 使用NVIDIA Riva实现将语音转录成文本
使用NVIDIA Riva实现将语音转录成文本
每天,电信、金融和统一通信即服务( UCaaS )等行业都会产生数百万分钟的音频。这些音频会议记录可以转录,以便为呼叫中心代理提供实时建议,从客户呼叫记录中提取见解,或在视频会议中生成实时字幕。

自动语音识别使您能够将语音转录成文本。生成高质量的文字记录是一项挑战,因为这些技能需要理解特定于行业的术语、数百到数千分钟特定于领域的培训音频以及实时运行的管道。 NVIDIA Riva 语音识别是一项技术,可为跨行业的几个常见用例提供世界级的实时准确度。
在这篇文章中,我们讨论 Riva 语音识别。后续文章将讨论如何定制语音识别模型,并将其作为优化技能进行部署:
Customizing Speech Recognition Models to Your Domain Using TAO Toolkit
Deploying Speech Recognition Models to Production Using Riva
Riva 语音识别
Riva 是 GPU 加速的 AI 语音 SDK ,用于实时转录和虚拟助理等对话 AI 应用程序。 Riva 具有以下优点:
NGC 中经过预训练的最先进的语音模型
没有编码工具,例如TAO Toolkit,用于在自定义数据集上微调这些模型
用于高性能推理的优化语音识别和语音合成管道
Riva 下面的模型是基于数百到数千小时的开放和真实世界数据进行训练的,这些数据来自电信、金融、医疗保健和 NVIDIA 超级计算机上的教育等行业。数据集样本还来自嘈杂的环境、自发的语音对话、多种英语口音和不同的采样率。所有这些属性都有助于生成噪声鲁棒、高质量的转录。
Riva 语音识别技能在各种真实世界的用例数据集上进行评估,包括视频会议、联络中心、播客和技术视频。您可以在云中、数据中心和边缘部署这些技能。
Riva 语音识别管道在保持准确性的同时,为新的最先进的体系结构提供支持。图 2 显示了在过去 3 年中,通过新的模型体系结构、训练方法以及最新的基于 TensorRT 和 GPU 的优化,语音准确性的提高。
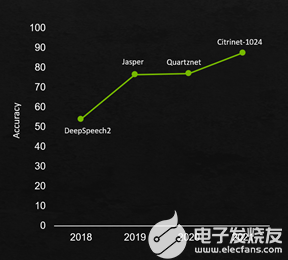
图 2 。 Riva ASR 精度改进
使用 Riva ,您可以在流式或批处理模式下以实时延迟快速部署和扩展到数百和数千个并发流。
关于作者
About Sirisha Rella
Sirisha Rella 是 NVIDIA 的技术产品营销经理,专注于计算机视觉、语音和基于语言的深度学习应用。 Sirisha 获得了密苏里大学堪萨斯城分校的计算机科学硕士学位,是国家科学基金会大学习中心的研究生助理。
About Tanay Varshney
Tanay Varshney 是 NVIDIA 的一名深入学习的技术营销工程师,负责广泛的 DL 软件产品。他拥有纽约大学计算机科学硕士学位,专注于计算机视觉、数据可视化和城市分析的横断面。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
4985浏览量
103027 -
语音识别
+关注
关注
38文章
1739浏览量
112650
发布评论请先 登录
相关推荐
NVIDIA推出全新生成式AI模型Fugatto
语音识别技术在医疗领域的应用
语音识别与自然语言处理的关系
ASR语音识别技术应用
基于Arm Neoverse N2实现自动语音识别技术
NVIDIA文本嵌入模型NV-Embed的精度基准
LM358如何实现将50HZ的方波转换为正弦波?
讯飞星火长文本功能全新升级
科大讯飞创新推出长文本、长图文、长语音大模型,解决落地难题
WT3000T8-TTS语音合成芯片及应用场景介绍
NVIDIA生成式AI研究实现在1秒内生成3D形状

MX生成文件touchGFX无法成功编译是哪里出了问题?
亚马逊发布史上最大文本转语音模型BASE TTS
网关可以实现将 Modbus TCP 接口设备连接到 Profinet 网络





 工商网监
工商网监
评论