 豆瓣电影Top250信息爬取
豆瓣电影Top250信息爬取
通过本案例[豆瓣电影Top250信息爬取]锻炼除正则表达式之外两种信息解析方式:Xpath和PyQuery。
爬取url地址:https://movie.douban.com/top250
分析:
分析url地址:每页25条数据,共计10页
第1页:https://movie.douban.com/top250?start=0
第2页:https://movie.douban.com/top250?start=25
第3页:https://movie.douban.com/top250?start=50
...
结果:
for i in range(10):
url = "https://movie.douban.com/top250?start="+str(i*25)
分析网页源代码内容:每部电影信息都是放在
...
具体实现代码如下:
from requests.exceptions import RequestException
from lxml import etree
from pyquery import PyQuery as pq
import requests
import re,time,json
def getPage(url):
'''爬取指定url页面信息'''
try:
#定义请求头信息
headers = {
'User-Agent':'User-Agent:Mozilla/5.0(WindowsNT6.1;rv:2.0.1)Gecko/20100101Firefox/4.0.1'
}
# 执行爬取
res = requests.get(url,headers=headers)
#判断响应状态,并响应爬取内容
if res.status_code == 200:
return res.text
else:
return None
except RequestException:
return None
def parsePage(content):
'''解析爬取网页中的内容,并返回字段结果'''
print(content)
# =========使用pyquery解析==================
# 解析HTML文档
doc = pq(content)
#获取网页中所有标签并遍历输出标签名
items = doc("div.item")
#遍历封装数据并返回
for item in items.items():
yield {
'index':item.find("div.pic em").text(),
'image':item.find("div.pic img").attr('src'),
'title':item.find("div.hd span.title").text(),
'actor':item.find("div.bd p:eq(0)").text(),
'score':item.find("div.bd div.star span.rating_num").text(),
}
'''
# =======使用xpath解析====================
# 解析HTML文档,返回根节点对象
html = etree.HTML(content)
#获取网页中所有标签并遍历输出标签名
items = html.xpath('//div[@class="item"]')
#遍历封装数据并返回
for item in items:
yield {
'index':item.xpath('.//div/em[@class=""]/text()')[0],
'image':item.xpath('.//img[@width="100"]/@src')[0],
'title':item.xpath('.//span[@class="title"]/text()')[0],
'actor':item.xpath('.//p[@class=""]/text()')[0],
'score':item.xpath('.//span[@class="rating_num"]/text()'),
#'time':item[4].strip()[5:],
}
'''
def writeFile(content):
'''执行文件追加写操作'''
with open("./result.txt",'a',encoding='utf-8') as f:
f.write(json.dumps(content,ensure_ascii=False) + "\n")
#json.dumps 序列化时对中文默认使用的ascii编码.想输出真正的中文需要指定ensure_ascii=False
def main(offset):
''' 主程序函数,负责调度执行爬虫处理 '''
url = 'https://movie.douban.com/top250?start=' + str(offset)
html = getPage(url)
# 判断是否爬取到数据,并调用解析函数
if html:
for item in parsePage(html):
writeFile(item)
# 判断当前执行是否为主程序运行,并遍历调用主函数爬取数据
if __name__ == '__main__':
for i in range(10):
main(offset=i*25)
time.sleep(1)
审核编辑:符乾江
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
python
+关注
关注
56文章
4811浏览量
85102 -
爬虫
+关注
关注
0文章
82浏览量
7035
发布评论请先 登录
相关推荐
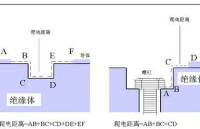
什么是爬电距离与电气间隙?
义爬电距离,可形象理解为一蚂蚁沿绝缘材料表面从一导电部件爬至另一导电部件所经最短路径。它涉及两个导电部件间沿绝缘材料表面测量的最短空间距离,这一距离的设定需综合考量电气设备的额定电压、绝缘材料的耐泄
PI推出新型宽爬电距离开关IC
深耕于高压集成电路高能效功率变换领域的知名公司Power Integrations(纳斯达克股票代号:POWI)今天为其面向汽车应用的InnoSwitch3-AQ反激式开关IC推出宽爬电封装选项
PCB设计中的爬电距离:确保电路板安全可靠
一站式PCBA智造厂家今天为大家讲讲什么是PCB设计爬电距离?PCB设计爬电距离的重要性。在电子制造业中,PCB设计是至关重要的一环。而在PCB设计中,爬电距离是一个关键概念,直接关系到电路板
索尼电影摄影机在未来电影制作教育中的作用
日本大学艺术学院自成立以来,作为日本第一所艺术学院,100多年来培养了许多从事专业电影制作人才。在电影研究系,引入了索尼电影摄影机“FX9”、“FX6” 和 “FX30” 进行实践教学。我们采访了
如何理解PCB设计的爬电距离?
一站式PCBA智造厂家今天为大家讲讲PCB设计爬电距离要求与走线规则有哪些?PCB设计爬电距离要求与走线规则。在PCB设计中,爬电距离和走线规则是关键的考虑因素,尤其是在高压电路和高频电路的设计中
QFN爬锡不好如何解决?—SMT锡膏
QFN封装的芯片IC,侧面引脚爬锡是个大难题,经常会遇到一些客户反馈:qfn爬锡不好怎么解决?qfn芯片引脚标准上锡高度如何确定?qfn侧面不爬锡?下面由深圳佳金源锡膏厂家来讲解一下:一、QFN锡膏

爬电距离是根据什么确定的
爬电距离(Creepage Distance)是指在电气设备中,两个导体之间沿绝缘材料表面的距离。它是一个重要的电气参数,用于评估电气设备在正常工作和故障条件下的绝缘性能。爬电距离的确定涉及到多个
爬电距离用什么检测设备
爬电距离是指在电气设备中,不同电位的导体之间,通过绝缘材料隔离的最短距离。爬电距离的检测对于确保电气设备的安全运行至关重要。本文将介绍爬电距离的检测设备及其使用方法。 一、爬电距离检测
爬电距离与电压的对应关系
爬电距离(Creepage Distance)是电气设备中的一个重要概念,它指的是在绝缘材料表面,沿着绝缘体表面或边缘,从带电部分到接地部分或不同电位部分之间的最短距离。爬电距离的大小直接影响
带PFC电路的75W输出功率、高效率的单级反激式电源TOP250YN中文资料
电子发烧友网站提供《带PFC电路的75W输出功率、高效率的单级反激式电源TOP250YN中文资料.pdf》资料免费下载
发表于 03-22 09:37
•2次下载
带PFC电路的75W输出功率、高效率的单级反激式电源TOP250YN75W数据手册
电子发烧友网站提供《带PFC电路的75W输出功率、高效率的单级反激式电源TOP250YN75W数据手册.pdf》资料免费下载
发表于 03-22 09:28
•2次下载





 工商网监
工商网监
评论