma码,用于接收端在串行的数据流中找到字节边界。常用的K28.5即0xBC。因为正常传输的数据也可能有0xBC,怎么区分呢?是有一根单独的控制线,tx_is_K在传输K码时拉高,在传数据时拉低,去控制8b10b的编码模块到底是编码成数据还是控制K码。
四、Xilinx Serdes的几个细节
1.COMMA码使用
K28.5,0xBC,+0101_111100,-1010_000011; 为检测字节分割。 使用其它K码,作为帧开始,帧结束,时钟修正和数据对齐。
2.多字节处理
在数据率比较高的时候,外部位宽可能是2字(16位)或者4字(32位)。这是如果收发双方不约定好在高低哪个字发送comma码,这时是可以检测字边界,但接收端就会出现高低字节翻转的情况。在任意对于单COMMA的数据对齐,选择偶数字节对齐。发送的时候 0x5ABC->2’b01。
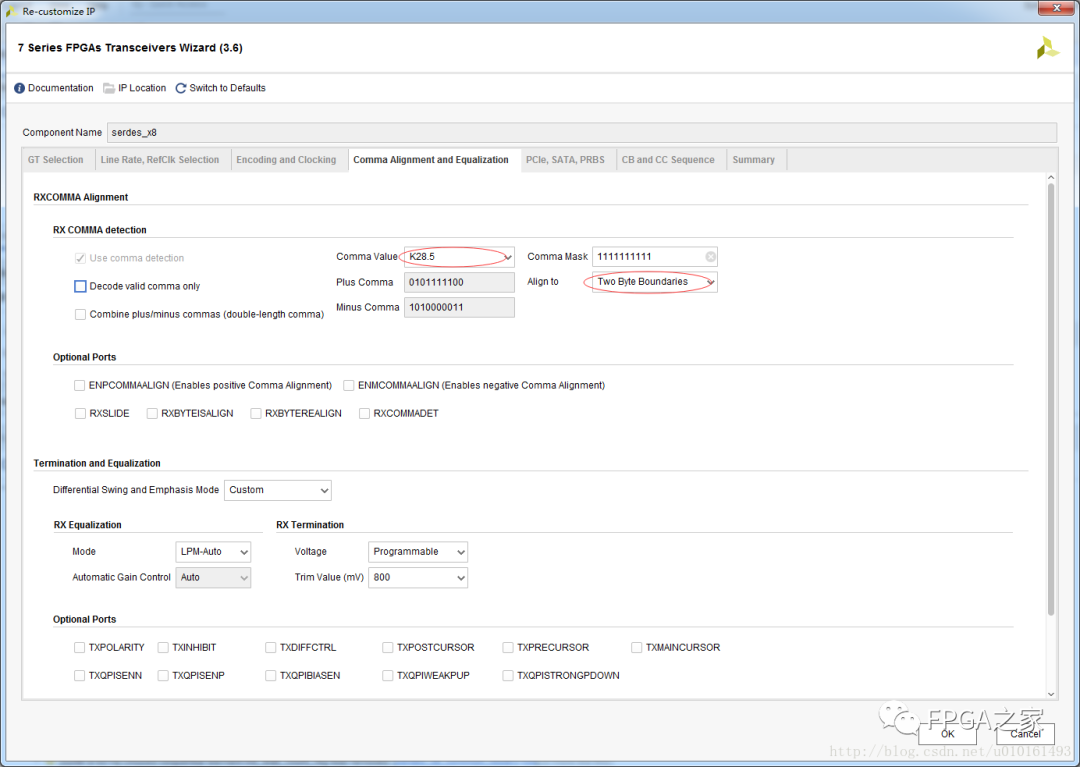
也可以选择发送组合的comma码,就是把NP的comma拼接起来发送,这样接收端就检测16bit的双字边界。也可以避免上面的情况出现。发送的时候0xBCBC->2’b11

注意:decode valid comma only不要选,因为还可能发送其他的K码用于控制。反正8b10b是用的收发器硬核的资源,不用白不用。
3、环回设置:
1.“000”:正常模式
2.“001”:近端PCS环回
3.“010”:近端PMA环回
4.“100”:远端PMA环回
5.“110”:远端PCS环回
注意Xilinx例化的example的文件中配置的环回是预留环回接口的意思,仍然需要另外手动配置。
4、fsm_down状态机
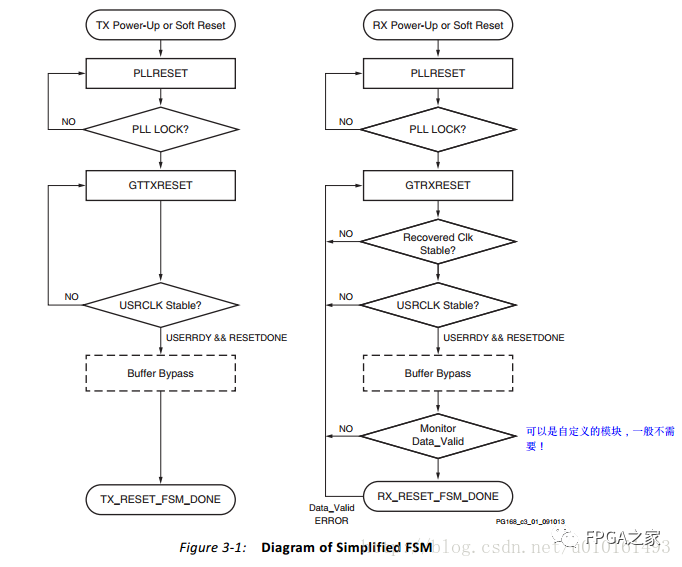
在Monitor Data_Valid模块,是用的frame_check的正确的信号,校验失败会导致复位GTrxreset。可以不用这个反馈,直接置1。需要手动改一下。
原文标题:xilinx 高速收发器Serdes深入研究
文章出处:【微信公众号:FPGA之家】欢迎添加关注!文章转载请注明出处。
审核编辑:汤梓红
-
收发器
+关注
关注
10文章
3454浏览量
106222 -
信号
+关注
关注
11文章
2804浏览量
77081 -
时钟
+关注
关注
11文章
1746浏览量
131775
原文标题:xilinx 高速收发器Serdes深入研究
文章出处:【微信号:zhuyandz,微信公众号:FPGA之家】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
FPGA设计之GTP、GTX、GTH以及GTZ四种串行高速收发器
高速电路中过孔设计注意事项
FPGA高速收发器设计要遵循哪些原则?


MAX14820/MAX14821传感器/执行器收发器的特殊注意事项





 工商网监
工商网监
评论