 利用NVIDIA TensorRT实现推理的QAT伪量化
利用NVIDIA TensorRT实现推理的QAT伪量化
深度学习正在彻底改变行业提供产品和服务的方式。这些服务包括用于计算机视觉的对象检测、分类和分割,以及用于基于语言的应用程序的文本提取、分类和摘要。这些应用程序必须实时运行。
大多数模型都采用浮点 32 位算法进行训练,以利用更大的动态范围。然而,在推理时,这些模型可能需要更长的时间来预测结果相比,精度降低推理,造成一些延迟的实时响应,并影响用户体验。
在许多情况下,最好使用精度降低的整数或 8 位整数。挑战在于训练后简单地四舍五入权重可能导致较低的模型精度,特别是当权重具有较大的动态范围时。本文简单介绍了量化感知训练( QAT ),以及如何在训练过程中实现伪量化,并用 NVIDIA TensorRT 8 。 0 进行推理。
概述
模型量化是一种流行的深度学习优化方法,其中模型数据(包括网络参数和激活)从浮点表示转换为较低精度表示,通常使用 8 位整数。这有几个好处:
在处理 8 位整数数据时, NVIDIA GPU 使用更快更便宜的 8 位 张量核 来计算卷积和矩阵乘法运算。这会产生更多的计算吞吐量,这在计算受限的层上尤其有效。
将数据从内存移动到计算元素(在 NVIDIA GPU s 中的流式多处理器)需要时间和精力,而且还会产生热量。将激活和参数数据的精度从 32 位浮点值降低到 8 位整数可导致 4 倍的数据缩减,从而 省电 并减少产生的热量。
有些层有带宽限制(内存有限)。这意味着它们的实现将大部分时间用于读写数据,因此减少它们的计算时间并不会减少它们的总体运行时间。带宽限制层从减少的带宽需求中获益最大。
减少内存占用意味着模型需要更少的存储空间,参数更新更小,缓存利用率更高,等等。
量子化方法
量化有很多好处,但是参数和数据精度的降低很容易影响模型的任务精度。考虑到 32 位浮点可以在区间[-3 。 4e38 , 3 。 40e38]中表示大约 40 亿个数字。这个可表示数的区间也被称为 dynamic-range 。两个相邻的可表示数字之间的距离是表示的 精确 。
浮点数在动态范围内分布不均匀,大约一半的可表示浮点数在区间[-1 , 1]内。换言之,[-1 , 1]区间中的可表示数字将比[1 , 2]中的数字具有更高的精度。[-1 , 1]中可表示的 32 位浮点数的高密度有助于深度学习模型,其中参数和数据的大部分分布质量都在零附近。
但是,使用 8 位整数表示法,只能表示 28不同的价值观。这 256 个值可以均匀地或不均匀地分布,例如,为了在零附近获得更高的精度。所有主流的深度学习硬件和软件都选择使用统一的表示,因为它能够使用高吞吐量的并行或矢量化整数数学管道进行计算。
转换浮点张量的表示 (Xf) 到 8 位表示 (Xq) ,使用 scale-factor 将浮点张量的动态范围映射到[-128 , 127]:
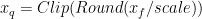
这是对称量子化,因为动态范围是关于原点对称的。
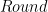
是一个应用某些舍入策略将有理数舍入为整数的函数;和
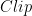
是一个函数,用于剪裁超出[-128127]区间的异常值。 TensorRT 使用对称量化来表示激活数据和模型权重。
图 1 的顶部是一个任意浮点张量的图Xf,表示为元素分布的直方图。我们选择了一个对称的系数范围来表示量化张量:[-amax,amax]。 在这里amax是要表示的绝对值最大的元素。要计算量化比例,请将浮点动态范围划分为 256 个相等部分:


这里显示的计算比例的方法使用 全量程 ,可以用有符号 8 位整数表示:[-128 , 127]。 TensorRT 显式精度( Q / DQ )网络在量化权重和激活时使用此范围。
使用 8 位整数表示的动态范围与舍入操作引入的误差之间存在紧张关系。较大的动态范围意味着原始浮点张量中的更多值用量化张量表示,但也意味着使用较低的精度和引入较大的舍入误差。
选择较小的动态范围可以减小舍入误差,但会引入剪裁误差。超出动态范围的浮点值将被剪裁为动态范围的最小/最大值。
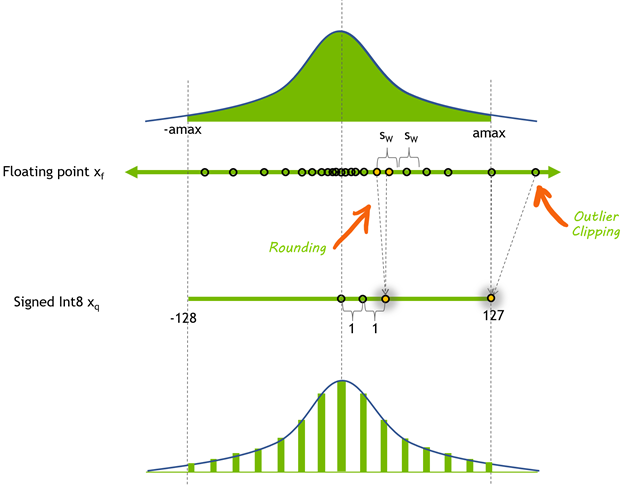
图 1 。浮点张量的 8 位有符号整数量化Xf对称动态范围Xf[-amax,amax]通过量化映射到 [-128 , 127]。
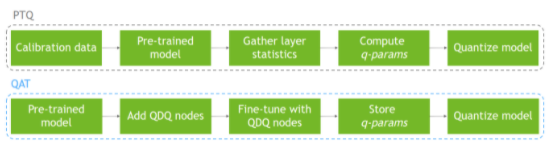
为了解决精度损失对任务精度的影响,人们发展了各种量化技术。这些技术可以分为两类:训练后量化( PTQ )或量化感知训练( QAT )。
顾名思义, PTQ 是在高精度模型经过训练后进行的。使用 PTQ ,量化权重很容易。您可以访问权重张量并可以测量它们的分布。量化激活更具挑战性,因为激活分布必须使用实际输入数据进行测量。
为此,使用代表任务实际输入数据的小数据集评估训练的浮点模型,并收集有关层间激活分布的统计信息。作为最后一步,使用几个优化目标之一确定模型激活张量的量化尺度。这个过程是 校准 ,使用的代表数据集是 calibration-dataset 。
有时 PTQ 不能达到可接受的任务准确性。这是当你 MIG HT 考虑使用 QAT 的时候。 QAT 背后的思想很简单:如果在训练阶段包含量化误差,就可以提高量化模型的精度。它使网络能够适应量化的权值和激活。
有各种各样的方法来执行 QAT ,从一个未经训练的模型开始到一个预先训练的模型开始。通过在训练图中插入假量化操作来模拟数据和参数的量化,所有的方法都改变了训练方案,将量化误差包含在训练损失中。这些运算被称为“假”运算,因为它们对数据进行量化,然后立即对数据进行去量化,这样运算的计算就保持浮点精度。这个技巧在深度学习框架中增加了量化噪声而没有太大变化。
在前向过程中,对浮点权重和激活进行伪量化,并使用这些伪量化的权重和激活来执行层的操作。在向后过程中,使用权重的渐变来更新浮点权重。为了处理量化梯度,除了未定义的点之外,几乎所有地方都是零,您可以使用( 直通估计器 ( STE ),它通过伪量化操作符传递梯度。当 QAT 过程完成时,伪量化层持有量化尺度,您可以使用这些尺度来量化模型用于推理的权重和激活。
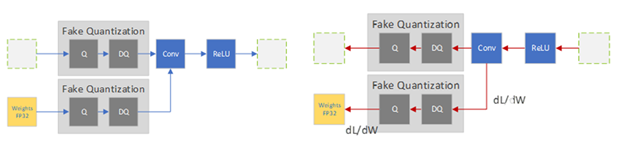
图 2 。训练前传球中的 QAT 伪量化算子 (左) 后传球 (右)
PTQ 是这两种方法中比较流行的方法,因为它简单,不涉及训练管道,这也使得它成为一种更快的方法。然而, QAT 几乎总是产生更好的精度,有时这是唯一可以接受的方法。
TensorRT 中的量子化
TensorRT 8 。 0 支持使用两种不同处理模式的 INT8 模型。第一种处理模式使用 TensorRT 张量动态范围 API ,并利用 INT8 精度( 8 位有符号整数)计算和数据机会优化推理延迟。
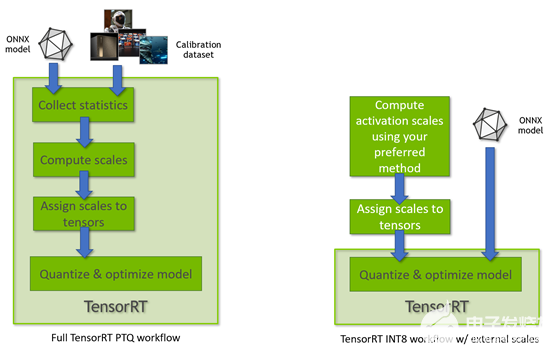
图 3 。 TensorRT PTQ 工作流程 (左) vs 。 TensorRT INT8 量子化,使用从配置张量动态范围导出的量子化尺度 (右)
当 TensorRT 执行完整的 PTQ 校准配方时,以及当 TensorRT 使用预配置的张量动态范围时,使用此模式(图 3 )。另一种 TensorRT INT8 处理模式用于处理具有 QuantizeLayer/DequantizeLayer 层的浮点 ONNX 网络,并遵循 显式量化规则 。有关差异的更多信息,请参阅 TensorRT 开发人员指南中的 显式量化与 PTQ 处理 。
TensorRT 量化工具箱
TensorRT ZCK4 的量化工具箱 通过提供一个方便的 PyTorch 库来补充 TensorRT ,该库有助于生成可优化的 QAT 模型。该工具包提供了一个 API 来自动或手动为 QAT 或 PTQ 准备模型。
API 的核心是 TensorQuantizer 模块,它可以量化、伪量化或收集张量的统计信息。它与 QuantDescriptor 一起使用,后者描述了如何量化张量。在 TensorQuantizer 之上分层的是量化模块,这些模块被设计为 PyTorch 全精度模块的替代品。这些是使用 TensorQuantizer 对模块的权重和输入进行伪量化或收集统计信息的方便模块。
API 支持将 PyTorch 模块自动转换为其量化版本。转换也可以使用 API 手动完成,这允许在不想量化所有模块的情况下进行部分量化。例如,一些层可能对量化更敏感,并且使其未量化可提高任务精度。

图 4 。 TensorRT 量化工具箱组件
在 NVIDIA 量子化 白皮书中详细描述了 QAT 的 TensorRT 特定配方,其中包括对量化方法的更严格的讨论,以及在各种学习任务上比较 QAT 和 PTQ 的实验结果。
代码示例演练
本节描述了工具箱中包含的分类任务量化 例子 。
QAT 的推荐工具箱配方要求从预训练模型开始,因为 展示 已经指出,从预训练模型开始并进行微调可以获得更好的精度,并且需要的迭代次数要少得多。在本例中,加载一个 预训练 ResNet50 模型 。从 bash shell 运行示例的命令行参数:

--data-dir 参数指向 ImageNet ( ILSVRC2012 )数据集,您必须分别使用 download 数据集。 --calibrator=histogram 参数指定在微调模型之前,应该使用直方图校准器对模型进行校准。其余的参数以及更多的参数都记录在示例中。
ResNet50 模型最初来自 Facebook 的 Torchvision 包,但是因为它包含一些重要的更改(跳过连接的量化),所以网络定义包含在工具箱中( resnet50_res )。有关详细信息,请参阅 Q / DQ 层布置建议 。
下面是代码的简要概述。
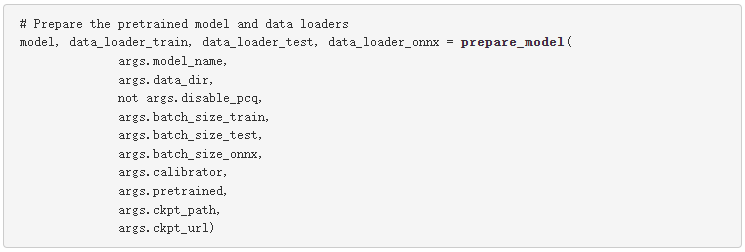
函数 prepare_model 像往常一样实例化数据加载器和模型,但它也配置量化描述符。举个例子:

QuantDescriptor 的实例描述了如何通过配置校准方法和量化轴来校准和量化张量。对于每个量化操作(例如 quant_nn.QuantConv2d ),您可以在 QuantDescriptor 中分别配置激活和权重,因为它们使用不同的伪量化节点。
然后在训练图中添加假量化节点。下面的代码( quant_modules.initialize )在幕后动态地修补 PyTorch 代码,以便将 torch.nn.module 的一些子类替换为它们的量化对应项,实例化模型的模块,然后还原动态修补程序( quant_modules.deactivate )。例如,将 torch.nn.conv2d 替换为 pytorch_quantization.nn.QuantConv2d ,其在执行 2D 卷积之前执行伪量化。应该在模型实例化之前调用方法 quant_modules.initialize 。

接下来,收集校准数据的统计信息( collect_stats ):将校准数据馈送到模型,并以直方图的形式收集每个层的激活分布统计信息以进行量化。收集直方图数据后,使用一个或多个校准算法( compute_amax )校准刻度( calibrate_model )。
在标定过程中,尽量确定每一层的量化尺度,以达到优化模型精度等目标。目前有两种校准器等级:
pytorch_quantization.calib.histogram – 使用熵最小化( KLD )、均方误差最小化( MSE )或百分位度量方法(选择动态范围,以表示指定的分布百分比)。
pytorch_quantization.calib.max – 使用最大激活值进行校准(表示浮点数据的整个动态范围)。
要在以后确定校准方法的质量,请在数据集上评估模型精度。该工具包可以很容易地比较四种不同校准方法的结果,以发现适用于特定模型的最佳方法。该工具包可以扩展专有的校准算法。有关更多信息,请参阅 ResNet50 示例笔记本 。
如果模型的精度令人满意,你不必继续进行 QAT 。您可以导出到 ONNX 并完成。这就是 PTQ 配方。 TensorRT 给出了具有量化尺度的 Q / DQ 算子的 ONNX 模型,并优化了模型进行推理。所以,这是一个 PTQ 工作流,它产生了一个 Q / dqonnx 模型。
要继续到 QAT 阶段,请选择最佳校准、量化模型。使用 QAT 对原始训练计划的 10% 左右进行微调,并使用退火学习率计划,最后导出到 ONNX 。有关更多信息,请参阅 深度学习推理的整数量化:原理与实证评价 白皮书。
导出到 ONNX 时,需要记住以下几点:
ONNX opset 13 中引入了每通道量化( PCQ ),因此如果您按照建议使用 PCQ ,请注意您使用的 opset 版本。
参数 do_constant_folding 应设置为 True ,以生成可读性更好的较小模型。

当模型最终导出到 ONNX 时,伪量化节点作为两个独立的 ONNX 操作符导出到 ONNX : QuantizeLinear 和 DequantizeLinear (如图 5 中的 Q 和 DQ 所示)。
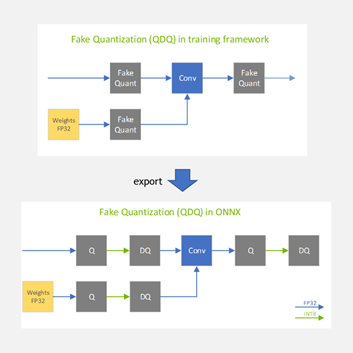
图 5 。伪量化运算符被转换为 Q/DQ PyTorch 模型导出到 ONNX 时的 ONNX 运算符
QAT 推断阶段
在高层次上, TensorRT 使用 Q / DQ 运算符处理 ONNX 模型,类似于 TensorRT 处理任何其他 ONNX 模型的方式:
TensorRT 导入包含 Q / DQ 操作的 ONNX 模型。
它执行一组专门用于 Q / DQ 处理的优化。
它继续执行常规优化过程。
它为推理执行构建了一个特定于平台的执行计划文件。此计划文件包含量化操作和权重。
除了启用 INT8 外,在 TensorRT 中构建 Q / DQ 网络不需要任何特殊的生成器配置,因为在网络中检测到 Q / DQ 层时,它会自动启用。使用 TensorRT 示例应用程序 trtexec 构建 Q / DQ 网络的最小命令如下:

TensorRT 使用称为 显式量子化 的特殊模式优化 Q / DQ 网络,这是出于对网络处理可预测性的要求和对用于网络操作的算术精度的控制。处理可预测性是保持原始模型计算精度的保证。其思想是, Q / DQ 层指定必须发生精度转换的位置,并且所有优化必须保留原始 ONNX 模型的算术语义。
对比 TensorRT Q / DQ 处理和普通 TensorRT INT8 处理有助于更好地解释这一点。在 plain TensorRT 中,使用 动态范围 API 或通过 校准过程 为 INT8 网络张量分配量化尺度。 TensorRT 在应用后端优化时将模型视为浮点模型,并使用 INT8 作为另一个工具来优化层执行时间。如果一个层在 INT8 中运行得更快,那么它被配置为使用 INT8 。否则,使用 FP32 或 FP16 ,以较快者为准。在这种模式下, TensorRT 只针对延迟进行优化,您几乎无法控制量化哪些操作。
相反,在显式量化中, Q / DQ 层指定必须发生精度转换的位置。优化器不允许执行非由网络指定的精度转换。即使这样的转换提高了层精度(例如,选择 FP16 实现而不是 INT8 实现),并且即使这样的转换会导致执行速度更快的计划文件(例如,在 V100 上, INT8 不被张量核加速时,首选 INT8 而不是 FP16 ),这也是正确的。
在显式量化中,您可以完全控制精度转换,并且量化是可预测的。 TensorRT 仍然优化性能,但要保持原始模型的算术精度。不支持在 Q / DQ 网络上使用动态范围 API 。
显式量化优化过程分为三个阶段:
首先,优化器尝试最大化模型的 INT8 数据,并使用 Q / DQ 层传播进行计算。 Q / DQ 传播是一组规则,指定 Q / DQ 层如何在网络中 MIG 速率。例如, QuantizeLayer 可以 MIG 通过与 ReLU 激活层交换位置来对网络的开始部分进行速率调整。通过这样做, ReLU 层的输入和输出激活减少到 INT8 精度,带宽需求减少 4 倍。
然后,优化器融合层来创建对 INT8 输入操作的量化操作,并使用 INT8 数学管道。例如, QuantizeLayer 可以与 ConvolutionLayer 融合。
最后, TensorRT 自动调谐器优化器搜索每一层的最快实现,同时也尊重该层指定的输入和输出精度。
有关 TensorRT 执行的主要显式量化优化的更多信息,请参阅 TensorRT 开发者指南 。
通过构建 TensorRT Q / DQ 网络创建的计划文件包含量化的权重和操作,可以部署。 EfficientNet 是需要 QAT 来保持准确性的网络之一。下表比较了 PTQ 和 QAT 。
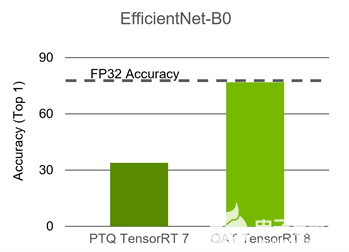
图 6 。 PTQ 和 QAT 上 EfficientNet-B0 的精确度比较
总结
在这篇文章中,我们简要介绍了基本的量化概念和 TensorRT 的量化工具箱,然后回顾了 TensorRT 8 。 0 是如何处理 Q / DQ 网络的。我们对量化工具箱提供的 resnet50qat 示例进行了快速演练。
ResNet50 可以用 PTQ 量化,不需要 QAT 。然而, EfficientNet 需要 QAT 来保持准确性。 EfficientNet B0 基线浮点 Top1 精度为 77 。 4 , PTQ Top1 精度为 33 。 9 , QAT Top1 精度为 76 。 8 。
关于作者
About Neta Zmora
Neta Zmora 是一位高级深度学习软件架构师,致力于 DL 加速。在 2020 年加入 NVIDIA 之前,内塔是英特尔人工智能实验室的研究工程师,负责开发深度神经网络压缩方法。
About Hao Wu
Hao Wu 是 NVIDIA 的高级 GPU 计算架构师。他在完成博士学位后于 2011 年加入 NVIDIA 计算架构组。在中国科学院。近年来, Hao 的技术重点是将低精度应用于深度神经网络训练和推理。
About Jay Rodge
Jay Rodge 是 NVIDIA 的产品营销经理,负责深入学习和推理产品,推动产品发布和产品营销计划。杰伊在芝加哥伊利诺伊理工学院获得计算机科学硕士学位,主攻计算机视觉和自然语言处理。在 NVIDIA 之前,杰伊是宝马集团的人工智能研究实习生,为宝马最大的制造厂使用计算机视觉解决问题。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
4994浏览量
103204 -
深度学习
+关注
关注
73文章
5504浏览量
121250
发布评论请先 登录
相关推荐
NVIDIA 在首个AI推理基准测试中大放异彩
NVIDIA TensorRT 8.2将推理速度提高6倍
NVIDIA TensorRT助力打造AI计算机视觉算法推理平台
NVIDIA Triton助力腾讯PCG加速在线推理
使用NVIDIA QAT工具包实现TensorRT量化网络的设计
NVIDIA T4 GPU和TensorRT提高微信搜索速度
NVIDIA TensorRT插件的全自动生成工具
蚂蚁链AIoT团队与NVIDIA合作加速AI推理
FP32推理TensorRT演示
学习资源 | NVIDIA TensorRT 全新教程上线

现已公开发布!欢迎使用 NVIDIA TensorRT-LLM 优化大语言模型推理

利用NVIDIA组件提升GPU推理的吞吐
魔搭社区借助NVIDIA TensorRT-LLM提升LLM推理效率
TensorRT-LLM低精度推理优化






 工商网监
工商网监
评论