 NVIDIA RAPIDS加速器可将工作分配集群中各节点
NVIDIA RAPIDS加速器可将工作分配集群中各节点
借助适用于 Apache Spark 的 NVIDIA RAPIDS 加速器,团队能够更快处理数万亿条记录,在降低成本的同时优化网络并提高客户满意度。
AT&T 通过无线网络连接了从阿留申群岛到佛罗里达礁岛群的 1 亿多名用户,催生出一片大数据海洋。
Abhay Dabholkar 管理着一个研究小组,他们如同闪耀的灯塔,在数据海洋中寻找最佳导航工具。
作为在 AT&T 工作十余年的杰出 AI 架构师,Dabholkar 表示:“我们可以使用新工具来改变在 AT&T 的日常工作,这一过程十分有趣,并且当我们为员工提供最新的核心工具时,他们会对自己的工作感到更满意。”
近期,该团队在 GPU 助力的服务器上测试了适用于 Apache Spark 的 NVIDIA RAPIDS 加速器,该软件可将工作分配到集群中的各节点。
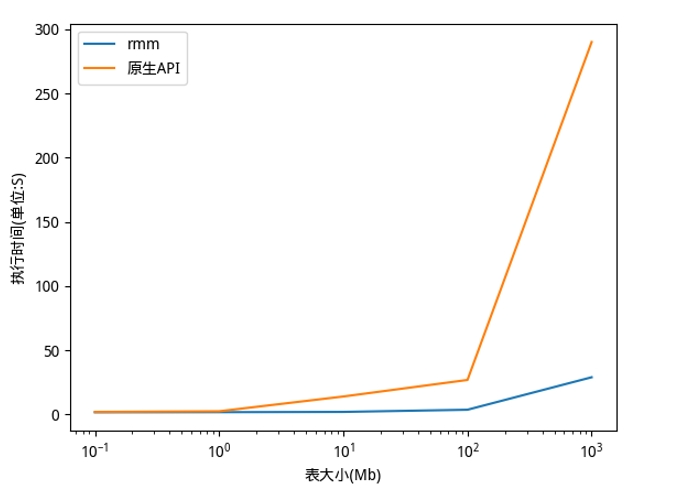
在本次测试中,仅 5 小时便处理完一个月的移动数据 - 2.8 万亿行信息。相较于先前的测试,速度提升 3.3 倍,而成本则降低 60%。
惊叹时刻
Dabholkar 表示:“这真是令人惊叹,因为在 CPU 集群上,仅处理 7 天的数据我们就需要耗费超过 48 小时的时间。过去尽管我们拥有数据,但却无法充分利用,因为处理这些数据需要很长时间。”
具体而言,该测试对所谓的 ETL(即提取、转换和加载流程)进行了基准测试,以便筛选出无用数据,然后再用筛选后的数据训练 AI 模型,发现全新见解。
他还表示:“目前我们认为 GPU 可用于 ETL 以及我们在 Spark 中执行的所有批处理工作负载,因此我们正在探索其他 RAPIDS 库,将工作从特征工程扩展到 ETL 和机器学习。”
目前 AT&T 在 CPU 服务器上运行 ETL,然后将数据转移至 GPU 服务器进行训练。他补充道,在单个 GPU 工作流中完成所有工作可以节省时间和成本。
提高客户满意度,加速网络设计
时间和成本的节省在众多用例中都有所体现。
例如,用户可以更快获取最佳连接,从而提高客户满意度并减少客户流失率。Dabholkar 表示:“我们还能更快确定 5G 信号塔和天线的参数。”
负责监督 RAPIDS 测试的团队高级成员 Chris Vo 表示,要确定在哪些 AT&T 光纤覆盖区域推出支持卡车,需要进行耗时的地理空间计算,而 RAPIDS 和 GPU 可以加速这一过程。
Dabholkar 说:“这项技术给我们带来极大影响,我们每天可能会收到 300-400TB 的新数据,先前需要耗费两三周以上的时间制作报告,而现在只需几小时便可完成。”
三个用例和统计结果
研究人员正在与 AT&T 数据平台团队成员分享他们的研究成果。
他说:“如果作业时间过长,且您拥有大量数据,我们建议您开启 GPU ,并借助 Spark,让在 CPU 上运行的代码也可以在 GPU 上运行。”
目前为止,各个团队在三个不同的用例中各有收获;其他团队也计划着测试其工作负载。
Dabholkar 乐观地表示,业务部门会将其测试结果引入生产系统中。
他说:“我们是一家拥有各类数据集的电信公司,每天都需要处理 PB 级数的数据,这种方法可以大大节省我们的时间和成本。”
此外,包括美国国家税务局在内的其他企业用户也纷纷选择使用这项技术。现有超过 13000 家公司(包括 400 家《财富》500 强公司)使用 Apache Spark,这表明大多数公司都愿意选择这种方式。
-
加速器
+关注
关注
2文章
809浏览量
38167 -
NVIDIA
+关注
关注
14文章
5087浏览量
103933 -
无线网络
+关注
关注
6文章
1444浏览量
66134
发布评论请先 登录
相关推荐
NVIDIA助力FinCatch开发智能投资辅助系统
重新分配pod节点


将NVIDIA加速计算引入Polars

RAPIDS cuDF将pandas提速近150倍

磁调制式电流传感器在粒子加速器中的应用
利用NVIDIA RAPIDS加速DolphinDB Shark平台提升计算性能
适用于数据中心应用中的硬件加速器的直流/直流转换器解决方案

ESP-MESH里面组网成功后各节点的softAP支持手机或者电脑等非MESH终端接入吗?
BUCK电路各节点电压怎么计算
基于FPGA的类脑计算平台 —PYNQ 集群的无监督图像识别类脑计算系统
NVIDIA 推出 Blackwell 架构 DGX SuperPOD,适用于万亿参数级的生成式 AI 超级计算

NVIDIA将在今年第二季度发布Blackwell架构的新一代GPU加速器“B100”






 工商网监
工商网监
评论