 通过全堆栈优化提升MLPerf v1.1的性能
通过全堆栈优化提升MLPerf v1.1的性能
自 v1.0 以来已经过去了五个月,所以是时候进行新一轮 MLPerf 培训基准了。在这个 v1.1 版本中,整个硬件和软件堆栈的优化看到了基于 NVIDIA 平台提交的基准测试套件的持续改进。这种改进在所有不同的尺度上都是一致的,从单个机器到工业超级计算机,例如由 560 个 NVIDIA DGX A100 系统组成的英伟达 SeleN 和由 768 个节点 A100 系统组成的微软 Azure NDM A100 V4 集群。
越来越多的组织使用MLPerf基准来指导其AI基础设施战略。MLPerf(VZX19的一部分)是由学术界、研究实验室和工业界的人工智能领导者组成的全球联盟,其使命是建立公平和有用的基准,为在规定条件下进行的硬件、软件和服务的培训和推理性能提供公正的评估。为了保持行业趋势的领先地位,MLPerf不断发展,定期举行新的测试,并添加代表AI最先进水平的新工作负载。
与前几轮的 MLPerf 基准测试一样,本文从技术上深入探讨了 NVIDIA 行业领先性能的优化工作。
为 MLPerf v0.7 培训优化 NVIDIA AI 性能
MLPerf v1.0 培训基准:了解创纪录的 NVIDIA 绩效
NVIDIA 继续披露并详细阐述这些技术细节,表明了其对公开和公平的社区驱动基准标准和实践这一重要问题的坚定承诺,以促进人工智能的公益性发展。
整个堆栈的优化
由于构建模块仍以目前成熟的NVIDIA A100GPU 、英伟达 DGX A100平台和NVIDIA SuperPod参考体系结构为中心,整个堆栈的优化,特别是在系统软件、库和算法方面的优化,导致 MLPerf v1.1 中基于 NVIDIA 的平台的性能不断提高。
与 1 年前我们自己提交的 MLPerf v0.7 相比,我们观察到芯片对芯片的改进高达 2.1 倍,最大规模培训的改进高达 5.3 倍,如表 1 所示。
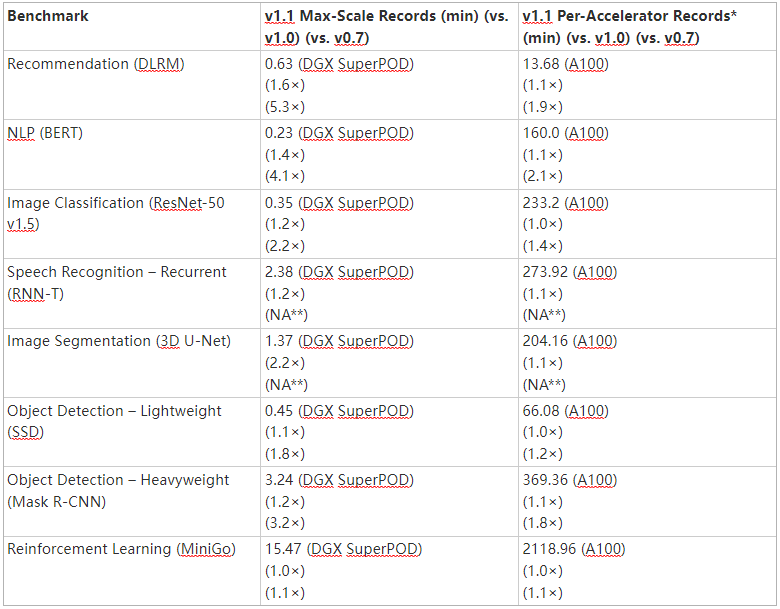
NVIDIA MLPERF v1.0 submission details :
根据加速器记录: BERT : 1.0-1033 | DLRM:1.0-1037 | Mask R-CNN:1.0-1057 | Resnet50 v1.5:1.0-1038 | SSD:1.0-1038 | RNN-T:1.0-1060 | 3D Unet:1.0-1053 | MiniGo:1.0-1061
最大刻度记录: BERT : 1.0-1077 | DLRM:1.0-1067 | Mask R-CNN:1.0-1070 | Resnet50 v1.5:1.0-1076 | SSD:1.0-1072 | RNN-T:1.0-1074 | 3D Unet:1.0-1071 | MiniGo:1.0-1075
NVIDIA MLPERF v1.1 submission details :
根据加速器记录: BERT : 1.1-2066 | DLRM:1.1-2064 | Mask R-CNN:1.1-2066 | Resnet50 v1.5:1.1-2065 | SSD:1.1-2065 | RNN-T:1.1-2066 | 3D Unet:1.1-2065 | MiniGo:1.1-2067
最大刻度记录: BERT : 1.1-2083 | DLRM:1.1-2073 | Mask R-CNN:1.1-2076 | Resnet50 v1.5:1.1-2082 | SSD:1.1-2070 | RNN-T:1.1-2080 | 3D Unet:1.1-2077 | MiniGo:1.1-2081 (*)
使用 NVIDIA 8xA100 服务器训练时间并乘以 8 (**)计算 A100 的每加速器性能。 U-Net 和 RNN-T 不是 MLPerf v0.7 的一部分。 MLPerf 名称和徽标是商标。有关更多信息,请访问 www.mlperf.org 。
下一节将介绍一些亮点。
CUDA 图
在 MLPerf v1.0 中,我们对大多数基准广泛使用 CUDA 图。 CUDA 图将多个内核作为单个可执行单元启动,通过最小化与 CPU 的通信来加快吞吐量。但每个图的范围只是一个完整迭代的一部分,该迭代处理单个小批量。因此,每次迭代分解为多个 CUDA 图时,只捕获了迭代的一部分。
在 MLPerf v1.1 中,我们使用 CUDA 图将整个迭代捕获到多个基准的单个图中,从而进一步减少培训期间与 CPU 的通信,并在规模上提高性能。这在 PyTorch 和 MXNet 基准测试中都得到了实现,从而使 ResNet-50 和 BERT 工作负载的性能提高了 6% 。
NCCL
NCCL 是NVIDIA Magnum IO 技术公司的一部分,它是优化服务器拓扑结构的 GPU 间通信的库。 NCCL 今年早些时候增加的一个关键特性是对 CUDA 图形的支持. 这使我们能够将整个迭代捕获为一个图,如前一节所述。
之前, NCCL 复制了图中的所有权重,并执行了一个 all REDUCT 函数,该函数将所有权重相加。然后将更新后的权重写回图形。这需要数据的多个副本。
我们现在引入了用户缓冲区注册, NCCL 集体使用指针,以避免在与可伸缩分层聚合和缩减协议(SHARP)一起使用时来回复制数据,该协议也是NVIDIA Magnum IO的一部分。在存在 CUDA 图和 SHARP 的情况下,我们观察到约 2% 的端到端额外加速。
NCCL 还实现了将缩放操作(乘以标量)融合到通信内核中以减少数据拷贝,从而在通信密集型网络(如 BERT )中额外节省约 3% 的端到端成本。
细粒重叠
在这一轮中,我们充分利用了 GPU 硬件的功能,使独立计算块能够在多个核之间进行细粒度的重叠,并增加了通信和计算的重叠。这提高了性能,尤其是最大规模的训练,在 Mask R-CNN 上提高了 10% ,在 DLRM 上提高了 27% 。
特别是对于 recommender systems benchmark ( DLRM ),我们利用软件和硬件的功能,通过重叠多个操作高效地使用 GPU 资源:
重叠嵌入索引计算和所有减少集体的前一次迭代
重叠数据梯度和权重梯度计算
增加了数学和其他多 GPU 集体的重叠,如全对全
对于 3D UNet ,空间并行性能通过更有效地调度数学和通信内核来提高,以增加两者的重叠。
对于掩模 R-CNN ,我们实现了掩模头、边界盒头和 RPN 头的损耗计算重叠,以提高 GPU 在规模上的利用率。
通过更高效的内存拷贝(矢量化)和内核中更好的通信和数学重叠,我们显著提高了多 GPU 组批处理规范( GBN )性能。这可以将工作负载扩展到 GPU 以上,从而为某些计算机视觉基准测试(如 ResNet50 和 SSD )节省 10% 以上的最大规模培训,为 3D UNet 节省 5% 以上的培训。
核融合与优化
最后,在这一轮 MLPerf 中,我们首次将偏差梯度缩减融合到矩阵乘法核中(两个操作的融合)。这将导致高达 3% 的性能改进。
模型优化细节
在本节中,我们将深入讨论每个工作负载上的优化工作。
BERT
在后向传递中将偏置梯度减少融合到矩阵乘法中
cuBLAS库最近引入了一种新的融合类型:在同一内核中融合偏置梯度计算和权重梯度计算。
在这一轮中,我们使用 cuBLAS 功能在向后传球中融合这两个操作。我们还在正向传递中融合了偏置加法和矩阵乘法。图 1 显示了向前传球和向后传球的融合操作。
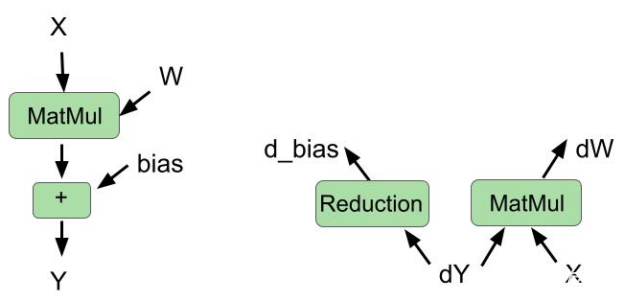
图 1 。在前向传递(左)和后向传递(右)中将其他操作与矩阵乘法融合
改进的融合多头注意
在上一轮中,我们实现了多头注意模块的融合。此模块跨num_sequences和num_heads变量使用并行性。这意味着在 GPU 上的不同流式多处理器( SMs )上同时调度的num_sequences*num_heads线程块总数。num_heads在 MLPerf BERT 模型中为 16 ,并且当num_sequences小于 6 时,没有足够的线程块填充 GPU ,从而限制了并行性。
在这一轮中,我们通过在注意力计算所需的批量矩阵乘法的序列维度上引入slicing来改进这些内核,这有助于按比例提高并行性。这种优化使最大规模的训练场景的端到端加速约 8% ,其中每芯片批量较小。
使用 CUDA 图捕获完整迭代图
正如前面关于communications library图的部分所提到的,在这一轮中,我们将 BERT 的完整迭代捕获到单个 CUDA 图中。这是因为 CUDA NCCL 中支持 CUDA 图形,以及PyTorch 框架. 由于 CPU 延迟和抖动在规模上有所减少,因此端到端节省了约 3% 。除此之外,在使用 CUDA 图时,我们还利用了 NCCL 用户缓冲区预注册功能,从而使端到端性能提高了约 2% 。
将模型参数缓冲区设置为指向连续平面缓冲区
BERT 使用分布式优化器加快优化步骤。为了获得最佳的全聚集性能,分布式优化器中用于权重参数的中间缓冲区都应该是单个连续平面缓冲区的一部分。通过这种方式,我们可以更好地使用 GPU 互连,而不是在小的独立张量上运行多个 all gather 函数,方法是为一条大消息运行 all gather 。
另一方面,默认情况下, PyTorch 为前向传递期间使用的每个模型参数张量分配单独的缓冲区。这需要一个额外的“取消平台”步骤,如图 2 所示,在迭代结束和下一个迭代开始之间。
在这一轮 MLPerf 中,我们使用了一个单独的连续缓冲区,其中每个参数张量作为一个大缓冲区的一部分彼此相邻放置。这样就不需要额外的取消缓冲步骤,如图 2 所示。这种优化可在最大规模配置下为 BERT 节省约 4% 的端到端性能,其中优化器和参数拷贝的成本最为显著。
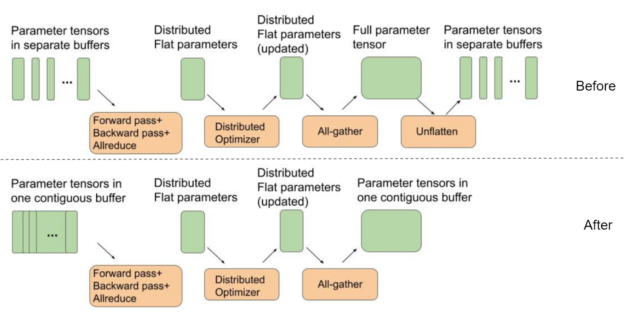
Figure 2.在优化前后迭代的几个不同步骤之间,参数张量是如何在内存中表示的。
DLRM
HugeCTR是 NVIDIAMerlin的一部分,是一个推荐系统专用培训框架,它继续支持 NVIDIA DLRM 提交。
混合嵌入索引预计算
在上一轮 MLPerf 中,我们实现了hybrid embedding,以减少 GPU 之间的通信。
尽管 HugeCTR 中实现的混合嵌入显著减少了通信量,但它需要计算索引以确定在何处读取和分发存储在每个 GPU 上的嵌入向量。索引计算仅依赖于输入数据,这些数据在前面的几次迭代中被预取到 GPU 上。因此,在 Hugetr 中,索引预计算被用作优化,以隐藏在上一次迭代的通信内核下计算索引的成本。
与训练迭代中的索引预计算相同,用于评估的混合嵌入索引可以在第一次执行评估时计算和缓存。它们可以在剩余的评估中重复使用,这完全消除了为后续评估计算指数的成本。
通信和计算之间的更好重叠
在 DLRM 中,为了促进模型并行训练,在前进和后退阶段分别需要两个全对全集体。此外,在模型的数据并行部分的培训结束时,还有一个 all REDUCT 集合。如何将计算与这些通信集体重叠是实现 GPU 的高利用率和高训练吞吐量的关键。为了实现更好的重叠,进行了一些优化。图 3 显示了一次培训迭代的简化时间表。
在前向传播阶段,执行底部 MLP ,同时将所有内核转发到所有内核,等待数据到达。在反向传播阶段, all REDUCT 和 all to all 重叠以提高网络的利用率。索引预计算还计划与这两个通信集体重叠,以使用 GPU 上的空闲资源,最大限度地提高训练吞吐量。
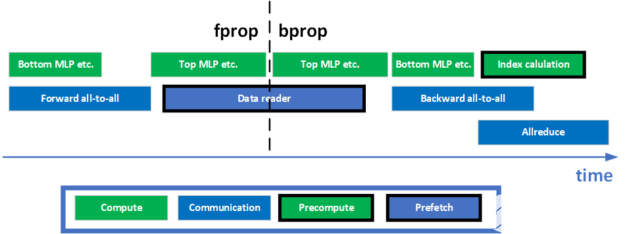
图 3 。训练迭代的简化时间轴视图,说明计算和通信操作的细粒度重叠。
异步权重梯度计算
MLP 的数据梯度计算和权重梯度计算是共享相同输入的两个独立计算分支。与数据梯度不同,在梯度全部减小之前,不需要权重梯度。由于 GPU 在调度内核方面的灵活性,这两个计算在 HUGETR 中并行执行,最大限度地提高了 GPU 的利用率。
更好的融合
内核融合是一种有效的方法,可以减少对内存的访问,提高 GPU 利用率。以前, DLRM 中利用了许多融合模式来实现更好的性能。例如,数据梯度计算、 ReLU 反向操作和偏置梯度计算可以通过 cuBLAS 在 HugeCTR 中融合在一起。这样的跨层融合模式使得最后一次偏置梯度计算未被使用。
在这一轮中,利用 cuBLAS 中支持的 GEMM 和偏置梯度融合,将偏置梯度计算融合到 MLP 最后一层的权重梯度计算中。
另一个融合示例是权重转换融合。为了支持混合精度训练,训练期间必须将 FP32 主砝码转换为 FP16 砝码。作为优化,该精密铸造与 Hugetr 中的 SGD optimizer 融合。每当更新 FP32 主权重时,它都会将更新权重的 FP16 版本写入内存,从而无需单独的内核进行转换。
面具 R-CNN
在这一轮中,为所有卷积层切换到 NHWC 布局,使用专用评估节点,并改进损耗计算重叠,为掩码 R-CNN 工作负载提供了最大的改进。
对所有卷积层使用 NHWC 布局
ResNet-50 主干网已经使用 NHWC 布局很长一段时间了,但该型号的其余部分直到现在都使用 NCHW 。
这一轮我们能够将 FPN 模块(紧跟在 ResNet-50 主干之后)切换到 NHWC 。在 NHWC 中运行 FPN 意味着我们可以转置输出而不是输入,这更有效,因为输入比输出大得多。这一变化将最大规模配置的性能提高了 4-5% 。
使用专用节点专门评估多节点场景
虽然评估与培训重叠,但 Mask R-CNN 评估是一个资源密集型过程。当评估同时进行时,培训绩效不可避免地会受到轻微影响。对于最大规模配置,评估所需时间几乎与培训所需时间相同。在后台持续运行评估显著影响培训绩效。
克服此问题的一种方法是使用一组单独的节点进行评估,即一组节点进行培训,一组较小的节点进行评估。对最大规模配置实施此更改将端到端性能提高了 12% 。
使用多线程 COCO 评估
COCO 求值函数消耗了大部分求值时间,并分别在边界框和分割掩码结果上运行。几轮之前,我们通过在多个进程中运行这两个评估调用来重叠这两个评估调用。
这一轮,我们为 COCO 评估循环启用了 openmp 多线程处理。这是 COVIAPI 软件英伟达版中的一个可选特性。通过提供指定所需线程数的可选参数,可以并行化求值循环。此优化将评估速度提高了约 10% ,但仅显示最后一次评估,因此对端到端时间的影响要小得多,约为 0.5% 。
小批量运行占用率四倍的两阶段 top-K 计算
我们在 Mask R-CNN 打了几个 top-K 电话,由于占用率低,需要很长时间。 top-K 内核启动的协作线程阵列或 CTA (线程块)的数量与每 GPU 批大小成比例。最大规模配置使用的每 – GPU 批大小为 1 ,这导致仅启动五个 CTA 。每个 CTA 分配一个 SMs ,而 A100 有 100 多个 SMs ,这表明 GPU 的利用率较低。
为了缓解这种情况,我们实施了两阶段方法:
在第一阶段,我们将输入分成四个相等的部分,然后通过一个调用对每个部分执行 top-K 。
在第二阶段,我们将四个临时结果连接起来,并取其中的 top-K 。
这将产生与以前相同的结果,但运行速度快 3 倍以上,因为我们现在在第一阶段推出了 20 个 CTA ,而不是 5 个。进一步划分输入会使第一阶段更快,但也会使第二阶段更慢。
将输入分成八种方式,而不是四种方式,这意味着在第一阶段将启动 40 个 CTA ,而不是 20 个。第一阶段只需一半的时间就可以完成,但不幸的是,第二阶段的速度太慢了,采用四向分割的方式,整体性能会更好。对最大规模配置实施四向拆分可使性能提升 3-4% 。
遮罩头部、边界盒头部和 RPN 头部的重叠损失计算
Mask R-CNN 推出的大多数 GPU 内核在批量较小时占用率较低。缓解这种情况的一种方法是尽可能多地重叠执行内核,以利用 GPU 资源,否则这些资源就会闲置。
一些损失计算可以同时进行。对于遮罩水头损失、边界框损失和 RPN 水头损失,这是正确的,因此我们将这三个损失计算分别放在不同的 CUDA 流上,以便它们可以同时执行。这将最大规模配置的性能提高了约 5% 。
三维 UNet
矢量化连接和拆分操作
3D UNet 使用连接操作连接解码器和编码器激活。这将导致在向前和向后传递中为激活张量生成设备到设备的副本。我们通过使用矢量化加载和存储优化了这些拷贝,执行了 4 倍宽的读/写操作。这使 concat 和 split 操作符的速度提高了 2.4 倍以上,在单节点配置下,端到端的加速比为 4.7% ,在最大规模配置下,端到端的加速比为 1.3% 。
高效空间并行卷积
在 MLPerf v1.0 中,我们引入了空间并行卷积,在这里我们将输入激活拆分为多个 GPU (准确地说是 8 )。空间并行卷积的实现使我们能够将晕交换隐藏在卷积后面的卷积后面。
在 MLPerf v1.1 中,我们优化了通信和卷积操作的调度,以便在启动的通信和卷积内核之间获得更好的重叠。虽然这确保了光晕交换不会暴露,但也有助于显著降低抖动。此优化调度将最大规模配置的分数提高了 25% 以上。

图 4 。空间并行卷积:完全隐藏在卷积后面的光晕转移
空间并行损耗计算
3D Unet 使用骰子损失和 Softmax 交叉熵损失作为其损失函数。骰子损失定义为以下公式:
在此公式中,Pi和Gi分别表示预测和地面真实的对应像素值对。
在最大比例配置中,由于单个 GPU 仅作用于图像的一个切片,因此每个 GPU 仅包含Pi和Gi的一个切片。为了优化损耗计算,我们独立计算了每个 GPU 中的部分项,并通过 NVLink 在组中的所有 GPU 之间交换部分项。然后将这些部分项组合起来,形成骰子损失结果。这将损失计算速度提高了 4 倍以上,最大规模分数提高了 7% 。
更好的配置
我们将全局批处理大小增加为数据集大小的一个因素。 DALI 数据加载器库使我们能够使用同一个碎片为不同的时代进行训练。这使我们能够显著减少在 GPU 中缓存数据集所需的时间。
由于每个 GPU 加载的图像要少得多,因此 DALI 中的边界框缓存升温速度也要快得多。此优化显著缩短了启动时间,并使 MLPerf v1.0 的加速比提高了 20% 。
数据并行异步计算
随着培训速度的加快,隐藏在培训背后的规模评估变得具有挑战性。在 MLPerf v1.1 中,单个图像上的推断在 GPU 上分片,以改进评估比例。然后收集所有推断结果,形成最终输出。这使得整个评估阶段可以隐藏在培训迭代之后。
更快的组实例规范
多 GPU InstanceRM 内核通过并行化多通道块的 GPU 间通信和通过矢量化内存读写来减少内核的 DRAM 时间而得到了显著改进。这使得最大规模配置的吞吐量提高了 5% 以上。
ResNet-50
端到端 CUDA 图
对于 ResNet-50 ,当基准扩展到> 256 个节点时,每 GPU 批大小减小到一个非常小的值,其中迭代时间仅为~ 8-10ms 。在这些非常小的迭代时间内,确保 GPU 执行中没有因 CPU 上运行的依赖项而产生的间隙是至关重要的。
对于 MLPerfV1.1 ,我们通过使用端到端技术减少了规模上的抖动CUDA 图为了捕获整个前向过程中的迭代,后向过程、优化器和 Horovord / NCCL 梯度都减少为单个图形。 CUDA 图的使用在最大规模的培训中提供了 6% 的性能优势。
GBN
随着 ResNet50 规模的增加和本地批量的减少,为了实现尽可能快的收敛,我们使用 GBN 技术。对于每个 BatchNorm 层,在 GPU 组中,均数和方差均减少。
对于 MLPerf v1.1 ,通过并行化多个通道块的 GPU 间通信,并通过矢量化内存读写来减少内核的 DRAM 时间,单个 DGX 节点内的 GBN 性能得到了显著改善。这在规模上提供了 10% 的性能优势。
固态硬盘
打开 – GPU 图像缓存
图像网络大量使用图像裁剪和调整大小来捕获表示数据集更丰富统计信息的特征,并提高模型的泛化能力。
在以前的MLPRF回合中,SSD使用英伟达数据加载库 (DALI) 图像解码特征来解码JPG图像的裁剪区域。此功能可避免在解码整个图像时浪费时间,尤其是在裁剪较小的情况下。
但是,这意味着该裁剪图像只使用一次,因为该图像未缓存在内存中。原始图像的未来使用可能会有不同的裁剪区域,这意味着每次使用原始图像时都会对其进行解码。这种行为会导致 GPU 之间的抖动,因为解码成本随裁剪所需区域的大小变化很大。这在扩展场景中尤其明显。
在这一轮中,我们利用了每个 NVIDIA A100 80-GB GPU 可用的 80-GB 内存容量,使用另一个 DALI 功能对整个图像进行解码并将其缓存在内存中。这使得将来可以使用相同的图像来避免解码成本,而是直接从内存中拾取裁剪区域。这样做比每次解码裁剪区域更便宜,并且运行时间和设备到设备的执行时间差异要小得多。
总体而言,该优化使单节点配置的端到端性能提高了 2% ,有效规模配置提高了约 5% ,规模介于单节点和最大规模之间。
用于 SSD 的 GBN ,
SSD 还利用了在 ResNet-50 中实现的 GBN 改进,在我们的最大规模配置中提供了约 4% 的 E2E 改进。
RNN-T
更优化的顶点传感器
apex中的传感器模块已进一步优化,以提高训练吞吐量。传感器接头和传感器损耗模块分别增加了两个优化。
传感器接头、 ReLU 和 dropout 是 RNN-T 中三个连续的内存绑定操作。作为优化, ReLU 和 dropout 已与 apex 中apex.contrib.transducer.TransducerJoint模块中的传感器接头融合,有效地减少了到内存的跳闸。
传感器损耗的反向传播是一种内存密集型操作。 apex 中的apex.contrib.transducer.TransducerLoss中添加了一项优化,对反向操作中的加载和存储进行矢量化,从而提高了内核的内存带宽利用率。
GPU 上的更多数据预处理
当 GPU 忙于向前和向后传递时,在 CPU 上预处理下一批数据可能会隐藏数据预处理时间。这是理想的。但是,当数据预处理是计算密集型的时, CPU 上的预处理时间可能会暴露出来。
DALI 可以利用 GPU 的大规模并行处理特性,通过计算 GPU 上的部分预处理来帮助卸载 CPU 。在本文中,静默修剪操作被移动到 GPU ,从而提高了训练吞吐量。
结论
基于成熟且经验证的 NVIDIA A100 GPU 和 NVIDIA DGX A100 平台,在这一轮 MLPerf v1.1 培训基准中,跨堆栈优化继续为基于 NVIDIA 平台的提交提供全面的性能改进。
值得重申的是,英伟达平台是唯一的解决方案,提交所有工作负载在 MLPRF 基准套件,展示了业界领先的性能和通用性。
所有用于 NVIDIA 提交的软件都可以从 MLPerf 存储库中获得,以使您能够重现我们的基准测试结果。我们不断地将这些尖端的 MLPerf 改进添加到NGC上提供的深度学习框架容器中,这是我们针对 GPU 优化应用程序的软件中心。
关于作者
Vinh Nguyen 是一位深度学习的工程师和数据科学家,发表了 50 多篇科学文章,引文超过 2500 篇。在 NVIDIA ,他的工作涉及广泛的深度学习和人工智能应用,包括语音、语言和视觉处理以及推荐系统。
Sukru Burc Eryilmaz 是 NVIDIA 计算机体系结构的高级架构师,他致力于在单节点和超级计算机规模上改进神经网络训练的端到端性能。他从斯坦福大学获得博士学位,并从比尔肯特大学获得学士学位。
Karthik Mandakolathur 是 NVIDIA Magnum IO 的产品经理,专注于加速分布式 AI 、数据分析和 HPC 应用。凭借 20 多年的行业经验, Karthik 曾在 Broadcom 和 Cisco 担任高级工程和产品职务。他在沃顿商学院获得工商管理硕士学位,在斯坦福大学获得工商管理硕士学位,在印度理工学院获得工商管理学士学位。他在高性能交换架构领域拥有多项美国专利。
About Shar Narasimhan
Shar Narasimhan 是 AI 的高级产品营销经理,专门从事 NVIDIA 的 Tesla 数据中心团队的深度学习培训和 OEM 业务。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
5025浏览量
103268 -
gpu
+关注
关注
28文章
4754浏览量
129074 -
MLPerf
+关注
关注
0文章
35浏览量
647
发布评论请先 登录
相关推荐
RAID 5 性能优化技巧
NPU技术如何提升AI性能
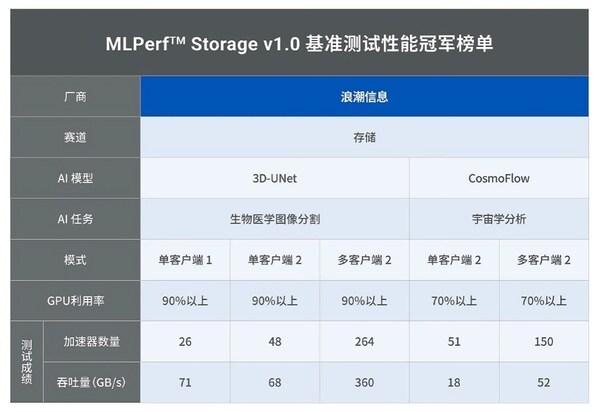
浪潮信息AS13000G7荣获MLPerf™ AI存储基准测试五项性能全球第一
堆栈和内存的基本知识
如何使用Polyspace Code Prover来统计堆栈
RaftKeeper v2.1.0版本发布,性能大幅提升!
Module LoRa433 v1.1 | 410-525MHz频段LoRa通信模块

Module LoRa868 v1.1 | 803-930MHz高频段LoRa通信模块
SBS v1.1兼容气体压力计IC bq2060A数据表

SBS V1.1兼容气体表IC bq2060SBS数据表





 工商网监
工商网监
评论