 Merlin HugeCTR 分级参数服务器简介
Merlin HugeCTR 分级参数服务器简介
参数服务器是推荐系统的重要组成部分,但是目前的训练端参数服务器由于高延迟和同步问题无法有效解决推理部署中模型过大的瓶颈。Merlin HugeCTR(以下简称 HugeCTR)团队针对传统参数服务器的问题重新设计了一种分级推理端参数服务器,将 GPU 内存作为一级缓存,Redis 集群作为二级缓存,RocksDB 作为持久化层,极大提高了推理效率。HugeCTR 团队将分多期为大家介绍此分级参数服务器的具体设计和细节,本期为系列的第一期。
1. 引言:
传统训练端参数服务器及其缺陷
传统参数服务器维护和同步模型参数仅用于训练,worker 节点执行前向和后向计算。具体来说,在训练中:worker 节点从 server 节点中拉取其相应的参数,进行前向计算,通过反向传播计算梯度,最后将这些梯度推送到服务器。在推理中,它只执行前两个步骤。如果部署在高性能设备集群中,worker 节点的计算速度非常快,因此传统 PS 通常会遇到这两个瓶颈:
(1)server 和 worker 之间的 pull 和 push 操作延迟;
(2)从 worker 节点收到梯度后,server 节点中的参数同步问题。
由于 GPU 停顿、同步/一致性不足,GPU 的计算结构很难通过使用基于 CPU 的实现的参数服务器来支持数据并行。在 GPU 内存中拟合完整模型以及小批量输入数据和中间网络状态的需要限制了可以训练和推理的模型的大小。同样的瓶颈也出现在推理部署中,因为推理节点也需要从集中的参数服务器组中拉取所有需要的模型参数。当请求包含节点未加载的参数时,节点需要再次同步从参数服务器拉取参数。当模型参数版本发生变化时,需要暂停推理服务,逐个节点更新参数。
使用基于 CPU 的参数服务器进行模型推理的部署时,上述问题非常明显,特别是推荐模型的部署。
HugeCTR 推理端分级参数服务器
为了解决上述问题,我们 HugeCTR 团队设计了一个全新的参数服务器系统,利用分布在多个服务器机器上的 GPU 扩展深度学习应用以进行推理。我们称为 HugeCTR Hierarchical GPU-based Inference Parameter Server,简称为 HPS。HPS 处理在并行模型实例的推理过程中使用的共享模型参数(Embedding 向量和权重)相关的同步和通信。
与其他系统不同,HPS 进行了许多专门针对高效利用 GPU 的优化,包括分布式参数服务器分片,以实现 GPU/CPU 中许多庞大 Embedding Table 的并行推理,以及 GPU 友好的缓存、 临时数据移动内存、 内存管理机制。
推理端参数服务器的支持
支持不同模型的混合部署:如 DeepFM、DCN、DLRM、MMOE 和序列模型 (DIN、DIEN)
支持推理的大输入数据量:Batch_size 大于 1K,look_up per request 超过 1000。
支持更快的在线热部署:将完整模型更新/加载到推理节点进行服务只需不到 10 分钟(Embedding Table 大小大于 600G)
支持资源隔离:在推理中隔离 GPU 的内存,确保推理服务在生产环境基于不同的隔离策略。例如一种支持单 GPU/CPU 的模型,通过第三方工具(如 k8s)重启和隔离。
支持不同模型独立的巨大 Embedding Table:不同模型每个 Embedding Table 大小大于 600G。
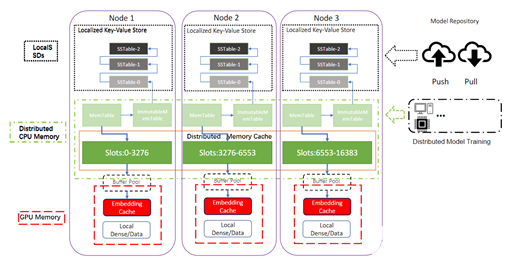
支持单个节点的多级缓存:
部分参数(热特征)可以放入 GPU 内存直接用于推理。
部分参数(冷特征)可以放入 CPU 内存用于 CPU 与 GPU 交换。
Embedding 的其余部分存储在本地 SSD。
支持模型更新机制:
模型部署支持特定的性能指标,在性能下降时通过版本控制及时回滚。
通过分层缓存机制来重叠数据的转移以缓解网络带宽瓶颈。
使用最小的 PS 分片粒度不间断更新,而无需逐节点更新。
支持容错和持久性:一个节点故障后参数和服务可以被恢复。
支持在线学习:每分钟更新密集模型权重
2. HugeCTR 分级参数服务器组件块:
CPU 分布式缓存
分布式 Redis 集群
Redis 集群的同步查找:每个模型实例从本地化的 GPU 缓存中查找所需的 Embedding key,这也会将丢失的 Embedding key(在 GPU 缓存中找不到的 key)存储到丢失的键缓冲区中。丢失的键缓冲区与 Redis 实例同步交换,Redis 实例依次对任何丢失的 Embedding key 执行查找操作。因此,分布式 Redis 集群充当了二级缓存,可以完全替代本地化参数服务器来加载所有模型的完整 Embedding table。
GPU 缓存(Embedding Cache)
异步/同步插入
我们支持将丢失的 Embedding key 异步插入到 Embedding Cache 中。该功能可以通过配置文件中自定义的命中率阈值自动激活。当 Embedding Cache 的真实命中率高于自定义阈值时,Embedding Cache 会异步插入缺失的 key。反之则会以同步方式插入,以确保推理请求的高精度。通过异步插入方式,与之前的同步方式相比,在 Embedding Cache 达到用户定义的阈值后,可以进一步提高 Embedding Cache 的真实命中率。
在线更新
我们支持将增量 Embedding Key 异步刷新到 Embedding Cache 中。当稀疏模型文件需要更新到 GPU Embedding Cache 时,会触发刷新操作。基于在线训练完成模型的模型版本迭代或增量参数更新后,需要将最新的 Embedding table 更新到推理服务器上的 Embedding Cache 中。为了保证运行模型可以在线更新,我们将通过分布式事件流平台(Kafka)更新分布式数据库和持久化数据库。同时,GPU Embedding Cache 会刷新现有 Embedding key 的值,并替换为最新的增量 Embedding vector。
本地键值存储
本地 RocksDB 查询引擎
对于仍然无法完全加载到 Redis 集群中的超大规模 Embdding table 我们将在每个节点上启用本地键值存储(RocksDB)。
RocksDB 的同步查询:Redis 集群客户端在分布式 GPU 缓存中查找 Embedding key 时,会记录丢失的 Embedding key(在 Redis 集群中未找到的 key),记录到丢失的 key buffer 中。丢失的 key buffer 与本地 RocksDB 客户端同步交换,然后将尝试在本地 SSD 中查找这些 key。最终,SSD 查询引擎将对所有模型缺失的 Embedding key 执行第三次查找操作。
对于已经存储在云端的模型存储库,RocksDB 将作为本地 SSD 缓存,用于存储 Redis 集群无法加载的剩余部分。因此,在实践中,本地化的 RocksDB 实例充当了三级缓存。
3. HugeCTR 分级参数服务器的配置和使用:
训练端
配置模型名和 Kafka broker
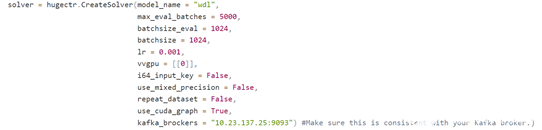
在训练段,用户在 CreateSolver 时需要为当前训练的模型提供一个模型名,这个模型名将会被参数服务器用于区分不同模型。
同时,用户还需要配置 Kafka broker 的端口和 ip,用于将模型发送到到 Kafka。
增量模型导出接口

用户可以使用以上接口,将增量模型导出到 Kafka broker,参数服务器端将会自动消化 Kafka 的消息。
推理端
Embedding Cache配置:
gpucache: 用户可自由配置是否使用 GPU 缓存。
gpucacheper: 用于决定 Embedding table 导入到 GPU 缓存的比例,默认为 0.5。
hit_rate_threshold: 用户自定义的阈值,将会决定 GPU 缓存的更新方式。
使用 hashmap/parallel hashmap 作为 CPU 缓存时的相关配置:
num_partitions: Embedding table 将会被分为多个分片进行存储,这里用于指定分片数量。
overflow_policy: 当缓存占满时,可选择随机移除或移除最老的 Embedding。
overflow_margin: 用于指定每个分片储存的最大 Embedding 数量。
overflow_resolution_target: 用于指定每个分片移除 Embedding 的比例,取值为 0 到 1 之间。
initial_cache_rate: 初始的缓存率。
使用 Redis 作为 CPU 缓存时的相关配置:
需要配置服务器 ip 和端口,用户名以及密码,其他与 hashmap/parallel hashmap 相同。需要注意的是 num_partitions 必须大于等于 redis 节点的数量。
RocksDB:
path: RocksDB 存储数据的路径,由用户自行配置。
read_only: 启用 read_only 后,RocksDB 将无法更新,适用于静态 Embedding 的推理。
Kafka:
brokers: 用于设置 Kafka 服务器的 ip 和端口。
poll_timeout_ms: 用于数据接收的最大等待时长,超过该时间将自动把参数更新送往数据存储层。
max_receive_buffer_size: 用于数据接收缓冲区大小,超过该大小将自动把参数更新送往数据存储层。
max_batch_size: 用于设置每次批量数据发送的大小。
4. 结语
在这一期的 HugeCTR 分级参数服务器简介中,我们介绍了传统参数服务器的结构以及 HugeCTR 分级推理参数服务器是如何在其基础上进行设计和改进的。我们还介绍了我们的三级存储结构以及相关配置使用。在下一期中,我们将着重介绍 HugeCTR 分级参数服务器各个部件的设计细节,敬请期待。
关于作者
About Yingcan Wei
GPU计算专家,毕业于香港大学,HugeCTR算法组负责人。当前主要从事HugeCTR的算法设计与推理架构工作。研究领域包括深度学习域适应,生成对抗网络,推荐算法设计优化。在2020年加入英伟达前,任职于欧美外资以及互联网等企业,拥有多年图像处理 、数据挖掘,推荐系统设计开发相关经验。
About Jerry Shi
本科毕业于加州大学伯克利分校,在康奈尔大学获得硕士文凭。于2021年加入英伟达,在Merlin HugeCTR团队算法组负责推荐系统架构与算法的相关设计及开发。
审核编辑:郭婷
-
cpu
+关注
关注
68文章
10870浏览量
211913 -
gpu
+关注
关注
28文章
4742浏览量
128973 -
服务器
+关注
关注
12文章
9185浏览量
85495
发布评论请先 登录
相关推荐
四路串口服务器的功能特点及规格参数简介
Merlin HugeCTR V3.4.1版本新增内容介绍
GPU加速的推荐程序框架Merlin HugeCTR
Merlin HugeCTR分级参数服务器:缓存和在线更新设计
如何使用NVIDIA Merlin推荐系统框架实现嵌入优化





 工商网监
工商网监
评论