 CXL和OMI:竞争还是互补?
CXL和OMI:竞争还是互补?
系统设计人员正在寻找所有他们能找到的增加内存带宽和容量的想法,专注于从内存改进到新型内存的所有内容。更高级别的体系结构更改可以帮助满足这两种需求,即使内存类型是从 CPU 中抽象出来的。
两种新的协议正在帮助实现这一目标,即CXL和OMI。但有一个迫在眉睫的问题是,它们是否会共存,或者一个是否会战胜另一个。
“随着处理器中CPU内核数量的增长,人们普遍认为希望为CPU内核获得更多的内存带宽和内存容量,”Rambus数据中心产品营销副总裁Mark Orthodoxou说。“人们已经没有能力添加DRAM频道了。
虽然这两个新协议在概念上有一些高级的相似之处,但它们并不相同。但是,对于它们是否真的相互竞争,似乎存在很多困惑。甚至还存在广泛的误解,特别是关于OMI的误解。
如今,每个人都专注于数据,无论是不断增长的数据量还是如何最好地管理数据。
”金融服务希望为欺诈检测添加更多数据源,以提供即时结果,“MemVerge的联合创始人兼首席执行官Charles Fan说。”社交媒体需要更多的数据源来分析用户,但提供即时结果。电子商务零售商想要更多的数据源,但需要即时建议。芯片正在设计1万亿个晶体管,但它们需要与前几代产品在同一时间周期内进入市场。基因组研究人员想要更多的细胞数据,但他们希望缩短疫苗发现的时间。
所有这些都需要更多的内存来为更多的计算提供服务。“在未来两年内,需要增加一千倍的计算量和一百倍的内存,”范说。
内存和存储
现代计算系统具有两层内存结构。有工作内存,它是处理器的本地内存,用于快速访问,它通常是某种形式的DRAM。然后是存储,一种内存形式,它在逻辑上并且通常在物理上远离处理器。这通常是非易失性存储器,如闪存甚至硬盘驱动器。
这种安排反映了功能、成本和访问的混合。“内存”往往是更快的技术,尽管成本高于存储技术。即使考虑到速度,它也不够快,无法跟上现代处理器的步伐,这就是为什么处理器上的SRAM缓存对性能如此重要的原因。
“存储”往往由非常高容量的存储器组成,这些存储器在每位基础上非常便宜。但是它们的访问时间可能比DRAM可以提供的时间慢几个数量级。
在过去十年中,存储类内存的讨论很多,它具有存储的一些特征,但具有内存的性能。MRAM,RMRAM和PCRAM是这种交叉类别的典型代表 - 在研究周期的早期还有其他想法。
将单一技术同时用于存储器和存储的承诺是诱人的,但它将为芯片设计人员创建需要与存储器接口的IC带来一些挑战。大多数芯片都有用于DRAM的特定接口。如果您可以使用MRAM或RRAM,那么您将CPU连接到哪个接口?这些存储器可能都具有不同的访问协议。
存储有不同的挑战,但内存类型的激增造成了类似的困境。此外,存储中的数据通常必须批量检索才能实际使用。该复制操作需要时间并消耗能量。
这两种情况都将受益于一种抽象出所使用的特定存储器的细节的方法,这样芯片设计人员以及在某种程度上的软件开发人员都不必那么关心特定系统的存储器细节。它还可能使软件在不同系统之间更具可移植性,这在数据中心特别有价值。
如今,它需要更高级别的程序或系统来管理和构建不同内存和存储资源的池。这种“大内存”程序提供了一种增加内存带宽和容量的方法。
“围绕大内存计算的论点是,与其不断努力使存储越来越快,不如利用其他新硬件,并辅以正确的软件集,”范说。“我们可以构建一个软件定义的内存池,该内存池可以成为应用程序需要处理的所有活动数据的平台,从而减少或消除活动应用程序数据的内存和存储之间的数据传输。
CXL 和 OMI 协议都提供抽象,尽管级别较低。但作为新兴的解决方案,很容易将两者混淆。OMI在网上几乎没有大张旗鼓的方式,对它的认识似乎低于对CXL的认识。根据你和谁交谈,他们做或不做同样的事情,因此做或不互相竞争。
CXL和/或OMI的出现并不一定影响大内存管理系统的使用。相反,它使物理内存连接更容易处理。”我们依靠CPU使用其接口/内存管理器访问内存,因此我们的软件与内存互连无关,包括CXL,OMI和DDR4 / 5,“Fan说。
CPU使用的近内存和OMI
工作内存需要快速。多年来,DRAM一直提供最佳的速度/成本组合,并且随着技术的发展,DRAM似乎可能会继续这样做。即便如此,还是有办法提高这种性能,但要付出代价。
DRAM的致命弱点是一组驱使记忆的长线。它们的高电容使得很难继续推动更高的内存速度并添加更多内存。
两种变体有所帮助。一个是RDIMM,其中地址和控制信号在芯片上缓冲。这加快了这些信号的速度,同时保留了数据信号。LRDIMM还通过缓冲数据更进一步。这增加了延迟的时钟周期,但加快了线路速度并允许更多内存。
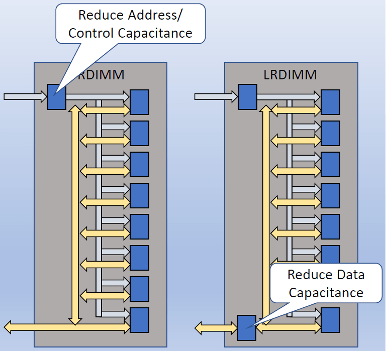
图1:RDIMM缓冲地址和控制信号;LRDIMM 还缓冲数据信号。其目的是拥有更短,更少的电容线路和更快的访问,但代价是额外的时钟周期延迟。
但是用于访问的端口需要许多引脚 - LRDIMM的每个通道152个,Objective Analysis的Jim Handy在去年的Hot Interconnects会议上的一次演讲中说。八个通道将花费1,216个引脚。
”由于引脚数量非常大,因此驱动这些引脚所需的面积很大,因为它是并行接口,“Orthodoxou说。
HBM 是另一种提供更高访问速度的替代方案。虽然价格昂贵,但它提供了最高的带宽。但它的总线是1000位宽。还有其他挑战,在关于OMI的白皮书中有所描述。
”虽然HBM是一个帮助,但它比标准DRAM贵得多,并且仅限于不超过12个芯片的堆栈,将其使用限制在低容量内存阵列上,“该论文说。”HBM 也很复杂和不灵活。在现场无法升级基于 HBM 的内存。因此,HBM 内存只在没有其他解决方案可用的情况下才被采用。
OMI从OpenCAPI世界中出现,为了延迟,OMI规范被分离出来。它旨在通过两种方式解决这些近内存挑战 - 迁移到SerDes,以及使用DIMM控制器。用于 OMI 通道的 DIMM 被称为差分 DIMM 或 DDIMM。
SerDes连接将取代当前的DDR式接口,以更少的信号提供更高的速度。控制器部分提供与LRDIMM上的寄存器相同的功能,在此过程中将总内存延迟增加约4ns。
“OMI延迟包括通过内存本身的延迟,这是从内部连接到主机中的传输端口回到主机中接收的内部连接的往返读取延迟,”OpenCAPI联盟的技术总监兼董事会顾问Allan Cantle说。
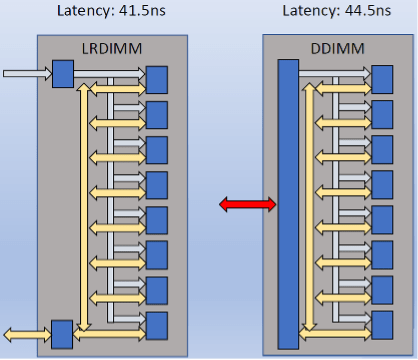
图 2:LRDIMM 与 DDIMM 的比较。DDIMM左侧的蓝色框是控制器。延迟增加几纳秒。
此外,控制器还可以连接到许多不同类型的内存。它充当该内存和处理器之间的桥梁。就处理器而言,所有内存看起来都像 OMI,除此之外的细节都在 DDIMM 上处理。
这允许系统构建商混合和匹配正在使用的内存类型。每个通道都可以是其自己的内存类型。事实上,只要控制器支持,单个 DDIMM 就可以混合使用内存。
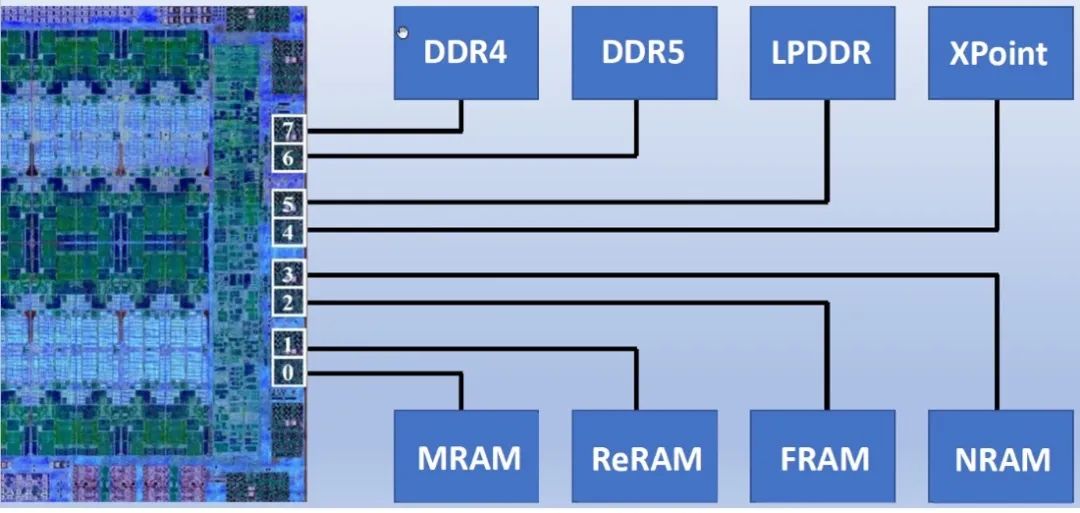
图 3:混合内存系统的概念示例,其中每个通道使用不同的内存技术。
然而,目前还不清楚系统是否真的会以这种方式组成。有些人认为,抽象的价值不在于创建异构内存池,而在于使具有一组接口的单个 CPU 可以访问由任何这些类型的内存构建的同构池。
“近内存将始终是同构存储器的更多选择,而不需要抽象异构存储器类型,”西门子EDA验证IP产品经理Gordon Allan说。
带宽将高于标准DRAM接口,尽管HBM仍然会更快。也就是说,拥有更少的引脚意味着SoC上用于存储器通道所需的硅将小得多,这使得OMI在带宽/面积上与HBM更具竞争力。由于接口占用空间较小,如果 OMI 可以使用的通道多于其他接口,则聚合带宽可能会更高。
为了完全出现这种新范式,首先需要控制器芯片,然后需要DDIMM可用。这一进程已经开始,但还有很长的路要走。即便如此,到目前为止,OMI的吸收速度一直很慢。

图 4:显示控制器和多个 DRAM 芯片的 DDIMM。还提供2U版本。资料来源:OpenCAPI Consortium
“我们没有与客户要求我们提供这项技术,但对于OMI来说,现在还为时尚早,”艾伦说。“这是IBM和其他一些公司推广的相对较新的进入者。它仍然没有在业界被广泛采用,但肯定有很多人对它感兴趣,因为它声称要扩展DDR的容量优势和HBM的性能带宽优势。但在这一点上,这仍然是一个大胆的,未经证实的说法。
远内存和CXL
远内存的情况更为复杂。除了与特定类型的内存相关的问题之外,频繁需要复制大块内存也是一个重大问题,特别是对于机器学习等内存或存储密集型应用程序,尤其是在数据中心。
这些是CXL解决的问题。”CXL 优化和虚拟化数据传输、存储和计算,“Synopsys 系统设计组工程总监 Levent Caglar 说。
这在数据中心应用程序中很有用。”HPC领域由大量的计算结构组成,“Cadence知识产权集团产品营销集团总监Arif Khan说。”CPU、GPU、加速器、FPGA 等都连接到不断增长的内存池。CXL 满足了异构计算的需求,同时保持了缓存的一致性,并允许内存的可扩展性。
但它也很复杂。“我们需要考虑存储的三个不同方面,”西门子EDA的Allan说。“首先是共置处理器和内存。在处理管道的另一端,我们有相干的内存和存储链接,其中数据必须与其他处理和通信元素共享。此外,我们还对数据中心的存储进行了更大规模的搜索和检索。CXL位于这些领域的第二和第三位。
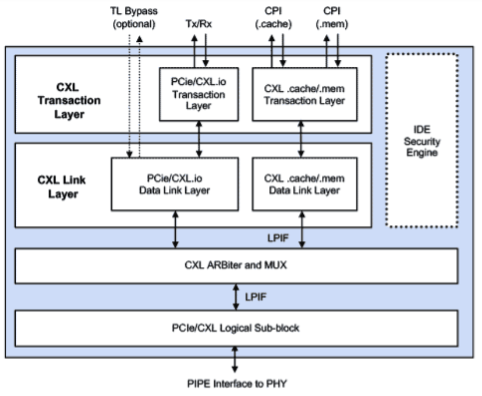
图 5:CXL 控制器的框图。CXL 功能依赖于 PCIe 进行物理互连。
CXL在概念上类似于OMI,充当允许处理器与内存类型无关的桥梁。”从系统其余部分的角度来看,该内存在逻辑上尽可能接近CPU,“Caglar说。
但CXL的职权范围比OMI要广泛得多,需要涵盖的用例要多得多。”OMI和CXL在它们试图解决的近内存问题方面非常相似,“Orthodoxou说。”他们的不同之处在于CXL试图解决远内存问题。
审核编辑 :李倩
-
芯片
+关注
关注
455文章
50817浏览量
423680 -
cpu
+关注
关注
68文章
10863浏览量
211784 -
存储
+关注
关注
13文章
4314浏览量
85851
原文标题:CXL和OMI:竞争还是互补?
文章出处:【微信号:TenOne_TSMC,微信公众号:芯片半导体】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
内存扩展CXL加速发展,繁荣AI存储

韩国无晶圆厂初创公司Panmnesia展示第一个支持CXL的AI集群
研华科技推出SQRAM CXL 2.0 Type 3内存模块SQR-CX5N
如何利用CXL协议实现高效能的计算架构
ocl电路是什么电源互补功效
打造异构计算新标杆!国数集联发布首款CXL混合资源池参考设计

新思科技CXL 3.1验证解决方案
国数集联发布业界首款CXL多级网络交换机,IB时代的颠覆者

国数集联研发出首款CXL多级网络交换机
采用STM32F030K6T6作互补PWM输出时,互补通道没有波形输出是为什么?
三星研发CXL混合存储模组,实现闪存与CPU数据直传
利用CXL技术重构基于RDMA的内存解耦合
FPGA中竞争与冒险的前世今生
什么是CXL技术?CXL的三种模式、类型、应用





 工商网监
工商网监
评论