 一文详细了解高速存储接口NVMe
一文详细了解高速存储接口NVMe
编者按
网络侧现在还没有形成标准的接口。Virtio-net因为软件虚拟化的流行所以标准,但其性能较差;AWS有自己的ENA/EFA接口,NVIDIA提供的是NV-SRIOV自定义接口,以及基于此封装的Virtio-net接口。 在存储侧,业界形成了“伟大”的共识:NVMe标准接口,兼顾了标准化和高性能。与此同时,从Virtio-blk逐步切换到NVMe在业界得到了众多的认可。
高速存储接口NVMe
跟网络接口相比,存储的接口标准化程度相对较高。NVMe是本地高性能存储主流的接口标准,同时基于NVMe扩展的NVMeoF是高性能网络存储主要的接口及整体解决方案标准。
1 NVMe概述
NVMe(Non-Volatile Memory Express)是经过优化的、高性能的、可扩展的主机控制器接口,专为非易失性存储器(NVM)技术而设计。NVMe解决了如下一些性能问题:
带宽:通过支持PCIe和诸如RDMA和光纤之类的通道,NVMe可以支持比SATA或SAS高很多的带宽。
IOPS:例如,串行ATA可能的最大IOPS为20万,而NVMe设备已被证明超过100万IOPS。
延迟:NVM以及未来的存储技术具有一微秒以内的访问延迟,需要一种更简洁的软件协议,能够实现包括软件堆栈在内的不超过10毫秒的端到端延迟。
NVMe协议支持多个深度队列,这是对传统SAS和SATA协议的改进。典型的SAS设备在单个队列中最多支持256个命令,而SATA设备最多支持32个命令。这些队列深度对于传统的硬盘驱动器技术已经足够,但不能充分利用NVM技术的性能。
相比之下,图1所示的NVMe多队列,每个队列支持64K命令,最多支持64K队列。这些队列的设计使得IO命令和对命令的处理不仅可以在同一处理器内核上运行,也可以充分利用多核处理器的并行处理能力。每个应用程序或线程可以有自己的独立队列,因此不需要IO锁定。NVMe还支持MSI-X和中断控制,避免了CPU中断处理的瓶颈,实现了系统扩展的可伸缩性。NVMe采用简化的命令集,相比SAS或SATA,NVMe命令集使用的处理IO请求的指令数量减少了一半,从而在单位CPU指令周期内可以提供更高的IOPS,并且降低主机中IO软件堆栈的处理延迟。
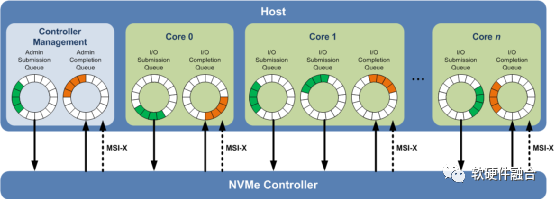
图1 NVMe多队列
2 NVMe寄存器
NVMe(Over PCIe)寄存器主要分为两类,一类是PCIe配置空间寄存器,一类是NVMe控制器相关的寄存器。
a.PCIe配置空间和功能
NVMe PCIe总线寄存器如表1所示,NVMe跟主机CPU的接口主要是基于PCIe总线,使用PCIe的Config和Capability机制。包括PCI/PCIe头、PCI功能和PCIe扩展功能。
表1 NVMe PCIe配置空间和功能
| 起始 | 结束 | 名称 | 类型 |
| 00h | 3Fh | PCI/PCIe头 | |
| PMCAP | PMCAP+7h | PCI功耗管理(Power Management)功能 | PCI功能 |
| MSICAP | MSICAP+9h | MSI(Message Signaled Interrupt)功能 | PCI功能 |
| MSIXCAP | MSIXCAP+Bh | MSI-X(MSI eXtension,MSI扩展)功能 | PCI功能 |
| PXCAP | PXCAP+29h | PCIe功能 | PCI功能 |
| AERCAP | AERCAP+47h | AER(Advanced Error Reporting)功能 | PCIe扩展功能 |
b.NVMe控制器寄存器
NVMe控制器寄存器位于MLBAR/MUBAR寄存器(PCI BAR0和BAR1)中,这些寄存器应映射到支持顺序访问和可变访问宽度的内存空间。NVMe 1.3d版本的控制器寄存器列表如表2所示。
表2 NVMe 1.3d版本的控制器寄存器列表
| 起始 | 结束 | 缩写 | 描述 |
| 0h | 7h | CAP | 控制功能 |
| 8h | Bh | VS | 版本 |
| Ch | Fh | INTMS | 中断屏蔽设置 |
| 10h | 13h | INTMC | 中断屏蔽清楚 |
| 14h | 17h | CC | 控制器配置 |
| 18h | 1Bh | Reserved | 保留 |
| 1Ch | 1Fh | CSTS | 控制器状态 |
| 20h | 23h | NSSR | NVM子系统重置(可选) |
| 24h | 27h | AQA | 管理队列属性 |
| 28h | 2Fh | ASQ | 管理提交队列基地址 |
| 30h | 37h | ACQ | 管理完成队列基地址 |
| 38h | 3Bh | CMBLOC | 控制器存储缓冲位置(可选) |
| 3Ch | 3Fh | CMBSZ | 控制器存储缓冲大小(可选) |
| 40h | 43h | BPINFO | 引导分区信息(可选) |
| 44h | 47h | BPRSEL | 引导分区读选择(可选) |
| 48h | 4Fh | BPMBL | 引导分区存储缓冲位置(可选) |
| 50h | EFFh | Reserved | 保留 |
| F00h | FFFh | Reserved | 命令设置具体的寄存器 |
| 1000h | 1003h | SQ0TDBL | 管理SQ0尾Db |
| 1000h + (1 * (4 << CAP.DSTRD)) | 1003h + (1 * (4 << CAP.DSTRD)) | CQ0HDBL | 管理CQ0头Db |
| 1000h + (2 * (4 << CAP.DSTRD)) | 1003h + (2 * (4 << CAP.DSTRD)) | SQ1TDBL | SQ1尾Db |
| 1000h + (3 * (4 << CAP.DSTRD)) | 1003h + (3 * (4 << CAP.DSTRD)) | CQ1HDBL | CQ1头Db |
| … | … | … | … |
| 1000h+ (2y * (4 << CAP.DSTRD)) | 1003h + (2y * (4 << CAP.DSTRD)) | SQyTDBL | SQy尾Db |
| 1000h + ((2y + 1) * (4 << CAP.DSTRD)) | 1003h + ((2y + 1) * (4 << CAP.DSTRD)) | CQyHDBL | CQy头Db |
| 供应商定制寄存器(可选) | |||
| SQ:Submission Queue,提交队列;CQ:Completion Queue,完成队列;Db:Doorbell,门铃。 |
3 NVMe队列
NVMe的队列是经典的环形队列结构,通过提交/完成队列对来实现队列的传输交互。
a.队列概述
NVMe使用的是经典的循环队列结构来传递消息(例如,传递命令和命令完成通知)。队列可以映射到任何PCIe可访问的内存中,通常是放在主机内存。
如图2,队列是固定大小的,通过Tail和Head来分别指向写入和读取的指针。像通常的队列数据结构一样,队列实际可使用的大小是队列大小减1,并且用Head等于Tail指示队列空,用Head等于(Tail+1)除以队列大小的余数来指示队列满。
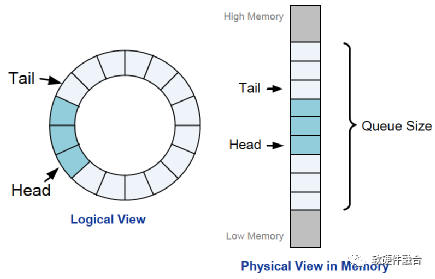
图2 NVMe队列结构
如上一节的图1,根据用途,NVMe队列有两类:管理队列和IO队列;根据传输方向有两类:提交队列和完成队列。具体介绍见表3。
表3 NVMe队列类型
| 管理 | IO | |
| 提交 |
用于提交管理命令,最大4K项; 用于配置控制器和IO队列等; 从主机侧到控制器侧。 |
用于传输IO命令,最大64K项; 用于提交IO操作命令; 从主机侧到控制器侧。 |
| 完成 |
管理命令的完成确认,最大4K项; 从控制器侧到主机侧; 独立的MSI-X中断处理。 |
IO命令的完成确认,最大64K项; 从控制器侧到主机侧; 独立的MSI-X中断处理。 |
b.队列处理流程
NVMe的驱动和设备交互跟Virtio不同:Virtio是在通过一个队列完成双向通知交互;而NVMe则采用提交队列和完成队列配合完成双向交互的方式。
如图3,NVMe队列处理流程如下(其中主机为软件驱动,控制器为硬件设备):
(1)主机写命令到提交队列项中。
(2)主机写DB(Doorbell)寄存器,通知控制器有新命令待处理。
(3)控制器从内存中的提交队列中读取命令。
(4)控制器执行命令。
(5)控制器更新完成队列,表示当前的SQ项已经处理。
(6)控制器发MSI-x中断到主机CPU。
(7)主机处理完成队列,同步更新提交队列中的已处理项。
(8)主机写完成队列Db到控制器,告知完成队列项已释放。
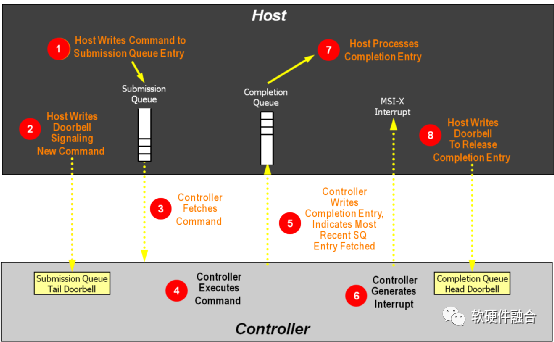
图3 NVMe队列处理流程
4 NVMe命令结构
我们通过如下一些概念来理解NVMe命令结构:
队列项的数据格式。NVMe的提交命令固定64字节,完成命令固定16字节。
命令。NVMe命令分为Admin和IO两类。
NVMe的数据块组织方式有PRP和SGL两种。
a.队列项的数据格式
提交队列和完成队列,组成队列对,协作完成NVMe驱动和设备之间的命令传输。提交队列每一项64字节固定大小,完成队列每一项16字节固定大小。
提交队列的数据格式如图4所示。NVMe提交队列项的数据格式属性如下:
Opcode:命令操作码
FUSE:熔合两个命令为一条命令
PSDT:PRP或SGL数据传输
Command Identifier:命令ID
Namespace Identifier:命名空间ID
Metadata Pointer:元数据指针
PRP entry 1/2:物理区域页项,对应的由PRP和PRP列表
SGL:散列聚合列表

图4 提交队列项的数据格式
完成队列的数据格式如图5所示。

图5 完成队列项的数据格式
NVMe完成队列的数据格式属性如下:
SQ Header pointer:SQ头指针
SQ Identifier:SQ ID
Command Identifier:命令ID
P:相位标志phase tag,完成队列没有head/tail交互,通过相位标志实现完成队列项的释放
Status Field:状态域
b.NVMe命令
NVMe管理类的命令如表4所示。
表4 NVMe管理命令列表
| 命令 | 必选或可选 | 类别 |
| 创建IO SQ | 必选 | 队列管理 |
| 删除IO SQ | 必选 | |
| 创建IO CQ | 必选 | |
| 删除IO CQ | 必选 | |
| 鉴别 | 必选 | 配置 |
| 获取特征 | 必选 | |
| 设置特征 | 必选 | |
| 获取日志页 | 必选 | 状态报告 |
| 异步事件请求 | 必选 | |
| 中止 | 必选 | 中止命令 |
| 固件镜像下载 | 可选 | 固件更新和管理 |
| 固件可用 | 可选 | |
| IO命令集定制命令 | 可选 | IO命令集定制 |
| 供应商定制命令 | 可选 | 供应商定制 |
NVMe IO类命令如表5所示。
表5 NVMe IO类命令列表
| 命令 | 必选或可选 | 类别 |
| 读 | 必选 | 必选的数据命令 |
| 写 | 必选 | |
| 清洗 | 必选 | |
| 不可改正的写 | 可选 | 可选的数据命令 |
| 写0 | 可选 | |
| 比较 | 可选 | |
| 数据集管理 | 可选 | 数据提示 |
| 预约获取 | 可选 | 预约命令 |
| 预约寄存器 | 可选 | |
| 预约释放 | 可选 | |
| 预约报告 | 可选 | |
| 供应商专用命令 | 可选 | 供应商专用 |
c.物理区域页PRP
PRP本质是一个链表,链表中的每一个指针都指向一个不超过页大小的数据块。PRP为8字节(64bits)固定大小,PRPList则最多可以占满一整个页。
PRP1和PRP2的格式如图6(a)所示。如果是首个PRP,则Offset(偏移量)可能是非零的数据,另外,偏移量是32bits对齐的(即末尾两位为0)。如图6(b)所示,在PRP列表中的所有PRP项的偏移量都为0,也即是PRP指针指向页面起始地址。

图6 PRP和PRP列表的格式
如图7(a)所示,当数据只有一个或两个页面的时候,就不需要使用PRP列表数据结构,直接PRP1和PRP2指向内存页面。当一个命令指向的数据超过两个内存页面的时候,就需要使用PRP列表,图7(b)所显式的为使用PRP列表的数据结构。
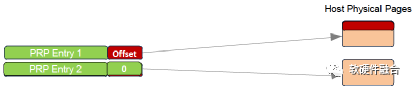
(a) 范例1:PRP直接指向内存页面
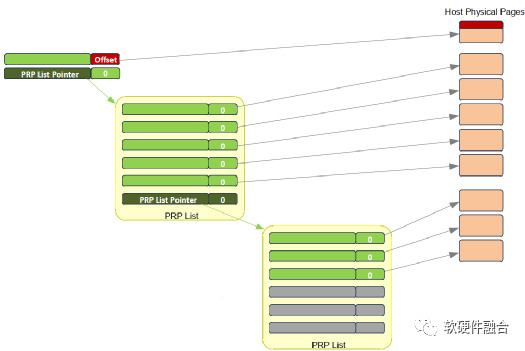
(b) 范例2:PRP列表指针,指向PRP列表,再指向内存页面
图7 PRP数据结构范例
d.散列聚合列表SGL
PRP每个链表指针最多指向一个页大小的数据块,即使若干个页在内存连续放置,PRP也需要对应的多个PRP项。为了减少元数据规模,SGL不限制指针指向数据块的大小,这样连续的若干个页的数据,只需要一个SGL项就可以标识。
NVMe中SGL的长度为16字节固定长度,其格式如图8(a)所示,在最高的第15字节SGL描述符类型域和子类型域标识不同类型的SGL描述符,根据不同的描述符,字节14-0的格式各有不同。SGL描述符类型如图8(b)所示。
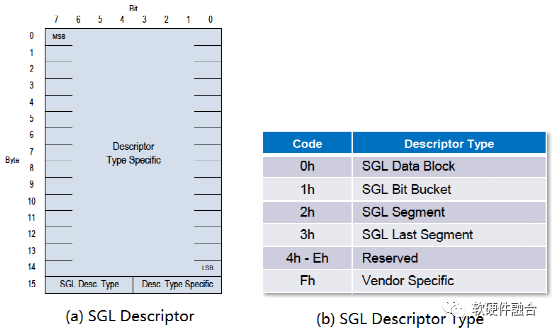
图8 NVMe SGL数据格式
如图9,NVMe SGL的数据结构是链表形式,SQ中的首个SGL段只有1项,为指向下一个SGL段的指针。下一个SGL段包含若干SGL数据块描述符,SGL段的最后的一个SGL描述符为另一个SGL段指针,指向下一个SGL段。根据传输数据大小,在最后一个SGL 段中,所有的SGL描述符都是SGL数据块描述符。
PRP只能指向单个内存页,这样,当要传输的数据块非常大的时候,就需要非常多的PRP项。而SGL可以指向不同大小的数据块,处于连续内存区域的多个数据块只需要一个SGL描述符就可以标识。因此,一般情况下,SGL比PRP更高效,更节省描述符资源。
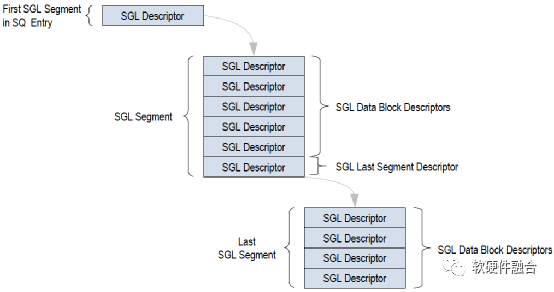
图9 NVMe SGL数据结构范例
5 网络存储接口NVMeoF
NVMeoF(NVMe over Fabrics)定义了一种通用架构,该架构支持一系列基于NVMe块存储协议的存储网络系统。包括从前端存储接口到后端扩展的大量NVMe设备或NVMe子系统,也包括访问远程NVMe设备和NVMe子系统所需的网络传输系统。
如图10所示,NVMeoF支持以太网、光纤和InfiniBand等不同的网络传输介质。基于RDMA的NVMeoF,使用的是InfiniBand、RoCEv1/v2或iWARP。NVMeoF的主要目标是提供与NVMe设备的低延迟远程连接,与服务器本地NVMe设备相比,增加的延迟不超过10µs。
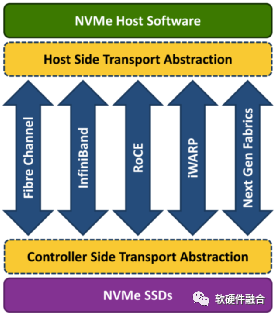
图10 NVMe over Fabrics支持的网络传输介质
利用NVMeoF技术,可以轻松构建由许多NVMe设备组成的存储系统,它通过基于RDMA或光纤网络实现的NVMeoF,构成了完整的NVMe端到端存储解决方案。NVMeoF系统可以提供非常高的访问性能,同时保持非常低的访问延迟。
为了远距离传输NVMe协议,理想的基础网络结构应具有以下特征:
可靠的基于信用的流量控制和传输机制。需要网络能支持自动流量调节,从而提供可靠的网络连接。基于信用的流量控制是光纤、InfiniBand和PCIe原生支持的功能。
优化的NVMe客户端。客户端软件能够直接与传输网络之间发送和接收NVMe命令,不需要使用诸如SCSI之类比较低效的转换层。
低延迟的网络。网络应该是针对低延迟优化过的,网络路径(包括交换机)端到端延迟不能超过10 µs。
能够减少延迟和CPU使用率的硬件接口卡。接口卡支持直接内存注册给用户模式的应用程序使用,以便数据传输可以直接从应用程序传递到接口卡。
网络扩展。网络能够支持扩展到成千上万个设备,甚至更多。
多主机支持。该网络应能够支持多个主机同时发送和接收命令。这也适用于多个存储子系统。
多端口支持。主机服务器和存储系统应能够同时支持多个端口。
多路径支持。该网络应能够同时支持任何NVMe主机发起端和任何NVMe存储目标端之间的多个路径。
最多可达64K的独立IO队列以及IO队列固有的并行性可以很好地与上述特征一起使用。每个IO队列可同时支持64K个命令。另外,NVMe命令数量非常少,因此在各种不同的网络环境中实现起来也非常的简单高效。
NVMeoF协议大约90%与NVMe协议相同。这包括NVMe命名空间、IO和管理命令、寄存器和属性、电源状态、异步事件等。两者的差异对比如表6所示。
表6 NVMe和NVMeoF对比
| 差异性 | NVMe(PCIe) | NVMeoF |
| 识别码 | BDF信息 | NVMe合格名称(NQN) |
| 设备发现 | 总线枚举 | 发现和连接命令 |
| 排队 | 基于内存 | 基于消息 |
| 数据传输 | PRP或SGL | 仅SGL,添加了密钥 |
NVMe基于分层的设计:如果把NVMe传输映射到内存访问和PCIe总线,则是通常所理解的NVMe;如果把NVMe传输映射到RoCE等网络接口,基于消息传输和内存访问,则是NVMeoF。
如图11,在本地NVMe中,NVMe命令和响应映射到主机中的共享内存,可以通过PCIe接口访问。但是,NVMeoF是基于节点之间发送和接收消息的概念构建的。NVMeoF通过把NVMe命令和响应封装到消息,每个消息包含一个或多个NVMe命令或响应。
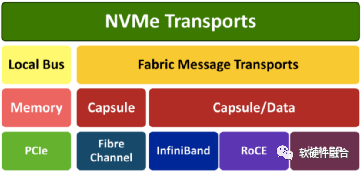
图11 NVMeoF堆栈
对于NVMeoF来说,多队列特征是支持的。通过使用类似NVMe的提交队列和完成队列机制来支持NVMe多队列模型,但是将命令封装在基于消息的传输中。NVMe IO队列对(提交和完成)是为多核CPU设计的,这种低延迟的设计在NVMeoF也同样支持。
当通过网络将复杂的消息发送到远端NVMe设备时,允许将多个小消息合并成一条消息发送,从而提高传输效率并减少延迟。如图12,一条消息封装了提交队列项或完成队列项、多个SGL、多组数据以及元数据等。每一项的内容与本地NVMe协议相同,但是封装是将它们打包在一起,用以提高传输效率。
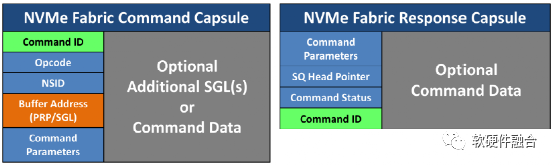
图12 NVMeoF的命令和响应封装
6 NVMe及NVMeoF总结
NVMe是为了高速非易失性存储定制的存储接口访问协议,定向优化了存储的主要性能指标:带宽、延迟和IOPS。NVMe最重要的特征体现在:
面向高速存储场景定制:NVMe是专门面向高速存储场景定制的协议,因此充分考虑了块存储的特点,重点解决存储性能的关键问题。
多队列支持:多队列不仅仅充分利用了硬件的并行处理能力,同时,也充分的利用了多核系统多线程并行的特点,最大化的优化了NVMe的性能。
标准化:NVMe是得到广泛应用的PCIe SSD接口标准,各大主流操作系统支持统一的标准NVMe驱动。
NVMeoF集成现有的NVMe和高速低延迟传输网络的技术,提供一整套整合的远程高速存储系统解决方案,非常适应于大规模存储集群的应用场景。
原文标题:高速的、标准化的存储接口NVMe
文章出处:【微信公众号:中科院半导体所】欢迎添加关注!文章转载请注明出处。
审核编辑:汤梓红
-
存储器
+关注
关注
38文章
7534浏览量
164489 -
接口
+关注
关注
33文章
8728浏览量
152115 -
设备
+关注
关注
2文章
4562浏览量
70943
原文标题:高速的、标准化的存储接口NVMe
文章出处:【微信号:bdtdsj,微信公众号:中科院半导体所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
一文详细了解JTAG接口
Xilinx FPGA NVMe Host Controller IP,NVMe主机控制器
在Xilinx ZCU102评估套件上启用NVMe SSD接口
详细了解下ups的相关计算
详细了解一下STM32F1的具体电路参数
基于 NVMe 接口的带 exFAT 文件系统的高速存储 FPGA IP 核演示
通过 iftop、 nethogs 和 vnstat 详细了解你的网络连接状态
NVMe标准更新定义了一个软件接口

一文详细了解OpenHarmony新图形框架
新品推荐|40G光纤接入的NVME存储模块

带您一起详细了解IEEE802.3bt(PoE++)的有关特点
Xilinx FPGA NVMe控制器,NVMe Host Controller IP
一文带你详细了解工业电脑

m2接口sata和nvme怎么区分
一文详解 ALINX NVMe IP 特性





 工商网监
工商网监
评论