 NVIDIA Sionna:一个GPU加速的开源库
NVIDIA Sionna:一个GPU加速的开源库
即使 5G 无线网络正在全球范围内安装和使用,学术界和工业界的研究人员已经开始为 6G 定义 愿景和关键技术 。虽然没有人知道 6G 将是什么,但一个反复出现的愿景是, 6G 必须能够以前所未有的规模创建数字双胞胎和分布式机器学习( ML )应用程序。 6G 研究需要新的工具。
支撑 6G 愿景的一些关键技术是被称为太赫兹波段的高频通信。在这个波段,更多的光谱是按数量级提供的。技术示例包括:
机器学习有望在整个 6G 协议栈中发挥决定性作用,这可能会彻底改变我们设计和标准化通信系统的方式。
应对这些革命性技术的研究挑战需要新一代工具来实现突破,这些突破将定义 6G 时代的通信。原因如下:
- 许多 6G 技术需要模拟特定环境,例如工厂或小区,物理位置、无线信道脉冲响应和视觉输入之间具有空间一致性的对应关系。目前,这只能通过昂贵的测量活动或基于场景渲染和光线跟踪组合的高效模拟来实现。
- 随着机器学习和神经网络变得越来越重要,研究人员将从带有本地 ML 集成和自动梯度计算的链接级模拟器中受益匪浅。
- 6G 仿真需要前所未有的建模精度和规模。 ML 增强算法的全部潜力只能通过基于物理的模拟来实现,这些模拟以过去不可能的细节水平来解释现实。
介绍 NVIDIA Sionna
为了满足这些需求, NVIDIA 开发了 Sionna ,这是一个 GPU 加速的开源库,用于链路级模拟。
Sionna 能够快速原型化复杂的通信系统架构。这是世界上第一个能够在物理层使用神经网络的框架,并且不需要为数据生成、培训和性能评估使用单独的工具链。
Sionna 实施了一系列经过仔细测试的最先进算法,可用于基准测试和端到端性能评估。这可以让你专注于你的研究,使它更具影响力和可复制性,同时你花更少的时间实现你专业领域之外的组件。
Sionna 是用 Python 写成的,基于 TensorFlow 和 Keras 。所有组件都以 Keras 层的形式实现,这使您可以通过与构建神经网络相同的方式连接所需的层来构建复杂的系统架构。
除了少数例外,所有组件都是可微的,因此梯度可以在整个系统中反向传播。这是系统优化和机器学习的关键因素,尤其是神经网络的集成。
NVIDIA GPU acceleration 提供了几个数量级的更快模拟,并可扩展到大型多 GPU 设置,从而实现此类系统的交互式探索。如果没有 GPU 可用,那么 Sionna 甚至可以在 CPU 上运行,尽管速度较慢。
Sionna 提供了丰富的 documentation 和一系列教程,使其易于入门。
Sinna 的第一个版本具有以下主要功能:
- 5G LDPC 、 5G 极性码和卷积码、速率匹配、 CRC 、交织器、扰码器
- 各种解码器: BP 变体、 SC 、 SCL 、 SCL-CRC 、维特比
- QAM 和定制调制方案
- 3GPP 38.901 信道模型( TDL 、 CDL 、 RMa 、 UMa 、 Umi )、瑞利、 AWGN
- 正交频分复用
- MIMO 信道估计、均衡和预编码
Sionna 是根据 Apache 2.0 许可证发布的,我们欢迎外部各方的贡献。
你好,Sionna!
下面的代码示例显示了一个“你好,世界!”模拟使用 16QAM 调制在 AWGN 信道上传输一批 LDPC 码字的示例。本例显示了如何实例化 Sionna 层,并将其应用于先前定义的张量。编码风格遵循 Keras 的 functional API 。您可以在 Google Collaboratory 上的 Jupyter notebook 中直接打开此示例。
batch_size = 1024 n = 1000 # codeword length k = 500 # information bits per codeword m = 4 # bits per symbol snr = 10 # signal-to-noise ratio c = Constellation("qam",m,trainable=True) b = BinarySource()([batch_size, k]) u = LDPC5GEncoder (k,n)(b) x = Mapper (constellation=c)(u) y = AWGN()([x,1/snr]) 11r = Demapper("app", constellation=c)([y,1/snr]) b_hat = LDPC5GDecoder(LDPC5GEncoder (k, n))(11r)
Sionna 的一个关键优势是,组件可以进行训练或由神经网络代替。 NVIDIA 使Constellation可训练,并用NeuralDemapper取代Demapper,后者只是通过 Keras 定义的神经网络。
c = Constellation("qam",m,trainable=True) b = BinarySource()([batch_size, k]) u = LDPC5GEncoder (k,n)(b) x = Mapper (constellation=c)(u) y = AWGN()([x,1/snr]) 11r = NeuralDemapper()([y,1/snr]) b_hat = LDPC5GDecoder(LDPC5GEncoder (k, n))(11r)
在这种情况下,定义星座点的张量现在变成了一个可训练的 TensorFlow 变量,可以通过 TensorFlow 自动微分功能与NeuralDemapper的权重一起跟踪。由于这些原因, SIONA 可以被视为一个可微链路级模拟器。
展望未来
很快, Sionna 将允许集成光线跟踪来取代随机通道模型,从而实现许多新的研究领域。超快射线追踪是通信系统数字孪生的关键技术。例如,这使得建筑物的架构和通信基础设施的共同设计能够实现前所未有的吞吐量和可靠性。
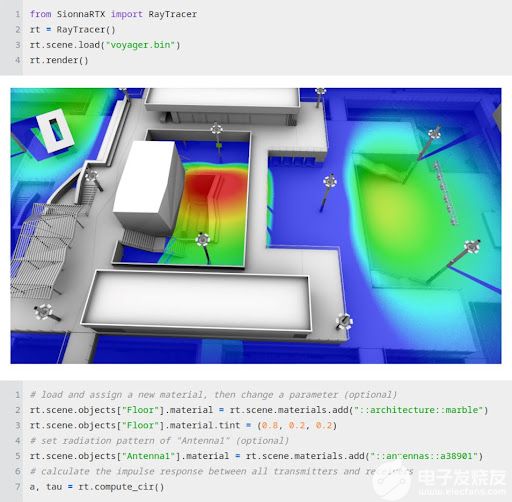
图 3 。从 Jupyter 笔记本电脑中访问硬件加速光线跟踪功能
Sionna 利用计算( NVIDIA CUDA 核)、 AI ( NVIDIA 张量核)和 NVIDIA GPU 的光线跟踪核对 6G 系统进行闪电般的模拟。
我们希望你们能分享我们对 Sionna 的兴奋,我们期待着听到你们的成功故事!
- Sionna 产品页面
- Sionna documentation
- nvlabs/sionna GitHub 回购
-
通信
+关注
关注
18文章
6036浏览量
136059 -
NVIDIA
+关注
关注
14文章
4994浏览量
103144 -
gpu
+关注
关注
28文章
4743浏览量
128986
发布评论请先 登录
相关推荐
OpenHarmony开源GPU库Mesa3D适配说明
《CST Studio Suite 2024 GPU加速计算指南》
NVIDIA火热招聘GPU高性能计算架构师
NVIDIA-SMI:监控GPU的绝佳起点
购买哪款Nvidia GPU
Nvidia GPU风扇和电源显示ERR怎么解决
在Ubuntu上使用Nvidia GPU训练模型
NVIDIA深度神经网络加速库cuDNN软件安装教程
NVIDIA宣布一套用于构建GPU加速ARM服务器的参考设计
NVIDIA推出适用于Python的VPF,简化开发GPU加速视频编码/解码
Nvidia宣布推出了一套新的开源RAPIDS库
使用NVIDIA数学库加速GPU应用程序
177倍加速!NVIDIA最新开源 | GPU加速各种SDF建图!






 工商网监
工商网监
评论