 CFI的基本概念
CFI的基本概念
伟林,中年码农,从事过电信、手机、安全、芯片等行业,目前依旧从事Linux方向开发工作,个人爱好Linux相关知识分享,个人微博CSDN pwl999,欢迎大家关注!
目录
1. 简介
1.1 控制流攻击历史 1.2 CFI的基本概念 1.3 CFI发展历史
2. Orig CFI
2.1 Windows CFG的实现
3. CCFIR
4. VTV
5. Kernel CFI
5.1 forward-edge protection CFI(Control-Flow Integrity) 5.2 backward-edge protection SCS(Shadow Call Stack) 5.3 Shared library support(Cross-DSO)
6. 利用硬件来提升CFI的效率
01 简介
➤ CFI: Control-Flow Integrity(控制流完整性)
➤ CFG: Control Flow Guard(Windows的CFI实现)
➤ CFG: Control-Flow Graph(控制流图)
➤ LTO: Link Time Optimization(链接时优化)
1.1 控制流攻击历史
控制流劫持是一种危害性极大的攻击方式,攻击者能够通过它来获取目标机器的控制权,甚至进行提权操作,对目标机器进行全面控制。当攻击者掌握了被攻击程序的内存错误漏洞后,一般会考虑发起控制流劫持攻击。
●shellcode
早期的攻击通常采用代码注入(shellcode)的方式,通过上载一段代码,将控制转向这段代码执行。
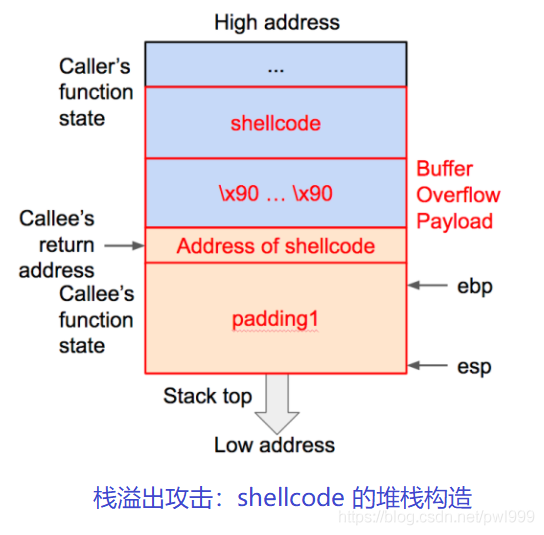
为了阻止这类攻击,后来的计算机系统中都基本上都部署了NX/DEP(Data Execution Prevention)机制,通过限定内存页不能同时具备写权限和执行权限,来阻止攻击者所上载的代码的执行。
●Return2libc/ROP
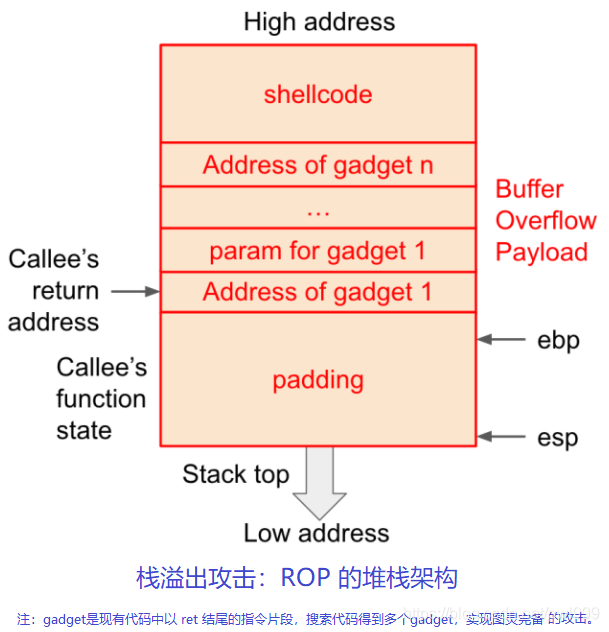
为了突破DEP的防御,攻击者又探索出了代码重用攻击方式,他们利用被攻击程序中的代码片段,进行拼接以形成攻击逻辑。代码重用攻击包括Return-to-libc、ROP(Return Oriented Programming)、JOP(Jump Oriented Programming)等。研究表明,当被攻击程序的代码量达到一定规模后,一般能够从被攻击程序中找到图灵完备的代码片段。
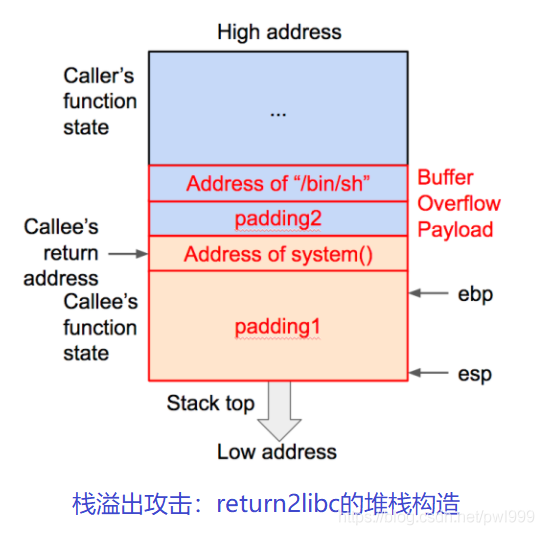
Return2libc/ROP利用return间接访问,绕过了NX/DEP访问。因为代码并不会直接在堆栈上执行,而只是根据堆栈中的地址,间接跳转到对应正常代码段执行。
● DOP
DOP(Data Oriented Programming)攻击。随着防护技术的发展,针对控制流的攻击变得愈发困难。而不通过劫持控制流,而是针对数据流来进行攻击的方式,如Non-control data(非控制数据)攻击虽然显示出了其潜在的危害性,但目前对针对数据流的攻击还知之甚少,长久以来该攻击手段可实现的攻击目标一直被认为是有限的。实际上,非控制数据攻击可以是图灵完备的,这就是DOP攻击。
类似于ROP,DOP攻击的实现也依赖于gadgets。但二者有以下两点不同:
1、DOP的gadgets只能使用内存来传递操作的结果,而ROP的gadgets可以使用寄存器。
2、DOP的gadgets必须符合控制流图(CFG),不能发生非法的控制流转移,而且无需一个接一个的执行。而ROP的gadgets必须成链,顺序执行。
● CFI
为了应对这些新型的控制流劫持攻击,加州大学和微软公司于2005年提出了控制流完整性(Control Flow Integrity, CFI)的防御机制。其核心思想是限制程序运行中的控制转移,使之始终处于原有的控制流图所限定的范围内。具体做法是通过分析程序的控制流图,获取间接转移指令(包括间接跳转、间接调用、和函数返回指令)目标的白名单,并在运行过程中,核对间接转移指令的目标是否在白名单中。控制流劫持攻击往往会违背原有的控制流图,CFI使得这种攻击行为难以实现,从而保障软件系统的安全。
CFI从实现角度上,被分为细粒度和粗粒度两种。细粒度CFI严格控制每一个间接转移指令的转移目标,这种精细的检查,在现有的系统环境中,通常会引入很大的开销。而粗粒度CFI则是将一组类似或相近类型的目标归到一起进行检查,以降低开销,但这种方法会导致安全性的下降。
CFI对非控制数据的攻击无能为力,但是这不妨碍我们详细研究CFI的实现原理。
1.2 CFI的基本概念
了解CFI(Control-Flow Integrity),需要从CFG(Control-Flow Graph)讲起。这里的CFG是基于静态分析的用图的方式表达程序的执行路径(函数级别,非指令级别?):
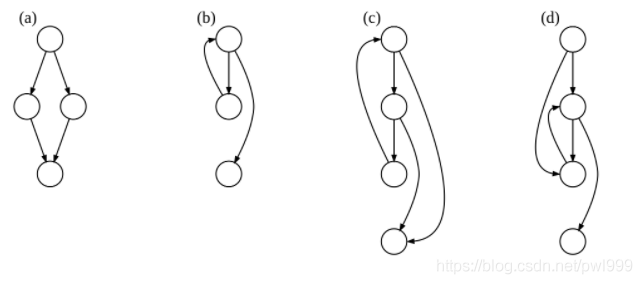
CFI并不会检测CFG中所有的边,为了降低开销受检测的边应该越少越好。因此在CFG中只考虑将可能受到攻击的间接call、间接jmp和ret指令作为边。
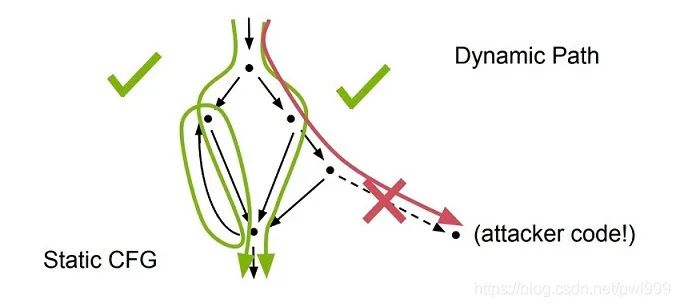
如上图,绿色的静态控制流路径并不易受到攻击,红色的动态控制流路径容易受到攻击。静态路径就是直接跳转,动态路径就是间接跳转的路径。
●直接跳转和间接跳转
直接跳转指令的示例如下所示:
1| CALL 0x1060000F
在程序执行到这条语句时,就会将指令寄存器的值替换为0x1060000F。这种在指令中直接给出跳转地址的寻址方式就叫做直接转移。在高级语言中, 像if-else,静态函数调用这种跳转目标往往可以确定的语句就会被转换为直接跳转指令。
间接跳转指令则是使用数据寻址方式间接的指出转移地址,比如:
1| JMP EBX
执行完这条指令之后, 指令寄存器的值就被替换为EBX寄存器的值。它的转换对象为作为回调参数的函数指针等动态决定目标地址的语句。
●前向转移(forward)和后向转移(backward)
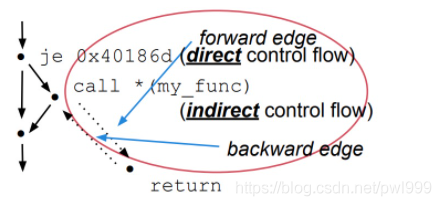
将控制权定向到程序中一个新位置的转移方式, 就叫做前向转移, 比如jmp和call指令。
而将控制权返回到先前位置的就叫做后向转移, 最常见的就是ret指令。
将以上两种分类方式结合起来:
前向转移指令call和jmp根据寻址方式不同, 又可以分为直接jmp, 间接jmp,直接call,间接call四种。
后向转移指令ret没有操作数,它的目标地址计算是通过从栈中弹出的数来决定的。正因为ret指令的特性,引发了一系列针对返回地址的攻击。
CFI(Control-Flow Integrity)关注的就是间接jmp、间接call、ret这几种指令控制流的完整性。
1.3 CFI发展历史
Control-Flow-Integrity这篇文章详细的描述了CFI的发展历史。
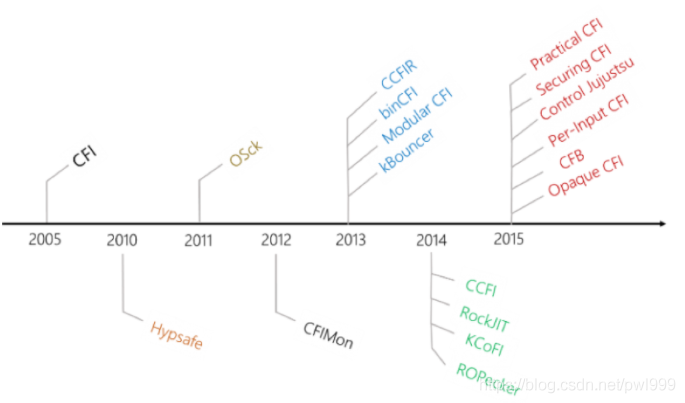
上图是CFI技术发展的历史路线图,其中代表性的有四种CFI技术,下图是这四种技术在各个维度的一个比较:
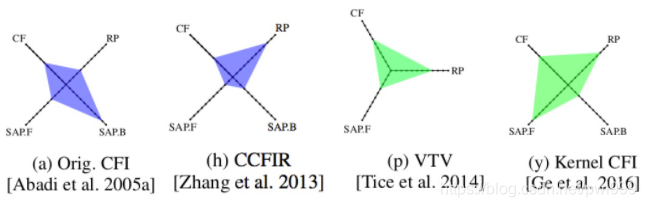
上图,是各个CFI技术在安全性能四个维度的得分:
●一个是支持的控制流传输方案,比如前向后向、间接返回等等,用CF表示。
●二是性能数值,用1-10来区别,10为最高分,用RP来表示。
●SAP.F是对前向控制流的静态分析精度,
●SAP.B是对后向控制流的分析精度。
02 Orig CFI
原始CFI技术都来源于这篇文章:Control-Flow Integrity Principles, Implementations, and Applications。
这种技术的思想就是在就是间接jmp、间接call、ret这几种指令的控制流中插桩,在间接跳转之前判断跳转地址是否合法。
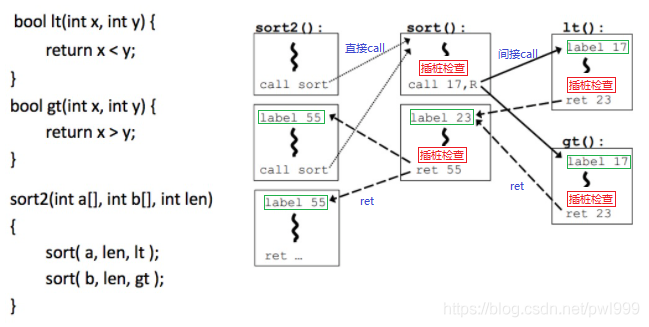
用上图来解释,利用左侧的代码生成了右侧的CFG控制流图。其中的直接call路径是不用关注的,针对间接call和ret指令的控制流路径,插入代码进行判断:
1、在间接call和ret的目标地址插入一个独有的label id。
2、在间接call和ret指令之前插入一段桩代码,来检查目的地址的id是否合法。合法才能间接跳转,不合法则出错返回。
3、还约定如果指向两个目标地址的边拥有相同的源集合的话,那么这两个目标地址就是等价的,等价的目标用同一label表示。所以我们看到两个相同的label 55和两个相同的label 17。这就是一种粗粒度的CFI,它将多个不同的目标地址合在一起减少需要检测目标地址的数量。为了降低性能开销,是以牺牲安全性为前提的。
下图是上述理论在x86上的一个具体实现:
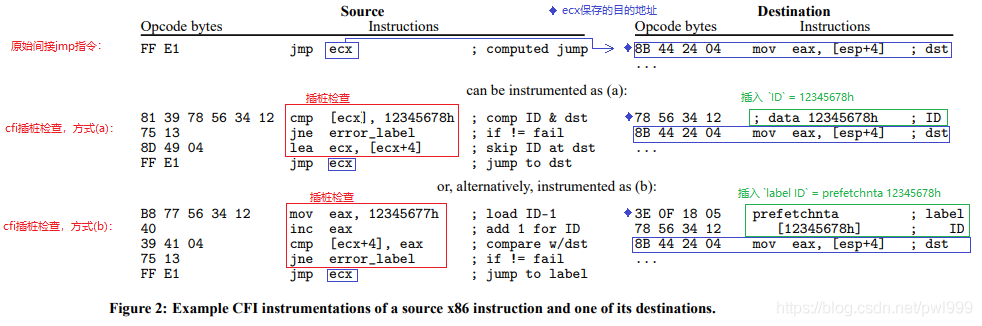
●原始状态:ecx保存了目的地址,jmp ecx间接跳转到目的地址执行
●插桩方式(a):首先在目的地址插入一个4字节ID 12345678h,然后在jmp跳转前插入一段桩函数判断,判断目的地址的值是否为12345678h。不合法则出错处理,合法则间接跳转到[ecx + 4]地址执行原来的目的指令。
●插桩方式(b):在方式(a)的基础上做了优化,首先在目的地址插入一个4字节的lable指令prefetchnta + 4字节ID 12345678h,然后在jmp跳转前插入一段桩函数判断,判断[ecx + 4]地址的值是否为12345678h。不合法则出错处理,合法则间接跳转到[ecx]地址执行label ID指令。注意这里的技巧是判断合法后,还是跳转到ecx原地址,但是这时这个地址上存储的是label ID指令,这条命令没啥副作用,紧接着才会继续执行原有的命令。
下图是间接jmp、ret指令路径,都被cfi插桩的情况:

CFI确保运行时执行沿着给定的CFG进行,例如,保证典型功能的执行始终从头开始,并从头到尾进行。因此,CFI可以提高任何基于CFG的技术的可靠性(例如,增强现有技术以防止缓冲区溢出和入侵检测[32,58])。下面介绍基于CFI的其他应用,内联参考监视器IRM(Inlined Reference Monitors)、SFI(Software Fault Isolation)、软件内存访问控制SMAC(Software Memory Access Control),我们在此介绍它们。它还显示了如何依靠SMAC或标准x86硬件支持来加强CFI实施。
下图还展示了一个影子调用堆栈(shadow call stack)的原理,这是ret路径上的另一种cfi保护形式:
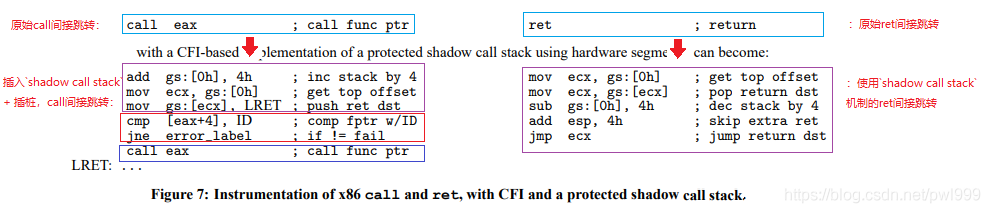
●shadow call stack 在 ret路径上不再使用判断id是否正确的方式,而是把返回地址在另外一个堆栈另存了一份,这样栈溢出漏洞无法覆盖,就算堆栈溢出但是函数还是返回到原来的调用位置。
●在函数调用前的时候,把返回地址备份到shadow call stack。
●在函数返回前,从shadow call stack中弹出备份的返回地址,废弃掉原堆栈中的返回地址,这样ret返回地址的安全性多了一层保障。
实现CFI,三个假设成立至关重要。这三个假设是:
● UNQ. 唯一ID:在CFI检测之后,除了ID和ID检查之外,选择为ID的位模式不得出现在代码存储器中的任何位置。通过使ID足够大(例如32位,对于合理大小的软件)并且通过选择ID使得它们不与软件的其余部分中的操作码字节冲突,可以容易地实现该属性。
● NWC. 不可写代码:程序必须无法在运行时修改代码内存。否则,攻击者可能能够绕过CFI,例如通过覆盖ID检查。除了在加载动态库和运行时代码生成期间,NWC在大多数当前系统中已经是正确的。
● NXD. 不可执行数据:程序必须不能像执行代码那样执行数据。否则,攻击者可能会导致执行标有预期ID的数据。最新的x86处理器上的硬件支持NXD,Windows XP SP2使用此支持来强制分离代码和数据[Microsoft Corporation 2004]。NXD也可以用软件实现[PaX Project 2004]。NXD本身(没有CFI)阻止了一些攻击,但不适于那些利用预先存在的代码的攻击,例如“jump-to-libc”攻击。
2.1 Windows CFG的实现
Windows利用以上思想建立了自己的CFI防护机制CFG(Control Flow Guard)。在Win10安全特性之执行流保护、绕过Windows Control Flow Guard思路分享等文章中有对CFG的实现原理进行过描述。
以win10 preview 9926中IE11的Spartan html解析模块为例,看一下CFG的具体情况:
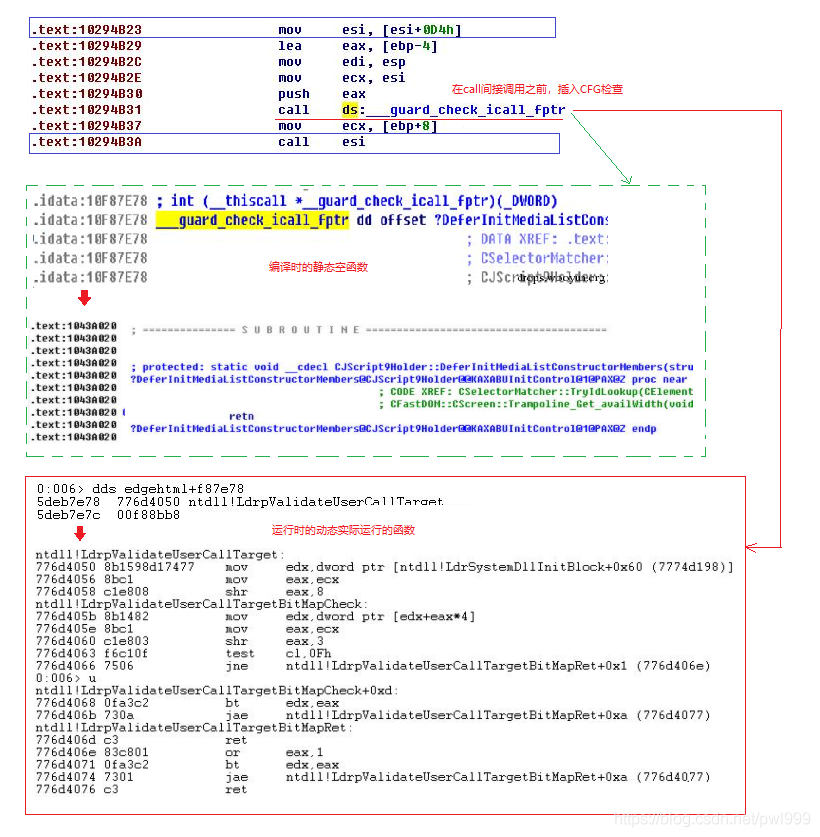
最终实际运行的CFG检查函数为ntdll!LdrpValidateUserCallTarget(),其检测过程如下:
1、首先从LdrSystemDllInitBlock+0x60处读取一个位图(bitmap),这个位图表明了哪些函数地址是有效的。通过间接调用的函数地址的高3个字节作为一个索引,获取该函数地址所在的位图的一个DWORD值,一共32位,证明1位代表了8个字节,但一般来说间接调用的函数地址都是0x10对齐的,因此一般奇数位是不使用的。
2、通过函数地址的高3个字节作为索引拿到了一个所在的位图的DWORD值,然后检查低1字节的0-3位是否为0,如果为0,证明函数是0x10对齐的,则用3-7bit共5个bit就作为这个DWORD值的索引,这样通过一个函数地址就能找到位图中所对应的位了。如果置位了,表明函数地址有效,反之则会触发异常。
对win CFG的防护思路没有完全理解透彻,反正原理就是根据跳转的目的地址去查bitmap表来确定是否合法。
03 CCFIR
在CFI被提出后过了很长时间都没有被广泛应用到实际生产中去,主要原因还是插桩引起的开销过大。因此在2013年又提出了CCFIR,在同一年提出的还有binCFI,ModularCFI等等,但CCFIR是非常典型的一个实现。
与上面我们所讲的机制将目标集合按照指向边的源集合是否相同来划分不一样,CCFIR更加简洁的将目标集合划分为了三类:
所有的间接call和jmp指令的目标被归为一类,称为函数指针;
ret指令的目标被归为两类,一类是敏感库函数(比如libc中的额system函数),另一类是普通函数。
下面我们以下图中的例子来说明CCFIR的工作原理:
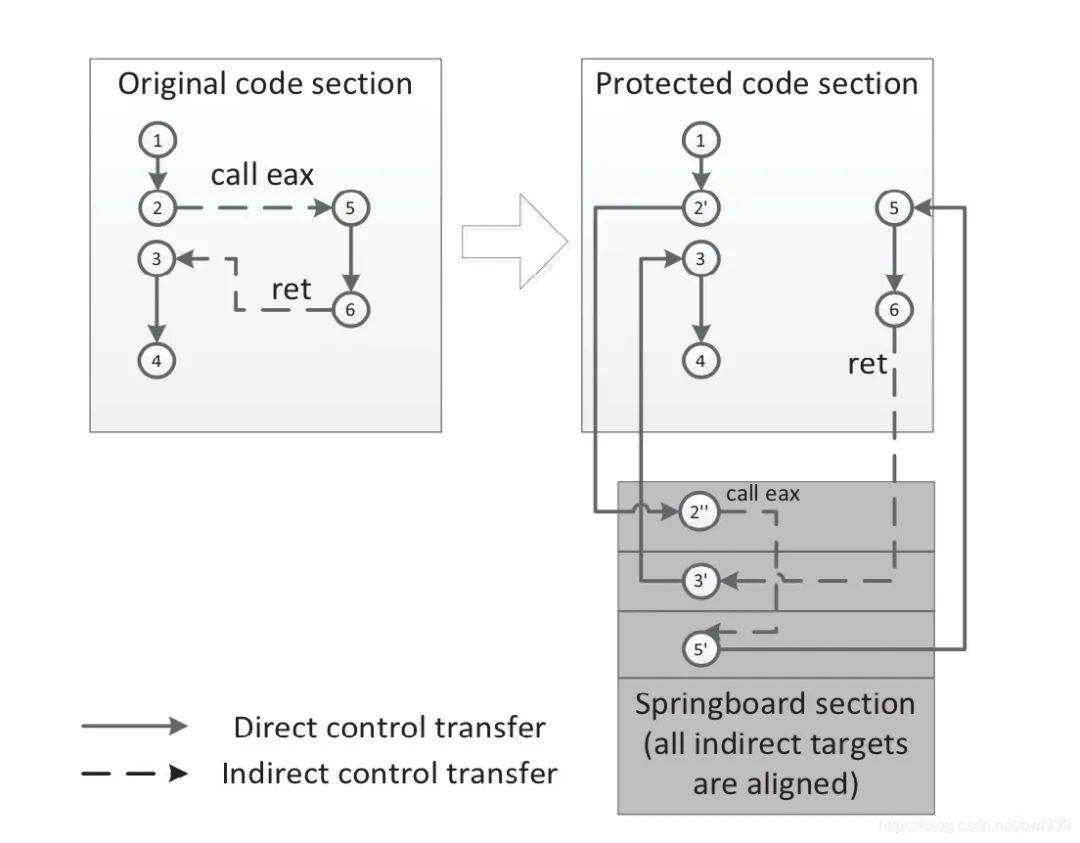
左边是原始的控制流,右边是CCFIR机制下的控制流。CCFIR提出了通过Springboard段(下方灰色部分)存放有效间接转移目标的地址,在这段控制流中,5和3节点节点分别是call eax指令和ret指令这两个间接转移指令的目标地址,因此都会被存在Springboard段中。在程序执行到节点2’时,会检测接下来的跳转地址是否在Springboard段中,是则跳转,否则出错,从节点6跳转到3也是一样。
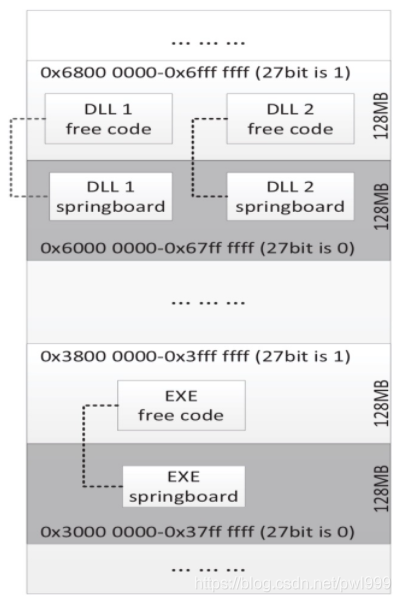
Springboard段的内存布局如上图所示,通过将某一位设置成0/1来区分普通段和Springboard段。这样在跳转检测时检查某一个目标是否在Springboard段,只要检测某一位的值就可以了。
再进一步扩展,由于目标地址主要被分为三类,那么这三类又可以通过几位的不同来区分,如下图。第27bit为0则表示是Springboard段,第3位为1则属于函数指针,为0属于ret地址,并通过26位区分是敏感函数地址还是普通函数地址。
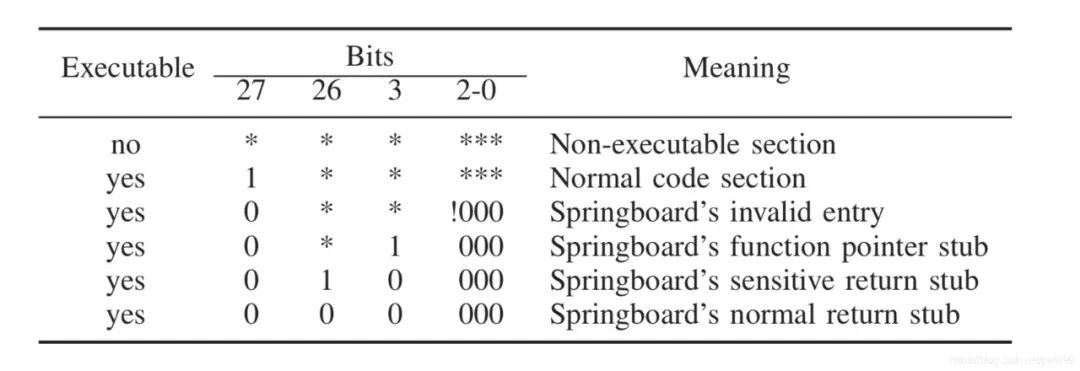
CCFIR的主要贡献在于它降低了CFI机制的开销,希望能将CFI投入实际使用中去。
04 VTV
2014年 Google 间接函数调用检查(第6篇文章)。随着对堆栈的保护越来越完善,出现了很多基于非堆栈的前向转移攻击,尤其是call指令。例如利用UAF漏洞覆盖vtable指针等等。这篇文章的主要贡献不是提出了什么新的机制,而是将CFI真正用到了生产编译器中,仅针对于前向转移。以下是主要工作:
Vtable Verification (VTV), in GCC 4.9,主要是对vtable调用进行检测,VTV在每个调用点验证用于虚拟调用的vtable指针的有效性。
Indirect Function Call Checker (IFCC), in LLVM。它通过为间接调用目标生成跳转表并在间接调用点添加代码来转换函数指针来保护间接调用,从而确保它们指向跳转表条目。任何未指向相应表的函数指针都被视为CFI违规。- - Indirect Function Call Sanitizer (FSan), in LLVM是一个可选的间接调用检查器。
LLVM Clang Control Flow Integrity Design Documentation一文详细的描述了Forward-Edge CFI for Virtual Calls的实现原理。
05 Kernel CFI
Linux 内核的代码量比较少但是内核权限更大,一旦被攻击会更加致命,所以kernel也需要拥有自己CFI防护方案。
在Andriod上google投入了大量精力来防止代码重用攻击(ROP),主要的防护思路是通过基于编译器的安全缓解措施:
● 代码重用攻击(ROP)利用内核的常用方法是使用错误来覆盖存储在内存中的函数指针,例如存储了回调函数的指针,或已被推送到堆栈的返回地址。这允许攻击者执行任意内核代码来完成利用,即使他们不能注入自己的可执行代码。这种获取代码执行能力的方法在内核中特别受欢迎,因为它使用了大量的函数指针,以及使代码注入更具挑战性的现有内存保护机制。
●CFI 尝试通过添加额外的检查来确认内核控制流停留在预先设计的版图中,以便缓解这类攻击。尽管这无法阻止攻击者利用一个已存在的 bug 获取写入权限,从而更改函数指针,但它会严格限制可被其有效调用的目标,这使得攻击者在实践中利用漏洞的过程变得更加困难。
Google 的 Pixel 3 将是第一款在内核中实施 LLVM 前端控制流完整性(CFI)的设备,已经实现了 Android 内核版本 4.9 和 4.14 中对 CFI 的支持。
Android 内核控制流完整性和CFI in Android Kernel Security介绍了Android下实现kernel CFI的大概情况。
Control Flow Integrity (CFI) in the Linux kernel和LLVM Clang Control Flow Integrity Design Documentation介绍了Kernel CFI的详细实现原理。
5.1forward-edge protection
CFI(Control-Flow Integrity)
Kernel CFI 前向边沿的防护。
1、将前向间接跳转的目的地址搜集到一起组成一张表,在跳转前判断目的地址的合法性。因为合法的目的地址都是实际存在的函数,所以表的大小是有限的。当然也不会把所有的目的函数都集中到一张表里,会根据函数的原型把原型相同的函数搜集到同一张表中。
函数原型一致:
1| int do_fast_path(unsigned long, struct file *file) 2| int do_slow_path(unsigned long, struct file *file)
函数原型不一致:
1| void foo(unsigned long) 2| int bar(unsigned long)
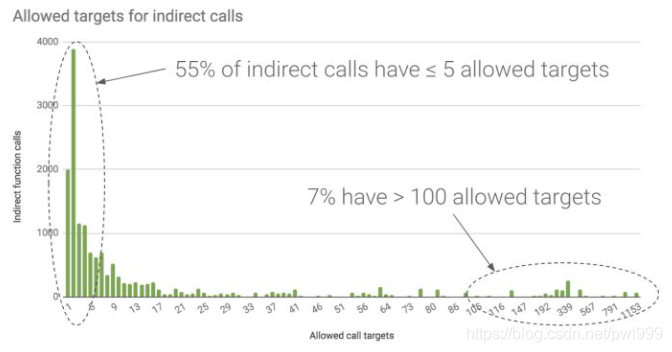
如上图根据google的研究统计,使用原型法来分类函数。LLVM 的 CFI 将 55% 的间接调用限制为最多 5 个可能的目标,80% 限制为最多 20 个目标。
因为linux kernel有时并未严格遵守函数指针和函数原型绝对一致的约定,所以在开启CFI特性时需要修复这类问题。
2、在链接时进行间接调用目的函数表的分类和创建,以及调用前的插桩。这要求连接器具有LTO功能。
llvm的CFI模块会用LTO来决定所有valid call targets,必须使用llvm的整体的汇编器来进行inline汇编,必须使用LTO-aware的链接器,比如说 GNU gold linker或者是llvm的ld。
下图为LLVM的LTO原理简介:
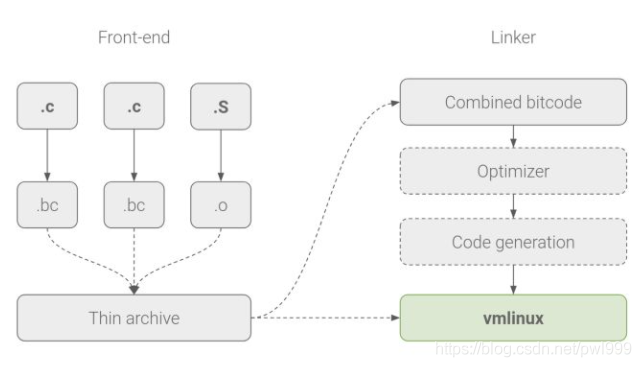
为了确定每个间接分支的所有有效调用目标,编译器需要立即查看所有内核代码。传统上,编译器一次处理单个编译单元(源代文件),并将目标文件合并到链接器。LLVM 的 CFI 要求使用 LTO,其编译器为所有 C 编译单元生成特定于 LLVM 的 bitcode,并且 LTO 感知链接器使用 LLVM 后端来组合 bitcode,并将其编译为本机代码。
几十年来,Linux 一直使用 GNU 工具链来汇编,编译和链接内核。虽然我们继续将 GNU 汇编程序用于独立的汇编代码,但 LTO 要求我们切换到 LLVM 的集成汇编程序以进行内联汇编,并将 GNU gold 或 LLVM 自己的 lld 作为链接器。在巨大的软件项目上切换到未经测试的工具链会导致兼容性问题,我们已经在内核版本 4.9 和 4.14 的 arm64 LTO 补丁集中解决了这些问题。
3、具体实例
实例的c语言代码:(action()间接调用,可以调用do_simple()或者do_fancy())
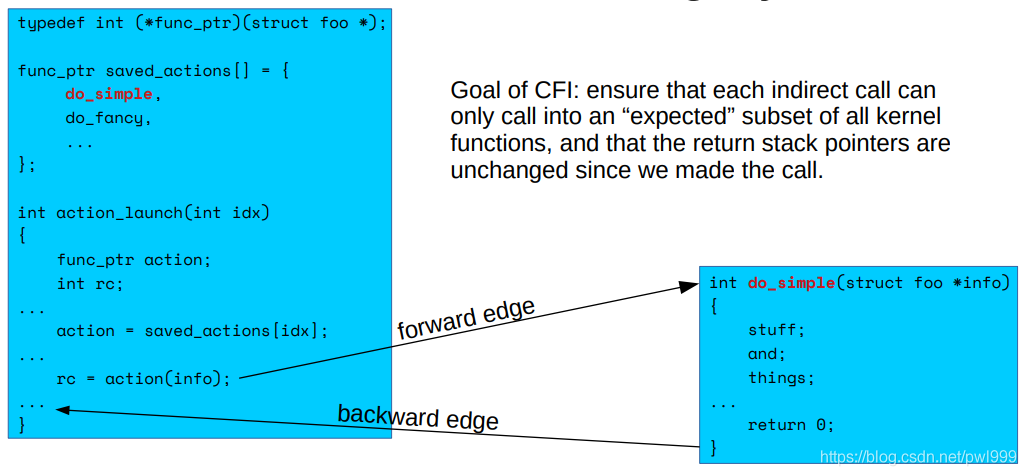
对应的汇编代码如下:
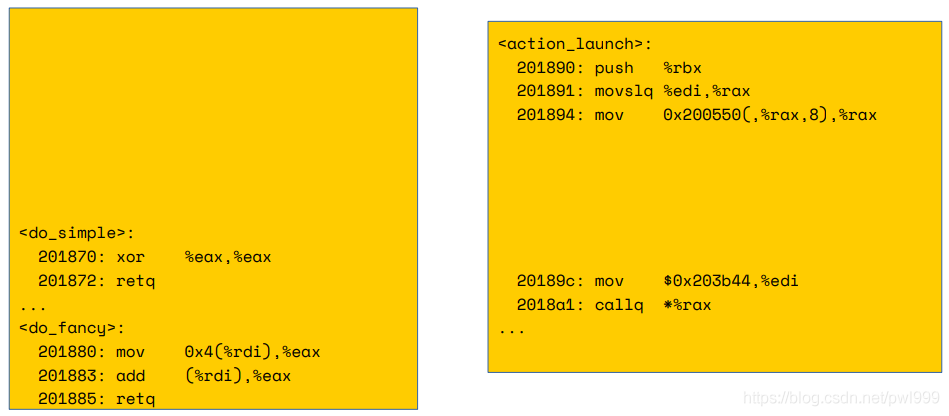
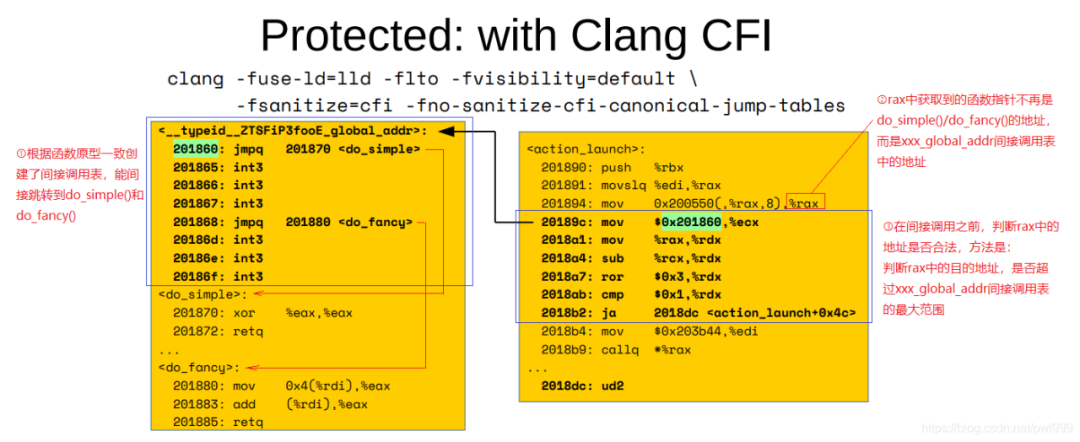
开启cfi保护以后的汇编代码:
5.2
backward-edgeprotectioSCS(Shadow Call Stack
5.2 backward-edge protectioSCS
(Shadow Call Stack)

Kernel CFI 后向边沿,使用影子调用堆栈的方式来防护。
● 方式1:专用寄存器用于单独的返回堆栈:“影子调用堆栈”
x86已经不使用这种方式,因为它运行缓慢且存在竞争条件。arm64可以为所有影子堆栈操作保留寄存器(x18),阴影堆栈的位置需要保密。
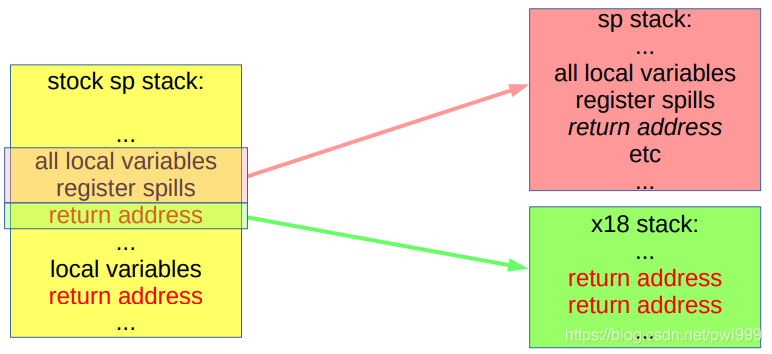
结果出现在两个堆栈寄存器中:sp和未缓存的x18仅将来自影子堆栈(由x18指向)的返回地址(链接)寄存器的负载用于返回:
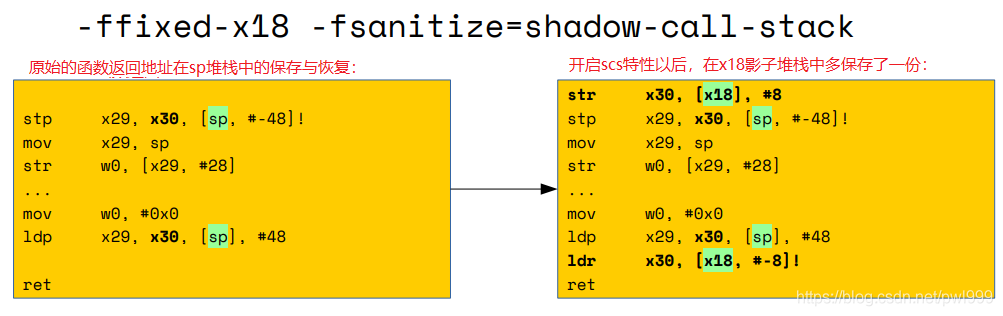
● 方式2:使用专属硬件完成(x86: CET, arm64:Pointer Authentication)
Intel CET: 基于硬件的只读影子调用堆栈。在调用和退出指令期间隐式使用否则为只读的影子堆栈。
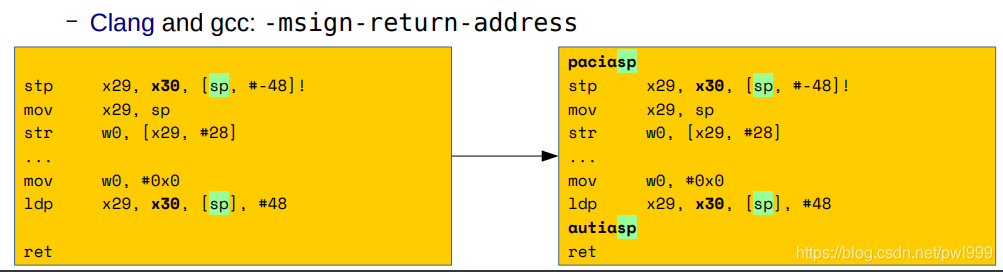
ARM v8.3a Pointer Authentication (“signed return address”)。新指令:paciasp 和 autiasp。Clang and gcc: -msign-return-address。
以下是使用arm PA实现的硬件影子堆栈:
5.3 Shared library support
(Cross—DSO)
因为内核是全解析的,所有不会有间接调用外部模块的情况。在用户态的共享库中还有间接调用还是穿越DSO模块。LLVM Clang Control Flow Integrity Design Documentation一文中详细描述了这些技术的实现。
06 利用硬件来提升CFI的效率
我们相信上述设计可以在硬件中有效地实现。添加到ISA的一条新指令将允许以每次检查更少的字节(更小的代码大小开销)执行前向CFI检查(可能会更有效)。当前的纯软件检测要求每个检查至少32字节(在x86_64上)。硬件指令可能小于12个字节。这样的指令将检查参数指针是否入站且已正确对齐,并且如果检查失败,它将捕获(在单片方案中)或调用慢路径函数(跨DSO方案)。对于硬件实现而言,位矢量查找可能太复杂了。
注意,这种硬件扩展将补充被叫方的支票,例如。英特尔ENDBRANCH。而且,CFI将从ENDBRANCH具有两个好处:a)精度和b)防止多态类型之间无效转换的能力。
为了能够在性能和防御方面取得更好的效果,一些研究着手于利用现有的硬件机制,来降低CFI的开销。
Vasilis Pappas提出利用硬件性能计数器,在运行时观察执行流的思路,该方法被称为kBouncer[10]。他们利用LBR(Last Branch Register)来捕获最近的16次跳转信息。具体做法是在敏感系统调用处,对捕获的16次跳转进行安全性判断,即return指令需要跳转到调用点的后继位置,indirect-call指令的目标是函数入口,其余跳转指令目标基本块长度不能全部少于20条指令。为了避免攻击者利用库函数调用来完成攻击,文章在所有的库函数调用点,来进行上述合法性检查。为了验证kBouncer的防御效果,作者对IE浏览器、Adobe Flash Player和Adobe Reader进行了实验(利用已知安全漏洞,组织ROP payload攻击这三种应用),实验结果表明该方法能够有效缓解ROP攻击。同时,该方法的性能开销低于~4%。
Yueqiang Chen等人设计了一种与kBouncer类似的方法,称作ROPecker[11],也是利用LBR捕获程序控制流的方式进行ROP攻击监测。但不同之处在于判断是否遭受ROP攻击的逻辑和触发监测的时机。1、判断逻辑:在运行时检测过去(利用LBR)和未来的执行流(模拟执行)中是否存在长gadget链(5个比较短的gadget),若存在,则认为这是一次ROP攻击。Gadget信息是通过静态分析二进制程序和共享库得到的。2、运行时监测是事件驱动的,具体时机是调用敏感系统调用和执行流跳出滑动窗口触发异常。ROPecker设计了一个滑动窗口,因为代码本身具有时间和空间的局部性,但是gadget链却是散列的,利用这一特性,系统保证该窗口内的gadget数目不足以构成一次ROP攻击,窗口内的代码设置可执行权限,窗口外的代码不可执行,当执行流跳出滑动窗口时,便会触发异常,进行运行时检测。该方法利用代码本身具有的时间和空间局部性,针对gadget链是散列的前提,提出了滑动窗口机制,使用事件驱动的检测方法,具有较高的准确性和高效性。为了验证该方法的安全性,ROPecker选取了有栈溢出的真实世界应用(Linux Hex-editer)进行攻防演练。实验结果证明,ROPecker能够有效的阻止ROP攻击。同时,SPEC CPU2006 benchmark显示了该方法的开销非常低(~2%)。
Yubin Xia等人设计的CFIMon[12],也是采用性能计数器来捕获程序执行流,并进行合法性判断。但他们采用的是BTB(Branch Trace Buffer),来捕获受保护程序运行过程中所有跳转指令的信息。BTB与LBR不同之处在于,BTB可以把程序整个执行过程中所有的跳转指令的历史信息都记录下来,LBR只能记录16条。但是BTB需要CPU向指定的一个缓冲区内写入跳转信息,当缓冲区满时,CPU会触发异常交给操作系统处理(将缓冲区内容写入文件中),LBR是循环的寄存器。使用BTB的程序性能明显比LBR性能低。CFIMon检查BTB的时机在两个阶段:一是当缓冲区满时,操作系统将所有历史信息写入另一个进程,由另一个进程进行合法性判断;二是当受保护进程执行敏感系统调用时,另一个进程也进行历史信息的合法性判断。合法性判断主要检查间接控制转移的跳转目标是合法目标集合内。如果所有间接控制转移的历史跳转目标在合法目标集合中,认为当前受保护进程没有收到攻击;如果有至少一个间接控制转移的历史跳转目标在合法目标集合中,那么认为受保护进程受到攻击。合法目标的集合是在线下通过静态分析获得的,并且存储在检查进程中。
原文标题:CFI/CFG 安全防护原理详解
文章出处:【微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
-
寄存器
+关注
关注
31文章
5357浏览量
120614 -
代码
+关注
关注
30文章
4798浏览量
68725 -
数据流
+关注
关注
0文章
120浏览量
14371
原文标题:CFI/CFG 安全防护原理详解
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
智能天线的基本概念
微波基本概念
电波的基本概念





 工商网监
工商网监
评论