 在未来十年中,Chiplets的采用率将大幅增长
在未来十年中,Chiplets的采用率将大幅增长
最近两周,Chiplet相关新闻的频出。NVIDIA宣布了一款令人兴奋的新型NVLink-C2C互连,用于其CPU、DPU、GPU以及与其合作伙伴和客户的其他集成之间的紧密耦合链路。UCIe(Universal Chiplet Interconnect Express)成立,其宗旨是为封装创新构建生态系统。在本博客中,我们将关注推动Chiplet采用的关键用例,以及Arm如何帮助推动成功的Chiplet生态系统。
Chiplets在许多不同的应用中已经存在多年,但我们正处于一个转折点。Chiplets可以通过扩展超过reticle限制来提高性能,同时仍然提供管理芯片成本的能力。摩尔定律的放缓已经在业界讨论了一段时间。虽然先进制程(5nm及以下)为逻辑提供了好处,但片上系统(SoC)的IO和内存组件的扩展速度显著放缓,这意味着成本更高,效益更低。
一个全面的芯片解决方案包括许多不同的元素,从协议到物理层,再到封装技术。如今,SoC设计者正在将不同的组件组合在一起,以实现其性能、成本和系统组成目标。各种各样的解决方案可能会导致混乱。对于芯片集成,有两种常见的观点。
第一种观点是将传统的单片SoC分解成多个更小的组件。这种方法有一个通用的协议、内存、调试和安全模型。SoC设计者努力使片上总线尽可能无缝地扩展到多芯片。
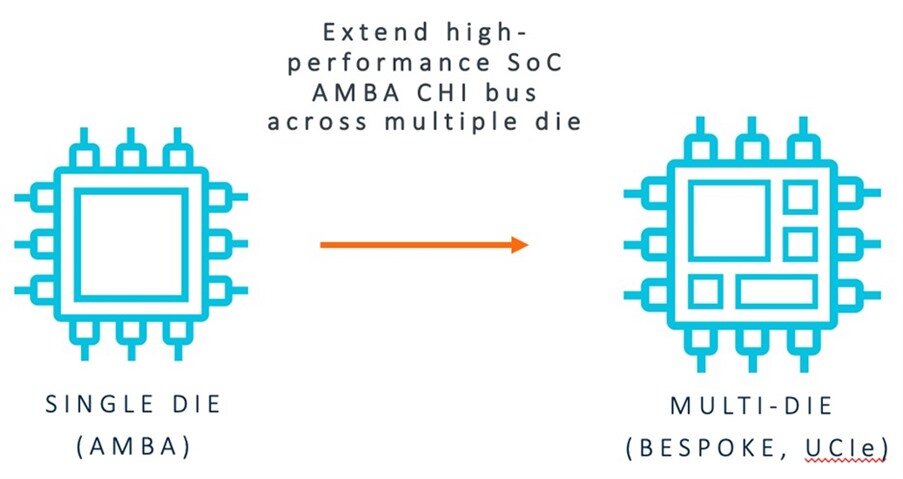
第二种观点着眼于通过行业标准的板级互连将现有的板级组件连接起来,并将其集成到封装中,这是因为它具有更好的带宽和能效。SoC设计者努力尽可能多地使用现有框架,并为其需求提供最佳的片间物理层和封装解决方案。
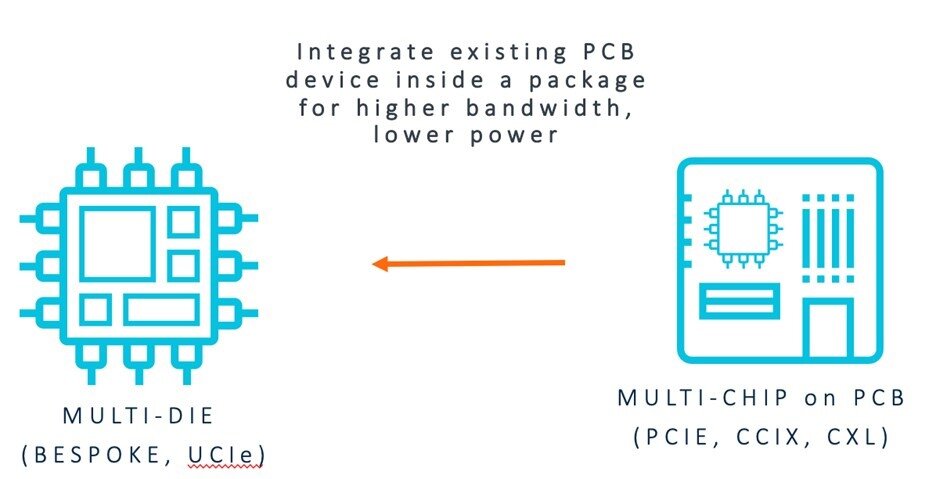
AMBA CHI多芯片解决方案
Arm建立了AMBA-CHI(Coherent Hub Interface),为高度可扩展、多核、异构的SOC提供片上通信。由于其可扩展性,CHI也非常适合于完整的多芯片接口规范中的协议层。CHI与CCIX和UCII等行业标准兼容,同时还提供了NVIDIA NVLIK-C2C互连等定制解决方案。使用CHI的好处包括:
。为多核扩展(CPU-CPU)实现对称一致性
。为高级异构工作负载(即CPU-GPU)实现对称一致性
。支持公共内存和安全模型
。消除协议桥接以获得更优化的链路
NVIDIA NVLink-C2C通过其NVIDIA Grace CPU超级芯片和NVIDIA Hopper GPU提供NVIDIA CPU、GPU和DPU之间的连接。多芯片解决方案将CHI的优势与利用NVIDIA世界级SerDes和link技术的最佳物理层和封装解决方案相结合。这使得一类新的可组合集成产品能够通过芯片构建,无论最终SoC是针对超级计算还是针对高级异构CPU-GPU工作负载。
UCIe:Chiplets的开放生态系统
基于Chiplets的处理器需要提高性能和降低成本,这一点是众所周知的。但直到最近,人们还没有就如何在特定于供应商的实现之外利用芯片体系结构的好处达成一致。Universal Chiplet Interconnect Express(UCIe)标准就是为了满足这一需求而开发的。UCIe将半导体厂商、封装产商、IP供应商、晶圆代工厂商和云服务提供商的行业领导者聚集在一起,推动一个新的开放式芯片生态系统。UCIe 1.0规范提供了完整的标准化芯片间互连,包括物理层、协议栈、软件模型和合规性测试。这使得最终用户能够混合和匹配来自多供应商生态系统的芯片组件,以进行SoC构建。
UCIe协议层利用PCIe和CXL将传统的片外设备与任何计算体系结构集成。此外,UCIe还设计了通过流媒体协议接口插入其他协议(如AMBA-CHI)的能力,允许SoC产品在协议方面具有灵活性。
有关UCIe技术和会员资格的更多信息,请访问UCIe网站。https://www.uciexpress.org/
Chiplets的未来
唯一可以确定的是,在未来十年中,Chiplets的采用率将大幅增长。在整个行业中,创新和标准化方面的持续投资将转化为更高的性能、更低的成本和更广泛的采用。在Arm,我们希望看到一系列定制和标准实现。我们将很高兴看到,
-
chiplet
+关注
关注
6文章
416浏览量
12546
发布评论请先 登录
相关推荐
何小鹏宣布未来十年愿景,加速全球化AI汽车布局
沃达丰与谷歌深化十年战略合作
IDC报告:2023年中国CAD市场年增长率达12.8%,展现强劲增长动力
哪种嵌入式处理器架构将引领未来十年的发展?

亚马逊豪掷千亿美元,未来十年加速数据中心建设
联发科谈未来十年的战略布局
RISC-V在服务器方面应用与发展前景
RISC-V在服务器方面的应用与发展前景如何?刚毕业的学生才开始学来的及吗?
持续突破,中微公司超过十年平均年营收增长率超过35%
机构:年复合增长率高达42.5%,Chiplet价值量将超千亿美元
跨周期,创未来!华秋喜获中国产业互联网十周年-杰出企业
跨周期,创未来!华秋喜获中国产业互联网十周年-杰出企业






 工商网监
工商网监
评论