 900GB/s,NVLink才是英伟达的互联杀手锏
900GB/s,NVLink才是英伟达的互联杀手锏

电子发烧友网报道(文/周凯扬)英伟达在GTC22上发布了全新的GraceSuperchip,该芯片中用到了NVLink-C2C技术,而去年公开的GraceHopperSuperchip同样用到了这一技术。根据英伟达超大规模计算部门副总裁IanBuck的说法,Chiplet和异构计算已经成了解决摩尔定律缓慢进展的两大有效手段。而NVLink-C2C这一面向die和chip的互联技术,成了英伟达对愈发普及的Chiplet设计的回应。
Superchip的互联
也许在不少人看来的印象中,提到NVLink会想到下图这个桥接多个高端显卡或专业显卡的RTX NVLinkBridge,其实NVLink这一技术在服务器级别的GPU中反倒更为普遍。从P100的第一代NVLink,到V100的第二代NVLink,A100的第三代NVLink,最后再到如今H100的第四代NVLink。NVLink可以说是跟着GPU架构一路推陈出新了,如今享受第四代NVLink性能的成了Hopper架构的GPU。而在英伟达的SERDES和LINK技术发展下,NVLink也从PCB、MCM走向了硅中介层和晶圆,也因此有了NVLink-C2C。

RTX NVLinkBridge/ 英伟达
GraceSuperchip显然用的是ARM NeoverseN2这一基于Armv9架构的设计,但从芯片图可以看出,单个GraceSuperchip芯片由两个GraceCPU组成,才让总核心数达到了144。而这两个CPU组成的方式,正是NVLink-C2C这一互联技术。我们在开头已经提到,去年公开的GraceHopperSuperchip同样使用了这一互联技术,只不过当时单个GraceHopperSuperchip芯片中互联的,是一个GraceCPU和一个HopperGPU。
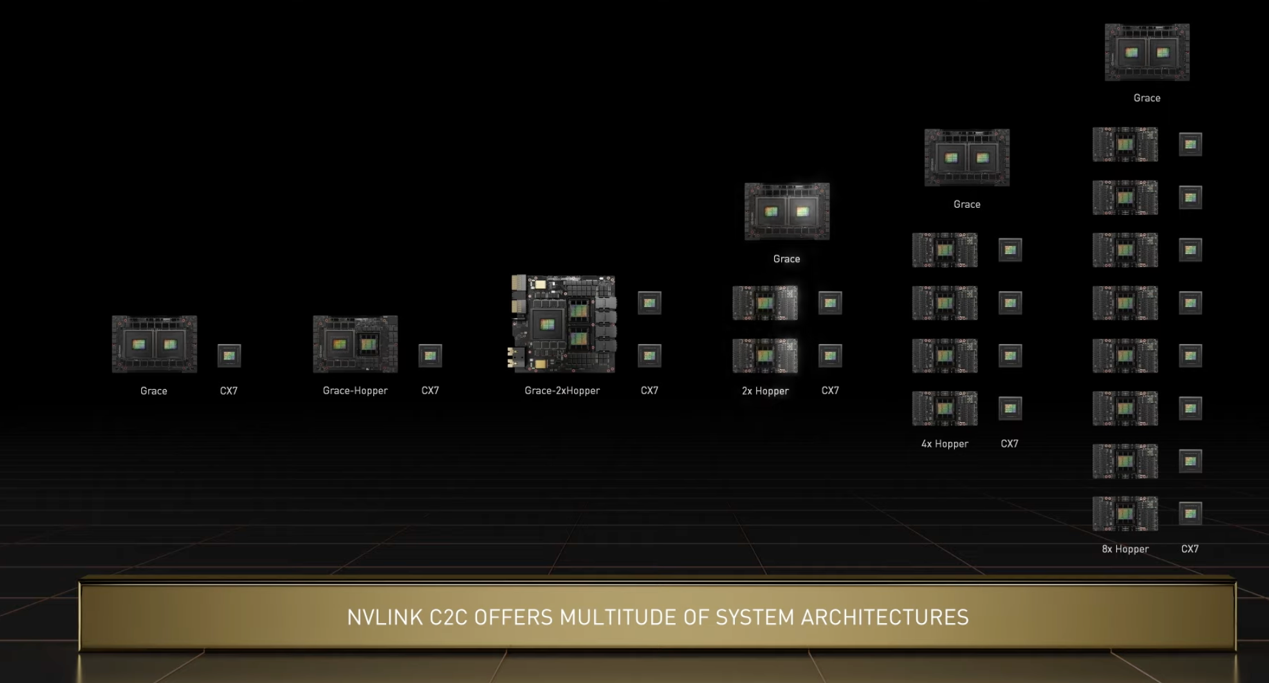
NVLink-C2C为英伟达带来的远不止这样一对一的互联方案,而是一整套系统架构上的创新。在NVLink-C2C的支持下,英伟达可以选择一个GraceCPU,两个HopperGPU的设计,或是两个2个GraceCPU+2个HopperGPU,甚至是2个GraceCPU+8个HopperGPU。可以看出,NVLink-C2C为Grace和Hopper在数据中心和HPC应用提供了极大的扩展性。
远超PCIe5.0的性能
英伟达强调,NVLink-C2C具有前所未有的性能,比如处理器与加速器之间900GB/s的高带宽数据传输,以及快速同步和高频率更新下的超低延迟,以及在先进封装英伟达芯片下,能效比可以做到PCIe5.0的25倍,面积效率更是达到90倍。

H100 SXM5 GPU / 英伟达
NVLink-C2C900GB/s的带宽确实优秀,也与第四代NVLink的性能一致,但这并不代表只要用上NVLink就能获得,我们从Hopper架构的GPU H100的参数上也能窥见一二。要想获得900GB/s的带宽性能,必须用到SXM5的大功率卡,而不是PCIe5.0的卡,虽然前者的功耗是后者的两倍,达到了可怕的700W,但PCIe5.0的H100在总体性能和带宽上确实差SXM5一截。
两者在PCIe5.0上的带宽一致,都是128GB/s,但如果用上NVLink,PCIe5.0版本的H100只能达到600GB/s的带宽,与第三代NVLink性能一致,只有SXM5版本下的NVLink才能达到满血的900GB/s。
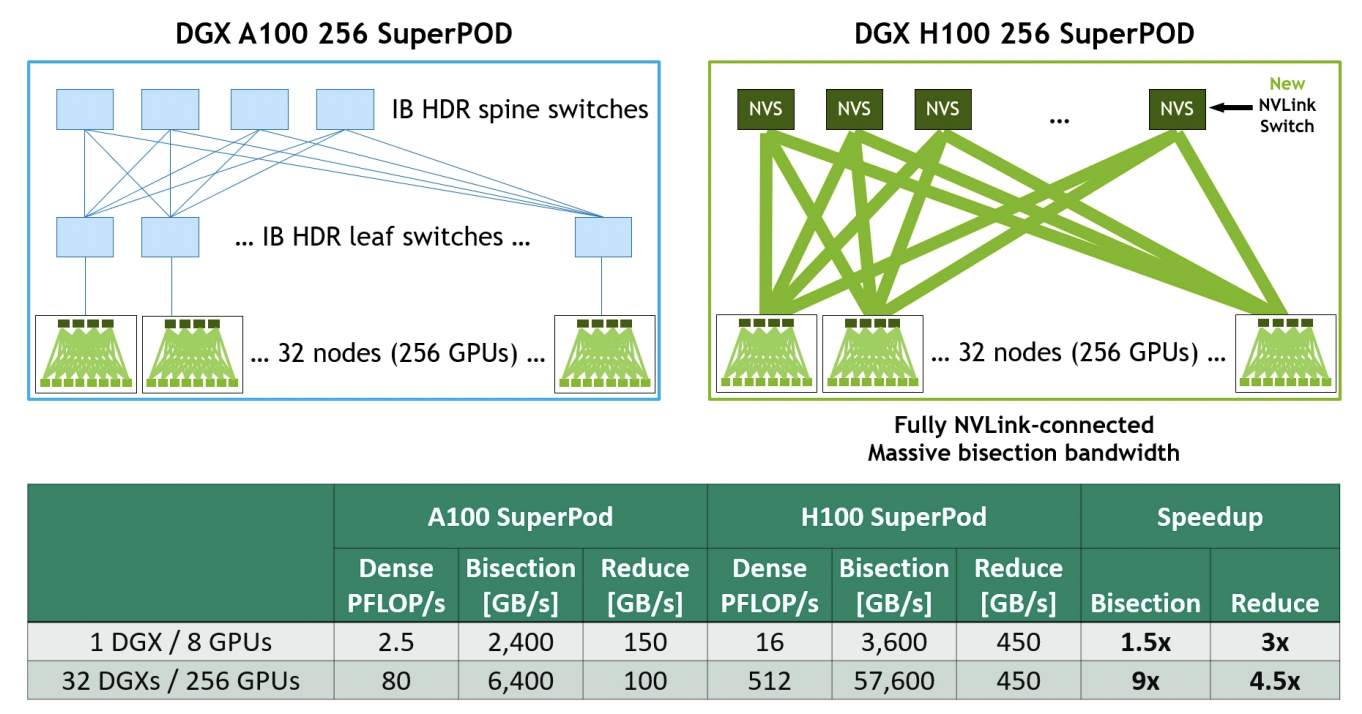
另外在第四代NVLink和第三代NVSwitch技术的组合下,英伟达推出了NVLinkSwitch这一方案,该系统最多支持到256个GPU,可实现57.6TB/s的总带宽。NVLinkSwitch也是英伟达DGX H100 SuperPOD系统的关键技术,英伟达甚至把自己收购的Mellanox旗下的InfiniBand节点互联技术拿来对比。从上图可以看出与基于A100+InfiniBand的SuperPOD系统相比,基于H100+NVLinkSwitch的SuperPOD系统在对分带宽上是前者的9倍。
开放而不是独占
其实NVLink的存在最初让不少人觉得有些一家独大的意思,毕竟最早NVLink仅仅只是用于多个英伟达GPU之间的互联,仅仅只是为自家的产品提供更多优势而已。而去年发布的GraceHopperSuperchip同样用到了这一技术,但这颗芯片却是英伟达设计的ArmCPU和GPU的互联。
这让人不禁担心,如果英伟达真的成功收购了Arm,会不会利用这一优势来全面垄断数据中心和HPC市场。毕竟Arm自己给出的互联方案CMN-700支持的是CCIX 2.0和CXL 2.0这两大标准互联协议,同时为第三方加速器提供PCIe5.0的连接。但就纸面参数给到的性能看来,NVLink这种专用方案似乎更加吃香一些。
不过Arm作为一家IP公司,目标自然是支持到多样化的加速器,从而全面发展Arm的生态。此前Arm在接受电子发烧友网采访时也表示,Arm期待给市场带来更多的灵活性,支持更多像Grace这样的系统。

NVLink-C2C示意图 / 英伟达
好在英伟达似乎也不打算将NVLink-C2C独占,而是宣布开放这一技术,支持集成英伟达技术的芯片半定制,通过Chiplet技术充分利用自家的GPU、DPU、NIC、CPU和SoC产品,与客户的IP进行NVLink-C2C互联。
尽管收购失败,英伟达与Arm的合作并没有就此停止,英伟达也在GTC22上宣布继续与Arm紧密合作,以支持并在未来改进Arm的AMBA CHI协议,加上对CXL的支持,从而与更多加速器和处理器做到互联。
与此同时,在全行业群策群力,试图打通生态的情况下,英伟达也并不打算将NVLink-C2C作为唯一的可选方案。所以除了NVLink-C2C外,集成了英伟达芯片的定制SoC也可选用前段时日公布的UCIe通用Chiplet互联标准,所以不必将数据中心上的CPU、DPU和GPU一整套都换成英伟达旗下的产品,给到第三方服务器芯片、DPU和加速器一个机会。不过,考虑到这两种互联方式只能选其一,英伟达也强调了NVLink-C2C经过优化,拥有更低的延迟、更高的带宽和更高的能效比,该如何选择还是看厂商自己的考量了。
-
芯片
+关注
关注
463文章
54463浏览量
469720 -
互联技术
+关注
关注
0文章
13浏览量
8513 -
英伟达
+关注
关注
23文章
4116浏览量
99662
发布评论请先 登录
市值近4万亿美元!英伟达GB300服务器正式出货

硅光成AI胜负手?英伟达20亿美元战略投资Marvell
新思科技与英伟达多项硬核科技成果亮相GTC 2026

英伟达重磅出手!AI 推理存储全面觉醒

NVIDIA新闻:英伟达10亿美元入股诺基亚 英伟达推出全新量子设备
传英伟达自研HBM基础裸片
国家网信办约谈英伟达
瑞之辰传感器:从“卡脖子”到“杀手锏”的技术突围

英伟达预计向中国客户交付 “第三代” 阉割芯片
【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】+NVlink技术从应用到原理
NVIDIA推出NVLink Fusion技术
英伟达台北设办事处!开放NVLink生态,800GB桌面超算面世




评论