 cosFormer:重新思考注意力机制中的Softmax
cosFormer:重新思考注意力机制中的Softmax
导读:Transformer在自然语言处理、计算机视觉和音频处理方面取得了巨大成功。作为其核心组成部分之一,Softmax Attention模块能够捕捉长距离的依赖关系,但由于Softmax算子关于序列长度的二次空间和时间复杂性,使其很难扩展。
针对这点,研究者提出利用核方法以及稀疏注意力机制的方法来近似Softmax算子,从而降低时间空间复杂度。但是,由于误差的存在,效果往往不尽如人意。
商汤多模态研究组认为,近似操作本身存在的误差使得其效果很难超越Softmax Attention。我们的观点是,与其近似Softmax,不如设计一种方式代替Softmax,并且同时降低时间空间复杂度。
因此,本文提出了名为cosFormer的方法,在时间空间复杂度关于序列长度为线性复杂度的同时,其性能接近或者超越Softmax Attention,并在LRA benchmark上取得SOTA结果。我们的设计核心理念基于两点,首先是注意力矩阵的非负性,其次是对局部注意力的放大(非极大值抑制)。
本文主要介绍已收录于ICLR 2022的一篇文章 cosFormer : Rethinking Softmax in Attention。

Part 1
背景

1. Softmax Attention
为了引出我们的方法,对Softmax Attention的计算方式进行一定的推广:
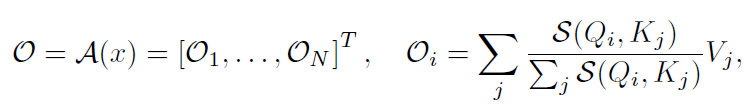
其中表示相似度计算函数,如果,上式即变为Softmax Attention(不考虑除以的缩放操作)。注意到计算的时间复杂度为,的时间复杂度为,所以总时间复杂度为,即关于序列长度是二次的。
2. 线性 Attention
通过分析我们发现,性能瓶颈的主要原因是操作,如果相似度函数可以表示为:
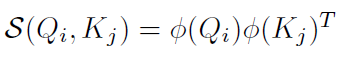
那么:
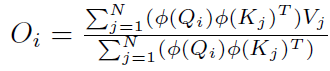
根据矩阵运算的结合律:
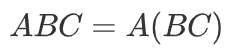
上式可以变换为(编者修正:下方公式未变换,请参照论文):
经过计算后可以得到该方法的时间复杂度为,即关于序列长度是一次的。
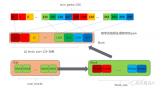
Softmax Attention和线性Attention的计算方式可以用下图概括:
所以接下来将介绍的选择,以及核心的reweighting操作。
3. Softmax 的两大性质
我们经过分析以及实验,归纳出Softmax Attention中比较重要的性质,这两个性质可以指导我们的模型设计:
1. 注意力矩阵的非负性
2. 局部注意力的放大(非极大值抑制)
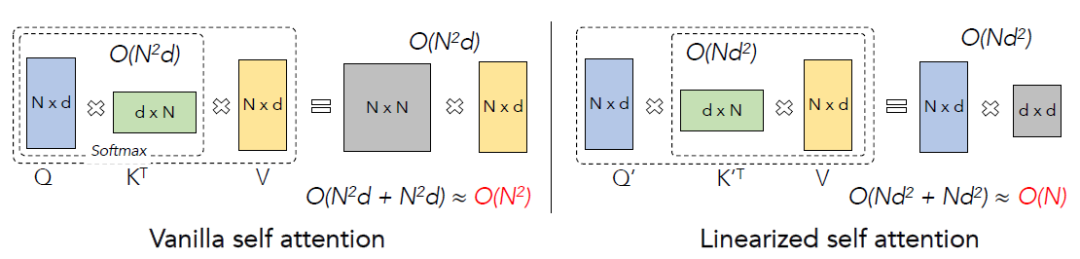
对于第一点,我们有如下实验进行验证(模型结构为RoBERTa):
这里Loss表示验证集损失(越低越好),其余指标均为准确率(越高越好)。可以看到,当保证了注意力矩阵的非负性之后,可以达到较好的效果。基于该实验,我们选择为ReLU函数。
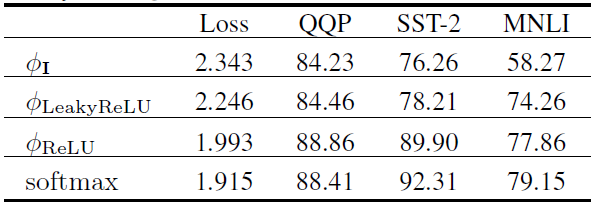
对于第二点,我们的方式是在注意力矩阵中引入先验locality信息,观察Softmax注意力矩阵,如下图所示,我们发现其注意力矩阵的权重在对角线附近很集中:
所以我们的方法需要在加了reweighting操作后也更加集中在对角线附近。注意并非所有的有类似权重的函数均适用,这个reweighting的函数需要跟前面的QK一样可以拆分成两个矩阵的乘法的形式。
至此,就可以引入我们的cosFormer了。
Part 2
cosFormer
1. 方法
我们的方法基于线性Attention,首先给出符号定义:
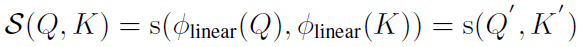
根据之前的分析,我们选择了:
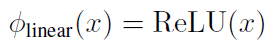
可得:
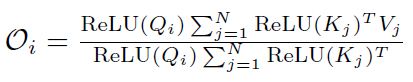
为了进行reweighting操作,并且同时保证线性Attention的计算方式依然成立,我们选择了cos函数:
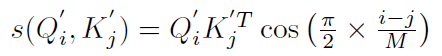
展开可得:
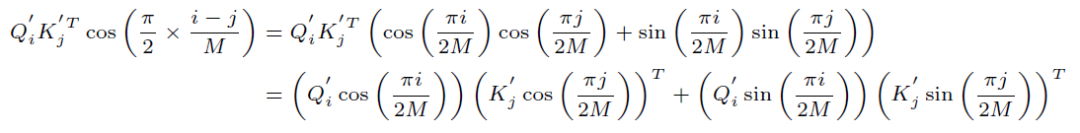
为了便于展示,我们把它记作:
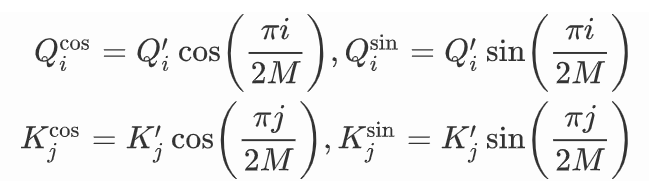
最终得到:
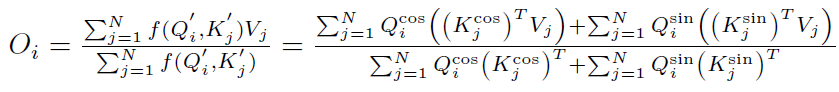
上式和线性Attention的计算方式一致,经过分析不难得出时间复杂度依然是。
2. 实验结果
我们在单向模型、双向模型以及LRA benchmark上测试了我们的方法,均取得了非常不错的效果。
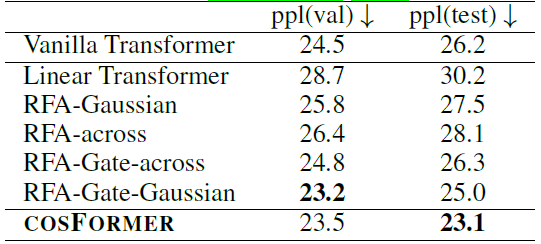
单向语言模型,指标表示困惑度(越低越好):
双向语言模型,指标表示准确率(越高越好):

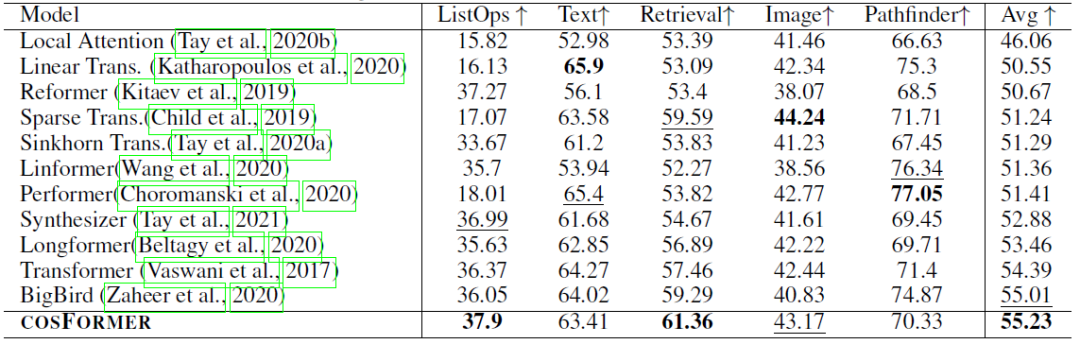
LRA benchmark:
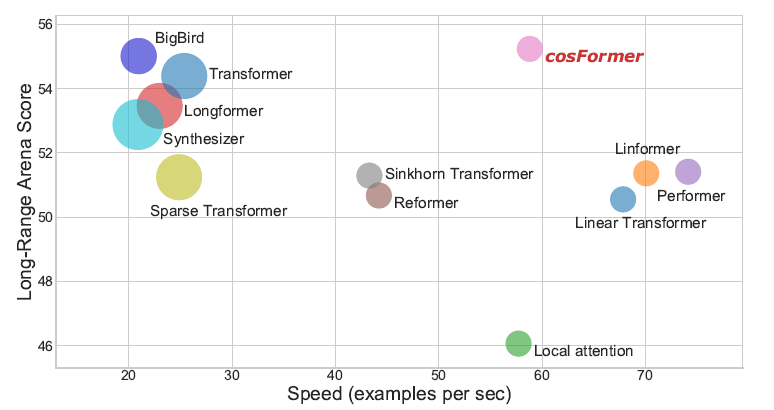
1)性能实验,指标表示准确率(越高越好):
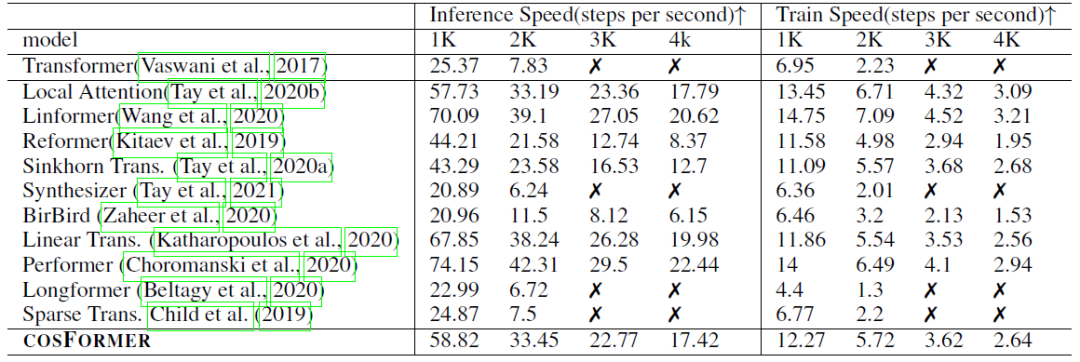
2)内存速度实验,指标表示速度(越高越好,如果内存溢出,则标记为叉):
审核编辑 :李倩
-
函数
+关注
关注
3文章
4331浏览量
62618 -
计算机视觉
+关注
关注
8文章
1698浏览量
45993 -
Softmax
+关注
关注
0文章
9浏览量
2512
原文标题:ICLR'22 | cosFormer:重新思考注意力机制中的Softmax
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
ADS1299S是否推荐有与DEMO匹配的传感器头?
什么是LLM?LLM在自然语言处理中的应用
一种基于因果路径的层次图卷积注意力网络

一种创新的动态轨迹预测方法
2024 年 19 种最佳大型语言模型

【《大语言模型应用指南》阅读体验】+ 基础知识学习
Transformer模型在语音识别和语音生成中的应用优势
【大规模语言模型:从理论到实践】- 阅读体验
浪潮信息发布源2.0-M32开源大模型,模算效率大幅提升
浪潮信息发布“源2.0-M32”开源大模型
采用单片超构表面与元注意力网络实现快照式近红外光谱成像

阿里巴巴发布AtomoVideo,兼容多款文生图模型的高保真图像视频框架
【研究动态】万物纵横杨帆博士在Applied Soft Computing发表石化生产异常工况预警的人工智能算法研究成果

OneFlow Softmax算子源码解读之BlockSoftmax
OneFlow Softmax算子源码解读之WarpSoftmax





 工商网监
工商网监
评论