 NVIDIA DRIVETMPX自动驾驶汽车的端到端学习
NVIDIA DRIVETMPX自动驾驶汽车的端到端学习
在一个新的汽车应用程序中,我们使用了 卷积神经网络 ( CNNs )来映射从前置摄像头到自动驾驶汽车的转向命令的原始像素。这种强大的端到端方法意味着,只要从人类那里获得最少的训练数据,系统就可以学会在当地道路和高速公路上使用或不使用车道标线进行转向。该系统还可以在视觉引导不清晰的区域运行,如停车场或未铺路面的道路。
我们设计了一个端到端的学习系统,使用 NVIDIA 开发箱 运行的 Torch 7 进行培训。安NVIDIA DRIVETMPX自动驾驶汽车电脑,也与 Torch 7,是用来确定在哪里驾驶时,以 30 帧每秒( FPS )。该系统训练成仅以人的转向角为训练信号,自动学习必要处理步骤的内部表示,例如检测有用的道路特征。我们从来没有明确地训练它去探测,例如,道路的轮廓。与使用显式分解问题的方法(如车道标记检测、路径规划和控制)相比,我们的端到端系统同时优化所有处理步骤。
我们相信端到端的学习可以带来更好的性能和更小的系统。更好的性能结果是因为内部组件自我优化来实现最大化系统性能,而不是优化人为选择的中间标准,例如车道检测。可以理解的是,选择这样的标准是为了便于人理解,而这并不能自动保证最大的系统性能。更小的网络是可能的,因为系统学会用最少的处理步骤来解决问题。
用卷积神经网络处理视觉数据
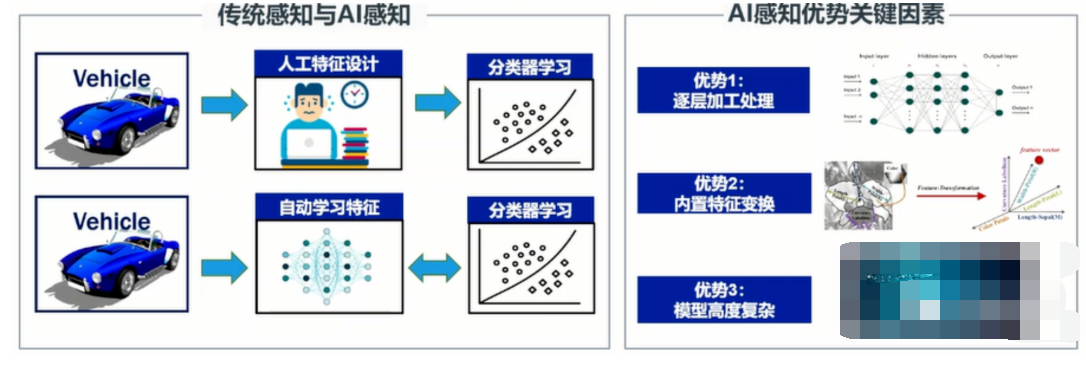
CNNs使计算模式识别过程发生了革命性的变化 ,在 CNNs 被广泛采用之前,大多数模式识别任务都是在最初阶段使用手工制作的特征提取和分类器来完成的。 CNNs 的一个重要突破是特征可以从训练样本中自动学习。 CNN 方法在应用于图像识别任务时特别强大,因为卷积运算捕捉图像的 2D 特性。通过使用卷积核来扫描整个图像,与操作总数相比,需要学习的参数相对较少。
而具有学习特性的 cnn 已经在商业上使用了二十多年近年来,由于两个重要的发展,它们的采用呈爆炸式增长。首先,像 ImageNet 大规模视觉识别挑战( ILSVRC ) 这样的大型标记数据集现在已经广泛用于培训和验证。第二, CNN 学习算法现在在大规模并行图形处理单元( GPUs )上实现,极大地提高了学习和推理能力。
我们在这里描述的 cnn 超越了基本的模式识别。我们开发了一个系统来学习驾驶汽车所需的整个处理流程。这个项目的基础工作实际上是在 10 年前国防高级研究计划局( DARPA )的苗木项目中完成的,这个项目被称为 DARPA 自动车辆( DAVE ),在这个项目中,一辆小规模无线电控制( RC )车开过一条垃圾堆满的小巷。戴夫接受的训练是在相似但不完全相同的环境中驾驶人的时间。训练数据包括来自两台摄像机的视频和一名操作员发出的转向指令。
在很多方面,戴夫受到了波默洛的开创性工作的启发他于 1989 年在一个神经网络( ALVINN )系统中制造了自动陆地车辆。 ALVINN 是 DAVE 的先驱,它提供了一个概念的初步证明,即有一天,一个端到端训练的神经网络 MIG ht 能够在公共道路上驾驶汽车。 DAVE 展示了端到端学习的潜力,并确实被用来证明启动 DARPA 学习应用于地面机器人( LAGR )项目 ,但是戴夫的表现不够可靠,不足以提供一个完整的替代方案,更模块化的越野驾驶方法。( DAVE 在复杂环境中的平均相撞距离约为 20 米。)
大约一年前,我们开始了一项新的工作来改进原来的 DAVE ,并创建了一个在公共道路上行驶的强大系统。这项工作的主要动机是避免需要识别特定的人类指定特征,如车道标记、护栏或其他汽车,并避免创建“如果,那么,“ else ”规则,基于对这些特征的观察。我们很高兴与大家分享这项新工作的初步成果,这项工作的名称很恰当: DAVE – 2 。
DAVE-2 系统
图 2 显示了 DAVE-2 训练数据采集系统的简化框图。三个摄像头安装在数据采集车的挡风玻璃后面,摄像头的时间戳视频与驾驶员施加的转向角同时捕获。通过接入车辆控制器局域网( CAN )总线获得转向指令。为了使我们的系统独立于车辆的几何结构,我们将转向命令表示为 1 / r ,其中 r 是转弯半径,单位为米。我们使用 1 / r 而不是 r 来防止直线行驶时出现奇点(直线行驶的转弯半径是无穷大)。 1 / r 从左转弯(负值)平稳过渡到右转弯(正值)。
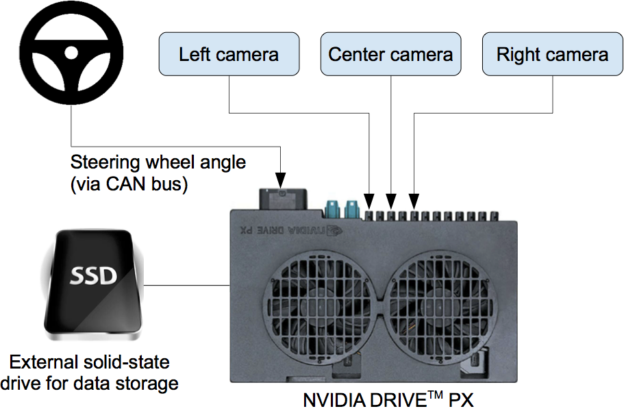
图 2 :数据收集系统的高级视图。
训练数据包含从视频中采样的单个图像,与相应的转向指令( 1 / r )配对。仅仅使用人类驾驶员的数据进行培训是不够的;网络还必须学会如何从任何错误中恢复,否则汽车将慢慢偏离道路。因此,训练数据被附加的图像增强,这些图像显示了汽车从车道中心的不同位移和从道路方向的旋转。
两个特定的偏离中心偏移的图像可以从左右摄像机获得。通过对来自最近摄像机的图像进行视点变换,模拟摄像机之间的附加位移和所有旋转。精确的视点变换需要我们没有的三维场景知识,所以我们假设地平线以下的所有点都在平地上,地平线以上的所有点都是无限远的,来近似地进行变换。对于平坦的地形,这很好,但是对于更完整的渲染,它会对粘在地面上的对象(如汽车、电线杆、树木和建筑物)引入扭曲。幸运的是,这些扭曲并没有给网络培训带来重大问题。变换后的图像的转向标签会快速调整为在两秒钟内将车辆正确地转向到所需的位置和方向。
图 3 显示了我们的培训系统的框图。图像被输入 CNN ,然后由 CNN 计算出建议的转向指令。将提出的命令与该图像的所需命令进行比较,并调整 CNN 的权重以使 CNN 输出更接近所需的输出。重量调整是通过在 Torch 7 机器学习包中实现的反向传播来完成的。
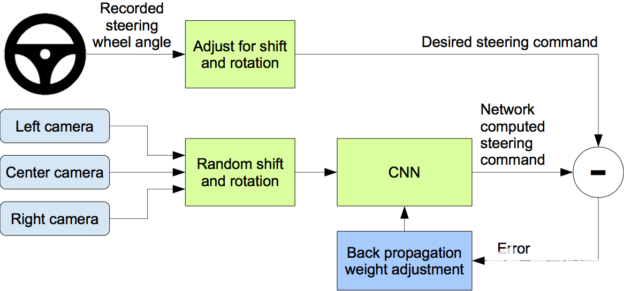
图 3 :训练神经网络。
一旦经过训练,网络就能够从单中心摄像机的视频图像中生成转向指令。图 4 显示了这个配置。
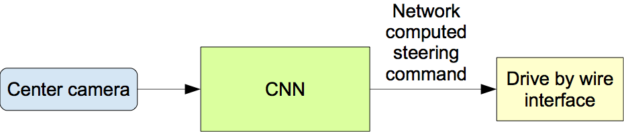
图 4 :训练后的网络用于从单个前置中心摄像头生成转向命令。
数据收集
培训数据是通过在各种各样的道路上以及在不同的照明和天气条件下驾驶来收集的。我们收集了来自新泽西州,伊利诺伊州和新泽西州的数据。其他道路类型包括双车道道路(带和不带车道标线)、有停车场的住宅道路、隧道和未铺面道路。数据收集在晴朗,多云,雾,雪和雨的天气,白天和晚上。在某些情况下,太阳在天空中很低,导致眩光从路面反射并从挡风玻璃上散射。
这些数据是通过我们的线控测试车( 2016 款林肯 MKZ )或 2013 款福特福克斯( Ford Focus )获得的,该车的摄像头位置与林肯车相似。我们的系统不依赖于任何特定的车辆品牌或型号。司机们被鼓励保持全神贯注,但在其他方面,他们通常会这样开车。截至 2016 年 3 月 28 日,收集了大约 72 小时的驾驶数据。
网络体系结构
我们训练网络的权值,以使网络输出的转向命令与人类驾驶员的指令或偏离中心和旋转图像的调整后的转向指令之间的均方误差最小化(见后面的“增强”)。图 5 显示了网络体系结构,它由 9 个层组成,包括一个规范化层、 5 个卷积层和 3 个完全连接的层。将输入的图像分割成 YUV 。
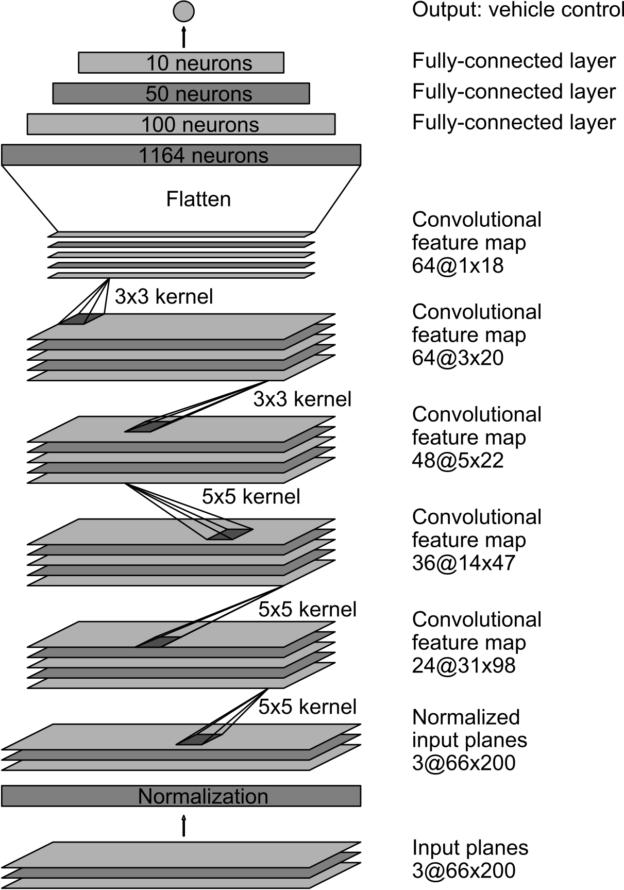
图 5 : CNN 架构。这个网络有大约 2700 万个连接和 25 万个参数。
网络的第一层执行图像标准化。规范化器是硬编码的,在学习过程中不会进行调整。在网络中执行规范化允许标准化方案随网络架构改变,并通过 GPU 处理加速。
卷积层的设计是为了进行特征提取,并通过一系列不同层结构的实验进行经验选择。然后,我们在前三个卷积层中使用跨步卷积,步长为 2 × 2 ,核为 5 × 5 ,最后两个卷积层使用核大小为 3 × 3 的非跨步卷积。
我们跟随五个卷积层和三个完全连接的层,得到最终的输出控制值,即反向转弯半径。完全连接的层被设计成一个控制器来控制方向,但是我们注意到,通过端到端的训练系统,不可能在网络的哪些部分主要作为特征提取器,哪些部分作为控制器起作用。
培训详情
数据选择
训练 神经网络 的第一步是选择要使用的帧。我们收集的数据被标记为道路类型、天气状况和驾驶员的活动(停留在车道上、切换车道、转弯等)。为了训练 CNN 进行车道跟踪,我们只需选择驾驶员停留在车道上的数据,然后丢弃其余数据。然后,我们以 10 FPS 的速度对视频进行采样,因为更高的采样率将包含高度相似的图像,因此不会提供太多额外的有用信息。为了消除对直线行驶的偏见,训练数据中包含了更高比例的表示道路曲线的帧。
增强
在选择最后一组帧后,我们通过添加人工移动和旋转来增加数据,以教网络如何从不良位置或方向恢复。这些扰动的大小是从正态分布中随机选取的。分布的平均值为零,标准差是我们用人类驾驶员测量的标准差的两倍。随着震级的增加,人为地增加数据确实会增加不需要的伪影(如前所述)。
在对经过训练的 CNN 进行道路测试之前,我们首先在仿真中评估网络的性能。图 6 显示了仿真系统的简化框图,图 7 显示了交互模式下模拟器的屏幕截图。
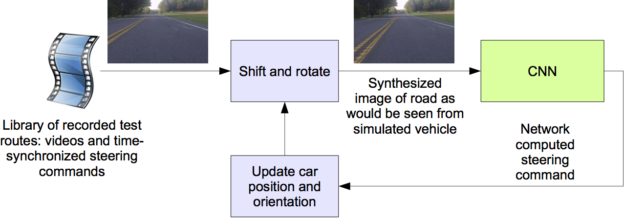
图 6 :驾驶模拟器框图。
这个模拟器从一个连接到人类驾驶的数据采集车的前向车载摄像头上获取预先录制的视频,生成的图像与 CNN 转向车辆时的图像大致相同。这些测试视频与人类驾驶员生成的录制的转向指令时间同步。
由于人类驾驶员不是一直在车道中心行驶,我们必须手动校准车道中心,因为它与模拟器使用的视频中的每个帧相关。我们称这一立场为“基本事实”。
模拟器对原始图像进行变换,以解释与地面真实情况的偏差。请注意,这种转换也包括了人类驱动的路径和基本真相之间的任何差异。转换是通过与前面描述的相同的方法完成的。
模拟器访问录制的测试视频以及捕获视频时发生的同步转向命令。模拟器将所选测试视频的第一帧发送到经过训练的 CNN 的输入,该视频根据地面真相的任何偏离进行调整,然后返回该帧的转向命令。 CNN 转向命令和记录的人 – 驾驶员指令被输入车辆的动态模型[7],以更新模拟车辆的位置和方向。

图 7 :交互模式下模拟器的屏幕截图。有关性能指标的说明,请参阅文本。由于视点变换,左侧的绿色区域未知。地平线下突出显示的宽矩形是发送给 CNN 的区域。
模拟器然后修改测试视频中的下一帧,使图像看起来像是车辆在遵循 CNN 的转向命令而产生的位置。这个新的图像然后被传送到 CNN 并且这个过程重复。
模拟器记录偏离中心的距离(从汽车到车道中心的距离)、偏航和虚拟汽车行驶的距离。当偏离中心距离超过 1 米时,将触发虚拟人干预,并重置虚拟车辆的位置和方向,以匹配原始测试视频对应帧的地面真实情况。
评价
我们通过两个步骤来评估我们的网络:首先在模拟中,然后在道路测试中。
在模拟中,我们的网络在模拟器中提供了一组预先记录的测试路线的指导命令,这些线路对应于新泽西州蒙茅斯县大约 3 小时 100 英里的行驶。测试数据是在不同的照明和天气条件下采集的,包括公路、当地道路和居民街。
我们通过计算模拟车辆偏离中心线超过 1 米时发生的模拟人类干预,来估计网络能够驱动汽车的时间百分比(自主)。我们假设,在现实生活中,实际干预总共需要 6 秒:这是人类重新控制车辆、重新居中,然后重新启动自动转向模式所需的时间。我们通过计算干预次数,乘以 6 秒,除以模拟测试的运行时间,然后从 1 减去结果来计算自主性百分比:

因此,如果我们在 600 秒内进行 10 次干预,我们的自主性值将为

道路试验
经过训练的网络在模拟器中表现出良好的性能后,网络被加载到我们的测试车的驱动器 PX 上,并被带出进行道路测试。在这些测试中,我们用汽车自动转向的时间来衡量性能。此时间不包括从一条道路到另一条道路的车道变更和转弯。在新泽西州蒙茅斯县,从我们在霍尔姆德尔的办公室到大西洋高地的典型驾车旅行,我们大约 98% 的时间是自治的。我们还在花园州公园大道上行驶了 10 英里(一条有进出口匝道的多车道分车道高速公路),没有拦截。
以下是我们的测试车在不同条件下驾驶的视频。
CNN 内部状态的可视化

图 8 : CNN 如何“看到”一条未铺砌的道路。顶部:发送到 CNN 的摄像机图像的子集。左下:激活第一层要素地图。右下:激活第二层要素地图。这表明 CNN 学会了自己检测有用的道路特征,即仅以人的转向角作为训练信号。我们从来没有明确训练过它去探测道路的轮廓。
图 8 和图 9 显示了两个不同示例输入的前两个要素地图层的激活,即未铺砌的道路和森林。对于未铺筑的道路,特征地图激活可以清楚地显示道路的轮廓,而对于森林,特征地图包含的大部分是噪音,即 CNN 在该图像中找不到有用的信息。
这表明 CNN 学会了自己检测有用的道路特征,即仅以人的转向角作为训练信号。例如,我们从来没有明确训练过它来检测道路的轮廓。

图 9 :没有道路的示例图像。前两个特征地图的激活似乎主要包含噪音,也就是说, CNN 在这张图片中没有识别出任何有用的特征。
结论
我们已经通过经验证明, cnn 能够学习车道和道路跟随的整个任务,而无需手动分解为道路或车道标记检测、语义抽象、路径规划和控制。从不到一百小时的驾驶中获得的少量培训数据就足以训练汽车在不同的条件下运行,在高速公路、当地和居民道路上,在晴天、多云和下雨的条件下。 CNN 能够从非常稀疏的训练信号(单独转向)中学习有意义的道路特征。
例如,该系统学习如何检测道路轮廓,而不需要在训练过程中使用明确的标签。
为了提高网络的鲁棒性,寻找验证鲁棒性的方法,提高网络内部处理步骤的可视化程度,还需要做更多的工作。
关于作者
Mariusz Bojarski 博士于 2009 年获得华沙理工大学电子与计算机工程硕士学位。他在电池管理系统、移动机器人电池充电器、移动自动化和测量以及 ele CTR ic 车辆无线充电系统的开发方面有着广泛的职业生涯。 2015 年 12 月, Mariusz 加入 NVIDIA ,担任深度学习研发工程师,致力于自主驾驶技术。
Ben Firner 博士毕业于罗格斯大学无线信息网络实验室( WINLAB ),他在那里研究一种无线协议,允许小型无线传感器在币形电池上运行 10 年以上。在加入 NVIDIA 之前,他与一家初创公司合作,利用这些传感器为实验动物护理市场创建实时监控系统。 Ben 目前正与 NVIDIA 自主驾驶团队的其他成员合作,创建接近人类水平驾驶能力的神经网络,最终目标是使驾驶更安全、压力更小。
Beat Flepp 是 NVIDIA 自主驾驶团队的高级开发技术工程师,负责设计、实施、测试和维护硬件和软件基础设施的许多方面,以便在各种 NVIDIA 嵌入式系统上训练和运行用于自主驾驶的神经网络模型。贝特于 1999 年获得瑞士联邦理工学院电气工程博士学位。
Larry Jackel 是 North-C Technologies 的总裁,在那里他从事专业咨询。他曾担任国防高级研究计划局( DARPA )项目经理,管理网络文件存储项目,并与自主地面机器人导航和移动工作。杰克尔拥有康奈尔大学实验物理学博士学位,论文主题是超导电子 CTR 。
Urs Muller 是新泽西州 NVIDIA 汽车公司的开发技术总监和首席软件架构师。他的工作重点是使用 NVIDIA Tegra 平台开发自动车辆的端到端解决方案,他在机器人技术、计算机视觉、机器学习和高性能计算方面拥有 20 多年的经验。他收到了博士 1993 年获瑞士联邦理工学院电子工程与计算机科学专业。
Karol Zieba 最近在佛蒙特大学完成了计算机科学硕士学位。在 NVIDIA 上,卡罗尔扩展了自动驾驶车辆的学习方式。卡罗尔喜欢举重、棋盘游戏,并探索机器学习、复杂网络和具体认知方面的最新研究。Davide Del Testa 是 NVIDIA 汽车解决方案架构师团队的成员,他支持客户构建基于 NVIDIA 驱动平台的自主驾驶架构。在此之前,他是 NVIDIA 的深度学习研究实习生,在那里他应用深度学习技术开发 BB8 , NVIDIA 的研究工具。 Davide 拥有应用于电信的机器学习博士学位,他在网络优化和信号处理领域采用了学习技术。他在意大利帕多瓦大学获得电信工程硕士学位。
审核编辑:郭婷
-
控制器
+关注
关注
112文章
15896浏览量
175426 -
汽车电子
+关注
关注
3014文章
7740浏览量
164914 -
神经网络
+关注
关注
42文章
4717浏览量
100030
发布评论请先 登录
相关推荐
NVIDIA Research端到端自动驾驶模型引领国际挑战赛

FPGA在自动驾驶领域有哪些应用?
广汽丰田携手Momenta推出端到端全场景智能驾驶方案
小鹏汽车发布端到端大模型
智行者联合清华完成国内首套全栈式端到端自动驾驶系统的开放道路测试
佐思汽研发布《2024年端到端自动驾驶研究报告》

理想汽车自动驾驶端到端模型实现

端到端自动驾驶的基石在哪里?
端到端自动驾驶的基石到底是什么?
两种端到端的自动驾驶系统算法架构
LabVIEW开发自动驾驶的双目测距系统
基于端到端的Al自动驾驶决策方法





 工商网监
工商网监
评论