 将NVIDIA Riva模型部署到生产中
将NVIDIA Riva模型部署到生产中
NVIDIA Riva 是一款 AI 语音 SDK ,用于开发实时应用程序,如转录、虚拟助理和聊天机器人。它包括 NGC 中经过预训练的最先进模型、用于在您的领域中微调模型的 TAO 工具包以及用于高性能推理的优化技能。 Riva 使使用 NGC 中的 Riva 容器或使用 Helm chart 在 Kubernetes 上部署模型变得更简单。 Riva 技能由 NVIDIA TensorRT 提供支持,并通过 NVIDIA Triton 提供服务推理服务器。
配置 Riva
在设置 NVIDIA Riva 之前,请确保您的系统上已安装以下设备:
Python [3 。 6 。 9]
docker ce 》 19 。 03 。 5
nvidia-DOCKR2 3 。 4 。 0-1 :Installation Guide
如果您按照第 2 部分中的说明进行操作,那么您应该已经安装了所有的先决条件。
设置 Riva 的第一步是到 install the NGC Command Line Interface Tool。
图 1 。安装 NGC CLI
要登录到注册表,您必须 get access to the NGC API Key。
图 2 。获取 NGCAPI 密钥
设置好工具后,您现在可以从 NGC 上的Riva Skills Quick Start资源下载 Riva 。要下载该软件包,可以使用以下命令(最新版本的命令可在前面提到的 Riva 技能快速入门资源中找到):

下载的软件包具有以下资产,可帮助您入门:
asr _ lm _工具:这些工具可用于微调语言模型。
nb _ demo _ speech _ api 。 ipynb :Riva 的入门笔记本。
Riva _ api-1 。 6 。 0b0-py3-none-any 。 whl和NeMo 2 Riva -1 。 6 。 0b0-py3-none-any 。 whl :安装 Riva 的滚轮文件和将 NeMo 模型转换为 Riva 模型的工具。有关更多信息,请参阅本文后面的Inferencing with your model部分。
快速启动脚本( Riva .*. sh , config 。 sh ):初始化并运行 Triton 推理服务器以提供 Riva AI 服务的脚本。有关更多信息,请参阅配置 Riva 和部署您的模型。
示例:基于 gRPC 的客户机代码示例。
配置 Riva 并部署您的模型
你可能想知道从哪里开始。为了简化体验, NVIDIA 通过提供一个配置文件,使用 Riva AI 服务调整您可能需要调整的所有内容,从而帮助您使用 Riva 定制部署。对于本演练,您依赖于特定于任务的 Riva ASR AI 服务。
对于本演练,我们只讨论一些调整。因为您只使用 ASR ,所以可以安全地禁用 NLP 和 TTS 。

如果您遵循第 2 部分的内容,可以将 use _ existing _ rmirs 参数设置为 true 。我们将在后面的文章中对此进行详细讨论。

您可以选择从模型存储库下载的预训练模型,以便在不进行自定义的情况下运行。

如果您在阅读本系列第 2 部分时有 Riva 模型,请首先将其构建为称为 Riva 模型中间表示( RMIR )格式的中间格式。您可以使用 Riva Service Maker 来完成此操作。 ServiceMaker 是一组工具,用于聚合 Riva 部署到目标环境所需的所有工件(模型、文件、配置和用户设置)。
使用riva-build和riva-deploy命令执行此操作。有关更多信息,请参阅Deploying Your Custom Model into Riva。

现在已经设置了模型存储库,下一步是部署模型。虽然您可以这样做manually,但我们建议您在第一次体验时使用预打包的脚本。快速启动脚本riva_init.sh和riva_start.sh是可用于使用config.sh中的精确配置部署模型的两个脚本。

运行riva_init.sh时:
您在config.sh中选择的模型的 RMIR 文件从指定目录下的 NGC 下载。
对于每个 RMIR 模型文件,将生成相应的 Triton 推理服务器模型存储库。此过程可能需要一些时间,具体取决于所选服务的数量和型号。
要使用自定义模型,请将 RMIR 文件复制到config.sh(用于$riva_model_loc)中指定的目录。要部署模型,请运行riva_start.sh。riva-speech容器将与从所选存储库加载到容器的模型一起旋转。现在,您可以开始发送推断请求了。
使用您的模型进行推断
为了充分利用 NVIDIA GPU s , Riva 利用了 NVIDIA Triton 推理服务器和 NVIDIA TensorRT 。在会话设置中,应用程序会优化尽可能低的延迟,但为了使用更多的计算资源,必须增加批大小,即同步处理的请求数,这自然会增加延迟。 NVIDIA Triton 可用于在多个 GPU 上的多个模型上运行多个推理请求,从而缓解此问题。
您可以使用 GRPCAPI 在三个主要步骤中查询这些模型:导入 LIB 、设置 gRPC 通道和获取响应。
首先,导入所有依赖项并加载音频。在这种情况下,您正在从文件中读取音频。我们在 examples 文件夹中还有一个流媒体示例。

要安装所有 Riva 特定依赖项,可以使用包中提供的。 whl 文件。
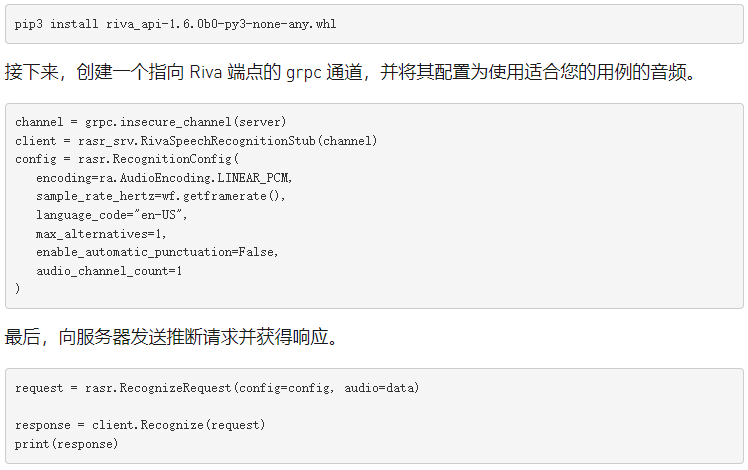
关键信息
此 API 可用于构建应用程序。您可以在单个裸机系统上安装 Riva ,并开始本练习,或者使用 Kubernetes 和提供的Helm chart进行大规模部署。
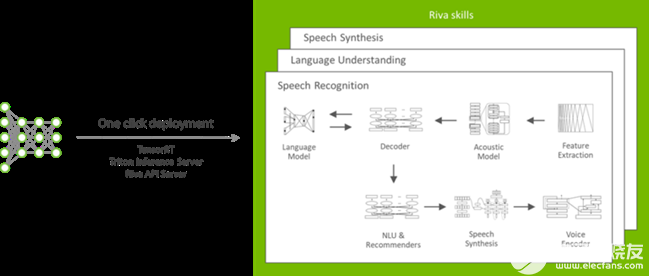
图 3 。 NVIDIA Riva 的典型部署工作流
使用此舵图,您可以执行以下操作:
从 NGC 中提取 Riva 服务 API 服务器、 Triton 推理服务器和其他必要的 Docker 映像。
生成 Triton 推理服务器模型库,并启动英伟达 Triton 服务器,并使用所选配置。
公开要用作 Kubernetes 服务的推理服务器和 Riva 服务器终结点。
结论
Riva 是一款用于开发语音应用程序的端到端 GPU 加速 SDK 。在本系列文章中,我们讨论了语音识别在行业中的重要性,介绍了如何在您的领域定制语音识别模型以提供世界级的准确性,并向您展示了如何使用 Riva 部署可实时运行的优化服务。
关于作者
About Tanay Varshney
Tanay Varshney 是 NVIDIA 的一名深入学习的技术营销工程师,负责广泛的 DL 软件产品。他拥有纽约大学计算机科学硕士学位,专注于计算机视觉、数据可视化和城市分析的横断面。
About Sirisha Rella
Sirisha Rella 是 NVIDIA 的技术产品营销经理,专注于计算机视觉、语音和基于语言的深度学习应用。 Sirisha 获得了密苏里大学堪萨斯城分校的计算机科学硕士学位,是国家科学基金会大学习中心的研究生助理。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
5087浏览量
103922 -
计算机
+关注
关注
19文章
7553浏览量
88799
发布评论请先 登录
相关推荐
NVIDIA推出面向RTX AI PC的AI基础模型
NVIDIA Cosmos世界基础模型平台发布
AI模型部署边缘设备的奇妙之旅:目标检测模型
测径仪 测测长仪是如何应用在卷烟生产中的?
NVIDIA NIM助力企业高效部署生成式AI模型
NVIDIA AI Foundry 为全球企业打造自定义 Llama 3.1 生成式 AI 模型

如何在tx2部署模型
英伟达推出AI模型推理服务NVIDIA NIM
NVIDIA NIM 革命性地改变模型部署,将全球数百万开发者转变为生成式 AI 开发者

Edge Impulse发布新工具,助 NVIDIA 模型大规模部署
牵手NVIDIA 元戎启行端到端模型将搭载 DRIVE Thor芯片





 工商网监
工商网监
评论