 HugeCTR能够高效地利用GPU来进行推荐系统的训练
HugeCTR能够高效地利用GPU来进行推荐系统的训练
1. Introduction
HugeCTR 能够高效地利用 GPU 来进行推荐系统的训练,为了使它还能直接被其他 DL 用户,比如 TensorFlow 所直接使用,我们开发了 SparseOperationKit (SOK),来将 HugeCTR 中的高级特性封装为 TensorFlow 可直接调用的形式,从而帮助用户在 TensorFlow 中直接使用 HugeCTR 中的高级特性来加速他们的推荐系统。
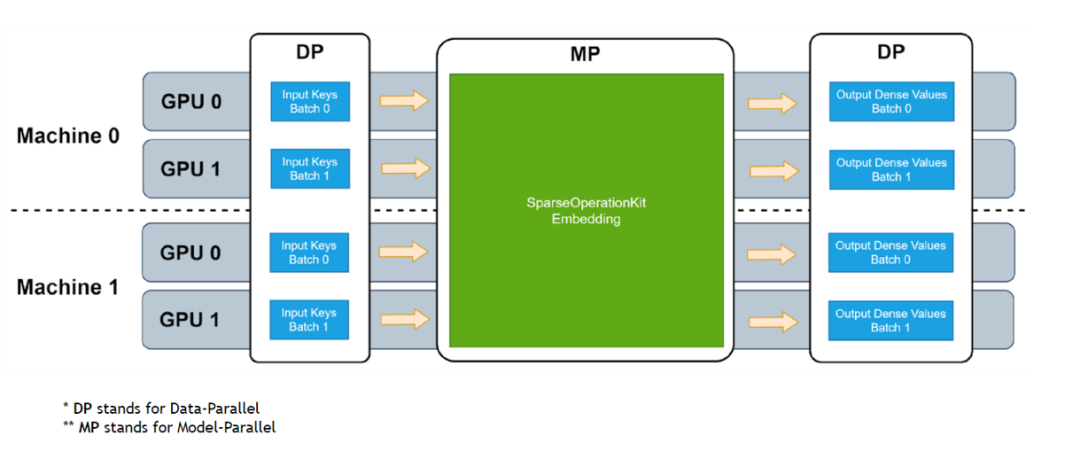
图 1. SOK embedding 工作流程
SOK 以数据并行的方式接收输入数据,然后在 SOK 内部做黑盒式地模型转换,最后将计算结果以数据并行的方式传递给初始 GPU。这种方式可以尽可能少地修改用户已有的代码,以更方便、快捷地在多个 GPU 上进行扩展。
SOK 不仅仅是加速了 TensorFlow 中的算子,而是根据业界中的实际需求提供了对应的新解决方案,比如说 GPU HashTable。SOK 可以与 TensorFlow 1.15 和 TensorFlow 2.x 兼容使用;既可以使用 TensorFlow 自带的通信工具,也可以使用 Horovod 等第三方插件来作为 embedding parameters 的通信工具。
使用 MLPerf 的标准模型 DLRM 来对 SOK 的性能进行测试。
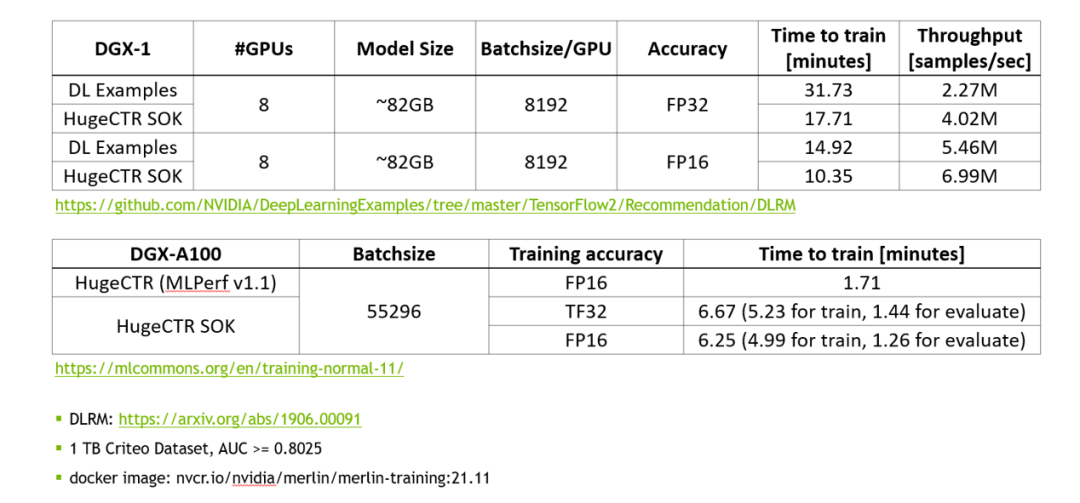
图 2. SOK 性能测试数据
相比于 NVIDIA 的 DeepLearning Examples,使用 SOK 可以获得更快的训练速度以及更高的吞吐量。
3. API
SOK 提供了简洁的、类 TensorFlow 的 API;使用 SOK 的方式非常简单、直接;让用户通过修改几行代码就可以使用 SOK。
1. 定义模型结构

左侧是使用 TensorFlow 的 API 来搭建模型,右侧是使用 SOK 的 API 来搭建相同的模型。使用 SOK 来搭建模型的时候,只需要将 TensorFlow 中的 Embedding Layer 替换为 SOK 对应的 API 即可。
2. 使用 Horovod 来定义 training loop

同样的,左侧是使用 TensorFlow 来定义 training loop,右侧是使用 SOK 时,training loop 的定义方式。可以看到,使用 SOK 时,只需要对 Embedding Variables 和 Dense Variables 进行分别处理即可。其中,Embedding Variables 部分由 SOK 管理,Dense Variables 由 TensorFlow 管理。
3. 使用 tf.distribute.MirroredStrategy 来定义 training loop

类似的,还可以使用 TensorFlow 自带的通信工具来定义 training loop。
4. 开始训练

在开始训练过程时,使用 SOK 与使用 TensorFlow 时所用代码完全一致。
4. 结语
SOK 将 HugeCTR 中的高级特性包装为 TensorFlow 可以直接使用的模块,通过修改少数几行代码即可在已有模型代码中利用上 HugeCTR 的先进设计。
审核编辑 :李倩
-
gpu
+关注
关注
28文章
4682浏览量
128624 -
SOK
+关注
关注
0文章
5浏览量
6325
原文标题:Merlin HugeCTR Sparse Operation Kit 系列之一
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
NPU与GPU的性能对比
PyTorch GPU 加速训练模型方法
使用EMBark进行大规模推荐系统训练Embedding加速

GPU深度学习应用案例
GPU服务器在AI训练中的优势具体体现在哪些方面?
苹果承认使用谷歌芯片来训练AI
SOK在手机行业的应用案例
电磁干扰训练系统原理是什么
llm模型训练一般用什么系统
如何利用Matlab进行神经网络训练
如何提高自动驾驶汽车感知模型的训练效率和GPU利用率
AI训练,为什么需要GPU?

FPGA在深度学习应用中或将取代GPU
应用大模型提升研发效率的实践与探索






 工商网监
工商网监
评论