 多模态大模型“紫东·太初”教学挑战任务发布
多模态大模型“紫东·太初”教学挑战任务发布
2020年9月,在教育部的领导下,华为技术有限公司与清华大学、北京大学等高校合作,布局建设首批72所“智能基座”产教融合协同育人基地,以昇腾、鲲鹏为核心,构建多样性计算的产业和人才生态,为我国AI产业高质量发展提供人才和智力支撑。清华大学计算机科学与技术系作为教育部-华为“智能基座”产教融合协同育人基地在清华大学的建设主体,共有20+老师参与。
2021年底,基于昇思MindSpore框架研发的业界首个三模态千亿参数多模态大模型“紫东·太初”实现基础模型开源,大模型开放。应清华大学计算机科学与技术系徐华老师邀请,华为昇思MindSpore首席架构师应江勇博士担任企业导师,于2022年3月7日在徐华老师的《数据挖掘·方法与应用》课程上完成关于AI大模型应用的研讨式教学,并在课堂上正式发布基于 “紫东·太初”的教学挑战任务。挑战任务发布当天,吸引了众多同学积极组队报名参加。
多模态大模型“紫东·太初”教学挑战任务发布现场
本次挑战任务是基于昇腾AI全栈软硬件平台技术,使用图像、语音、文本开源数据集及“紫东·太初”开源代码,完成基于万条小规模数据集的大模型预训练,以及对应下游任务的fine-tune和推理验证。共发布3个任务:
任务1
使用图像、语音、文本开源数据集,对大模型进行预训练,以支持下游任务的使用;
任务2
基于已训练好的多模态大模型,使用提供的数据集,进行图像到文本生成、跨模态检索两个下游任务的fine-tune和推理验证;
任务3
设计新的下游任务,并完成优化以达到较高准确率。
本轮挑战任务项目实施将贯穿整个春季课程,期间华为企业导师共同参与指导。根据计划,项目将在4月完成中期考核,6月完成结题考核,后续也将对本次试点工作进行经验总结和分享。
本次合作是智能基座项目的深化,未来,昇腾AI生态将继续探索更多的人工智能人才培养模式,共同构建以人工智能核心技术为基础的产业与人才生态,提高高等教育支撑解决关键核心技术问题的能力和水平。
原文标题:教学挑战任务发布:基于 “紫东 . 太初”预训练及下游任务开发
文章出处:【微信公众号:华为计算】欢迎添加关注!文章转载请注明出处。
审核编辑:汤梓红
-
AI
+关注
关注
87文章
30516浏览量
268743 -
人工智能
+关注
关注
1791文章
47050浏览量
238033 -
模型
+关注
关注
1文章
3204浏览量
48789
原文标题:教学挑战任务发布:基于 “紫东 . 太初”预训练及下游任务开发
文章出处:【微信号:gh_3a181fa836b6,微信公众号:华为计算】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于AX650N/AX630C部署多模态大模型InternVL2-1B

利用OpenVINO部署Qwen2多模态模型
依图多模态大模型伙伴CTO精研班圆满举办
商汤科技与海通证券携手发布金融行业首个多模态全栈式大模型
人大系初创公司智子引擎发布全新多模态大模型Awaker 1.0
商汤科技联合海通证券发布业内首个面向金融行业的多模态全栈式大模型

商汤科技发布5.0多模态大模型,综合能力全面对标GPT-4 Turbo
李未可科技正式推出WAKE-AI多模态AI大模型

苹果发布300亿参数MM1多模态大模型
武汉人工智能研究院即将发布“紫东太初 3.0”,助力千行百业发展
蚂蚁集团推出20亿参数多模态遥感基础模型SkySense
蚂蚁推出20亿参数多模态遥感模型SkySense
自动驾驶和多模态大语言模型的发展历程

从Google多模态大模型看后续大模型应该具备哪些能力
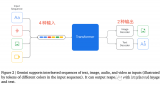
大模型+多模态的3种实现方法






 工商网监
工商网监
评论