 python多线程和多进程的对比
python多线程和多进程的对比
1. 基本概念
在开始讲解理论知识之前,先过一下几个基本概念。虽然咱是进阶教程,但我也希望写得更小白,更通俗易懂。
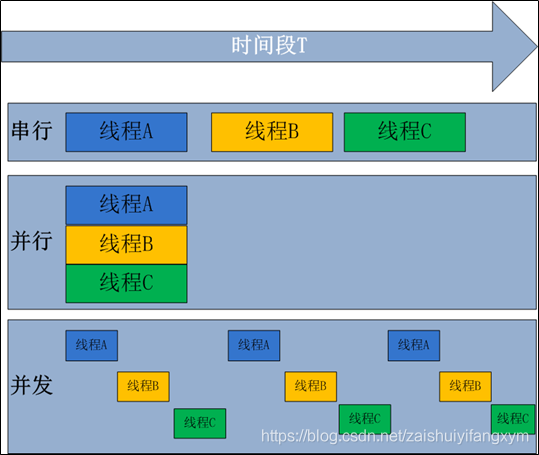
串行:一个人在同一时间段只能干一件事,譬如吃完饭才能看电视;
并行:一个人在同一时间段可以干多件事,譬如可以边吃饭边看电视;
在Python中,多线程 和 协程 虽然是严格上来说是串行,但却比一般的串行程序执行效率高得很。 一般的串行程序,在程序阻塞的时候,只能干等着,不能去做其他事。就好像,电视上播完正剧,进入广告时间,我们却不能去趁广告时间是吃个饭。对于程序来说,这样做显然是效率极低的,是不合理的。
虽然 多线程 和 协程 已经相当智能了。但还是不够高效,最高效的应该是一心多用,边看电视边吃饭边聊天。这就是我们的 多进程 才能做的事了。
2. 单线程VS多线程VS多进程
文字总是苍白无力的,不如用代码直接来测试一下。
开始对比之前,首先定义四种类型的场景
- CPU计算密集型
- 磁盘IO密集型
- 网络IO密集型
- 【模拟】IO密集型
为什么是这几种场景,这和多线程 多进程的适用场景有关。结论里,我再说明。
# CPU计算密集型
def count(x=1, y=1):
# 使程序完成150万计算
c = 0
while c < 500000:
c += 1
x += x
y += y
# 磁盘读写IO密集型
def io_disk():
with open("file.txt", "w") as f:
for x in range(5000000):
f.write("python-learning\n")
# 网络IO密集型
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36'}
url = "https://www.tieba.com/"
def io_request():
try:
webPage = requests.get(url, headers=header)
html = webPage.text
return
except Exception as e:
return {"error": e}
# 【模拟】IO密集型
def io_simulation():
time.sleep(2)
比拼的指标,我们用时间来考量。时间耗费得越少,说明效率越高。
为了方便,使得代码看起来,更加简洁,我这里先定义是一个简单的 时间计时器 的装饰器。 如果你对装饰器还不是很了解,也没关系,你只要知道它是用于 计算函数运行时间的东西就可以了。
def timer(mode):
def wrapper(func):
def deco(*args, **kw):
type = kw.setdefault('type', None)
t1=time.time()
func(*args, **kw)
t2=time.time()
cost_time = t2-t1
print("{}-{}花费时间:{}秒".format(mode, type,cost_time))
return deco
return wrapper
第一步,先来看看单线程的
@timer("【单线程】")
def single_thread(func, type=""):
for i in range(10):
func()
# 单线程
single_thread(count, type="CPU计算密集型")
single_thread(io_disk, type="磁盘IO密集型")
single_thread(io_request,type="网络IO密集型")
single_thread(io_simulation,type="模拟IO密集型")
看看结果
【单线程】-CPU计算密集型花费时间:83.42633867263794秒
【单线程】-磁盘IO密集型花费时间:15.641993284225464秒
【单线程】-网络IO密集型花费时间:1.1397218704223633秒
【单线程】-模拟IO密集型花费时间:20.020972728729248秒
第二步,再来看看多线程的
@timer("【多线程】")
def multi_thread(func, type=""):
thread_list = []
for i in range(10):
t=Thread(target=func, args=())
thread_list.append(t)
t.start()
e = len(thread_list)
while True:
for th in thread_list:
if not th.is_alive():
e -= 1
if e <= 0:
break
# 多线程
multi_thread(count, type="CPU计算密集型")
multi_thread(io_disk, type="磁盘IO密集型")
multi_thread(io_request, type="网络IO密集型")
multi_thread(io_simulation, type="模拟IO密集型")
看看结果
【多线程】-CPU计算密集型花费时间:93.82986998558044秒
【多线程】-磁盘IO密集型花费时间:13.270896911621094秒
【多线程】-网络IO密集型花费时间:0.1828296184539795秒
【多线程】-模拟IO密集型花费时间:2.0288875102996826秒
第三步,最后来看看多进程
@timer("【多进程】")
def multi_process(func, type=""):
process_list = []
for x in range(10):
p = Process(target=func, args=())
process_list.append(p)
p.start()
e = process_list.__len__()
while True:
for pr in process_list:
if not pr.is_alive():
e -= 1
if e <= 0:
break
# 多进程
multi_process(count, type="CPU计算密集型")
multi_process(io_disk, type="磁盘IO密集型")
multi_process(io_request, type="网络IO密集型")
multi_process(io_simulation, type="模拟IO密集型")
看看结果
【多进程】-CPU计算密集型花费时间:9.082211017608643秒
【多进程】-磁盘IO密集型花费时间:1.287339448928833秒
【多进程】-网络IO密集型花费时间:0.13074755668640137秒
【多进程】-模拟IO密集型花费时间:2.0076842308044434秒
3. 性能对比成果总结
将结果汇总一下,制成表格。
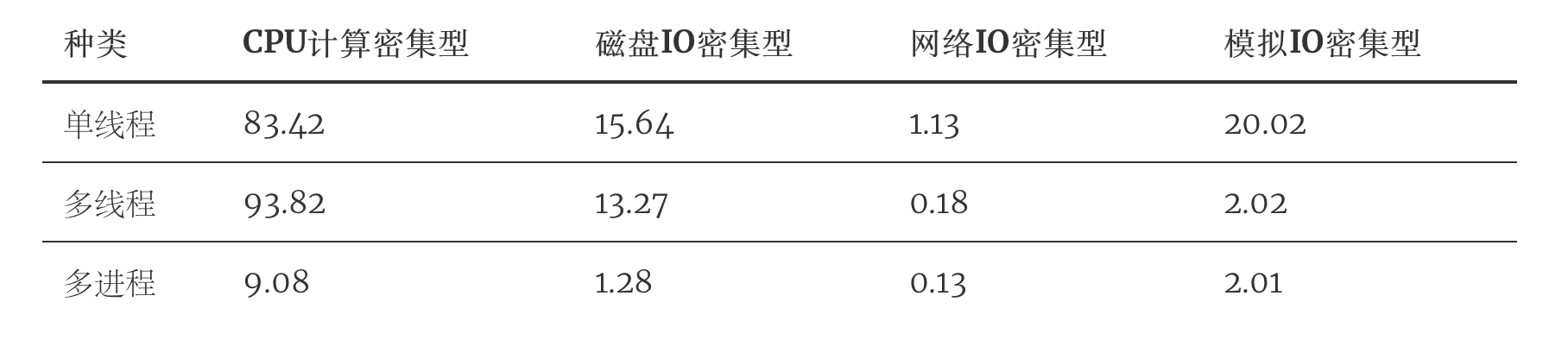
我们来分析下这个表格。
首先是CPU密集型,多线程以对比单线程,不仅没有优势,显然还由于要不断的加锁释放GIL全局锁,切换线程而耗费大量时间,效率低下,而多进程,由于是多个CPU同时进行计算工作,相当于十个人做一个人的作业,显然效率是成倍增长的。
然后是IO密集型,IO密集型可以是磁盘IO,网络IO,数据库IO等,都属于同一类,计算量很小,主要是IO等待时间的浪费。通过观察,可以发现,我们磁盘IO,网络IO的数据,多线程对比单线程也没体现出很大的优势来。这是由于我们程序的的IO任务不够繁重,所以优势不够明显。
所以我还加了一个「模拟IO密集型」,用sleep来模拟IO等待时间,就是为了体现出多线程的优势,也能让大家更加直观的理解多线程的工作过程。单线程需要每个线程都要sleep(2),10个线程就是20s,而多线程,在sleep(2)的时候,会切换到其他线程,使得10个线程同时sleep(2),最终10个线程也就只有2s.
可以得出以下几点结论
单线程总是最慢的,多进程总是最快的。
多线程适合在IO密集场景下使用,譬如爬虫,网站开发等
多进程适合在对CPU计算运算要求较高的场景下使用,譬如大数据分析,机器学习等
多进程虽然总是最快的,但是不一定是最优的选择,因为它需要CPU资源支持下才能体现优势
审核编辑:符乾江
-
多线程
+关注
关注
0文章
278浏览量
20018 -
python
+关注
关注
56文章
4799浏览量
84812
发布评论请先 登录
相关推荐
Python中多线程和多进程的区别
从多线程设计模式到对 CompletableFuture 的应用

bootloader开多线程做引导程序,跳app初始化后直接进hardfualt,为什么?
鸿蒙APP开发:【ArkTS类库多线程】TaskPool和Worker的对比
鸿蒙原生应用开发-ArkTS语言基础类库多线程TaskPool和Worker的对比(一)
java实现多线程的几种方式
python中5种线程锁盘点

线程是什么的基本单位 进程与线程的本质区别
分别使用多线程多进程协程+paramiko在华为交换机批量快速进行配置
线程、进程、多线程、多进程和多任务之间有何关系?





 工商网监
工商网监
评论