 一文详解知识增强的语言预训练模型
一文详解知识增强的语言预训练模型
来自:复旦DISC
作者:王思远
引言
随着预训练语言模型(PLMs)的不断发展,各种NLP任务设置上都取得了不俗的性能。尽管PLMs可以从大量语料库中学习一定的知识,但仍旧存在很多问题,如知识量有限、受训练数据长尾分布影响鲁棒性不好等,在实际应用场景中效果不好。为了解决这个问题,将知识注入到PLMs中已经成为一个非常活跃的研究领域。本次分享将介绍三篇知识增强的预训练语言模型论文,分别通过基于知识向量、知识检索以及知识监督的知识注入方法来增强语言预训练模型。
文章概览
KLMo:建模细粒度关系的知识图增强预训练语言模型(KLMo: Knowledge Graph Enhanced Pretrained Language Model with Fine-Grained Relationships)
这篇文章提出同时将KG中的实体以及实体间的关系结合到语言学习过程中,来得到一个知识增强预训练模型。通过一个知识聚合器对文本中的实体片段和KG中的实体、关系向量之间的交互建模,从而将KG中的实体和关系向量融入语言模型中,还提出了关系预测和实体链接的预训练任务来整合KG中关系和实体信息。
用于知识增强语言模型预训练的基于知识图合成语料库生成(Knowledge Graph Based Synthetic Corpus Generation for Knowledge-Enhanced Language Model Pre-training)
检索型语言模型通过从外部文本知识语料集中检索知识增强模型,本文为了整合结构化知识和自然语言数据,提出了将知识图谱转换为自然文本,来为检索型语言模型扩充检索知识语料库,从而使得结构化知识无缝地集成到现有的预训练语言模型中。
ERICA:通过对比学习提高预训练语言模型对实体和关系的理解(ERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive Learning)
这篇文章提出对文本中的关系事实进行建模来增强语言模型,具体地设计了实体判别和关系判别两个预训练任务来以知识监督的方式加深对实体和关系的理解,并通过对比学习的框架实现。
论文细节
1论文动机
本文类似ERNIE-THU[1],通过引入知识向量增强预训练语言模型,然而以前的知识增强模型只利用实体信息,而忽略了实体之间的细粒度关系。而实体间的关系对于语言表示学习也至关重要,如图KG中的关系信息影响了实体Trio of Happiness的类别预测。
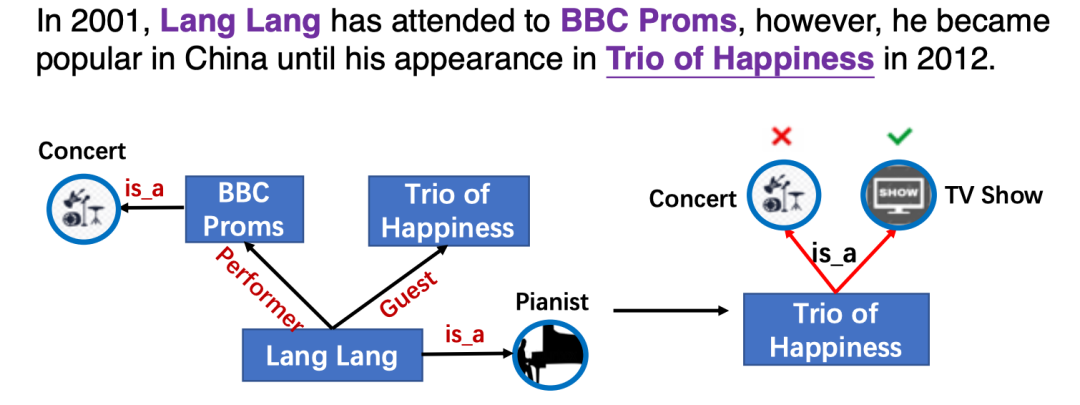
将KG中的实体和关系明确地整合到PLMs中的主要挑战是文本知识(实体和关系)对齐(TKA)问题,为了解决这个问题,文章提出了一个知识增强预训练语言模型(KLMo),通过一个知识聚合器对文本中的实体片段和KG中的实体、关系向量之间的交互建模,使得文本中token关注到高度相关的KG实体和关系。文章还提出了关系预测和实体链接的两个预训练任务,来整合KG中关系和实体信息,从而实现将KG中的实体和关系信息融入语言模型中。
模型
KLMo模型如下图,结构上类似ERNIE-THU,文本序列首先经过一个文本编码器,然后会被输入到知识聚合器中来将实体和关系的知识向量融入到文本序列中,最后通过优化关系预测和实体链接两个预训练目标,从而将KG中高度相关的实体和关系信息合并到文本表示中。
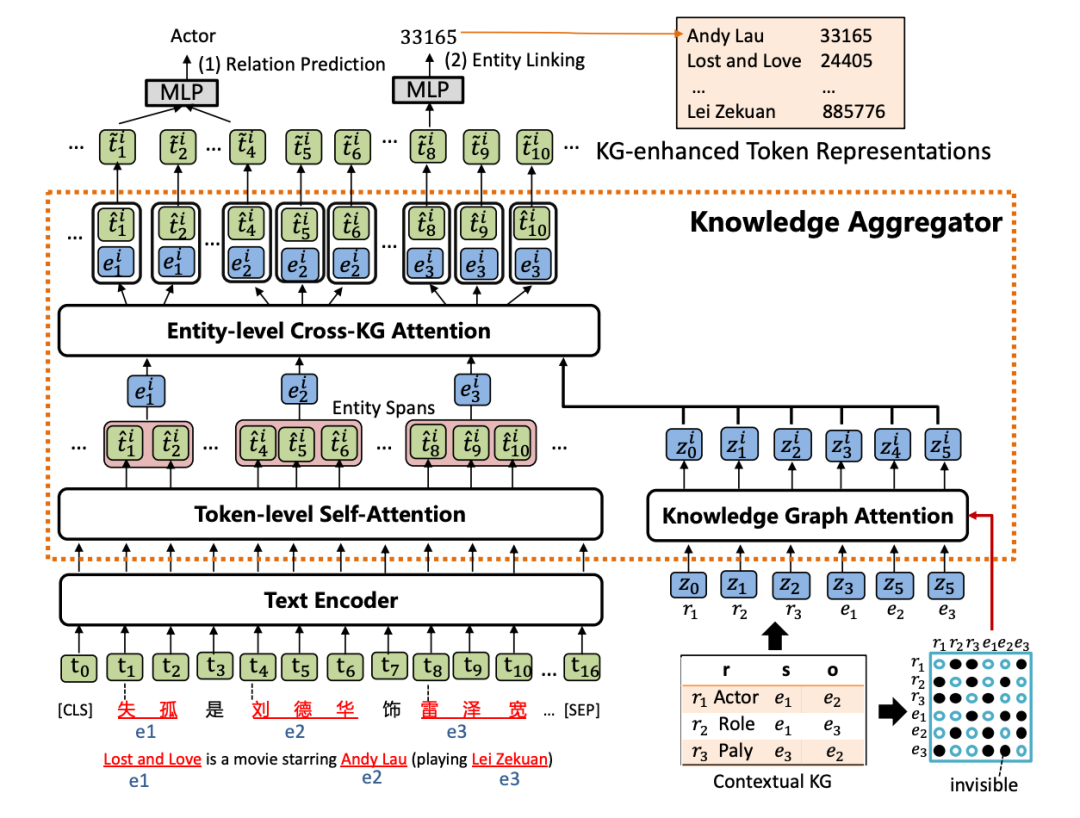
1. 知识聚合器
知识聚合器包含两个独立的注意力机制:token级别自注意力和知识图谱注意力,分别对输入文本和KG进行编码,聚合器通过实体级别的交叉KG注意力,对文本中的实体片段与KG中的实体和关系之间的交互进行建模,以将知识融入文本表示。
(1) 知识图谱注意力机制
首先通过TransE得到KG中的实体和关系表示,并将其转成一条实体和关系向量序列,作为聚合器的输入。然后采用一个知识图谱注意力机制,通过在传统注意力机制中引入一个可视矩阵,从而在知识表示学习过程中考虑图结构,该矩阵只允许相邻节点和关系可以关注到彼此。
(2) 实体级别交叉KG注意力机制
给定一个实体提及列表,通过在文本中实体范围内的所有tokens上pooling计算得到文本中实体片段表示,然后将文本中的实体片段表示作为query,将KG中的实体和关系表示作为key和value,进行注意力计算,从而得到知识增强的实体表示。
(3) 知识增强的文本表示
为了将知识增强的实体表示注入到文本表示中,文章采用一个知识融入操作,公式如下,得到的知识增强文本表示将会被传入下一层知识聚合器中。
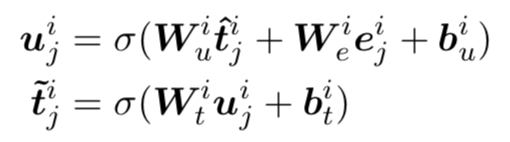
2. 预训练目标
为了将知识融入到语言预训练中,KLMo采取了一个多任务损失函数,除了传统的masked language model损失,还引入了一个关系预测以及实体链接的损失函数。
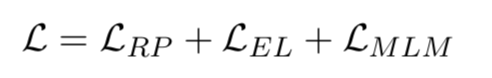
实验
模型在百度百科网页数据以及百科知识图谱上进行预训练,并在两个分别用于实体分类以及关系分类的中文数据集上进行了比较和评估,结果显示实体之间的细粒度关系信息有助于KLMo更准确地预测实体和关系的类别。
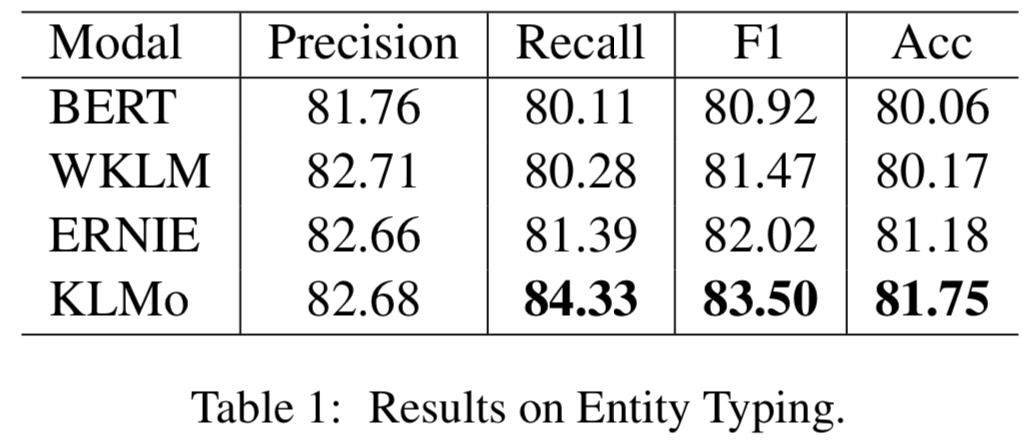
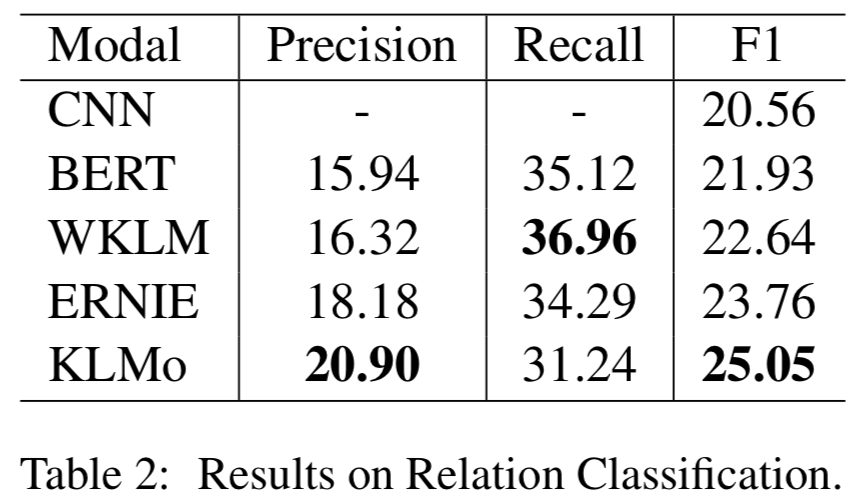
同时文章还在实体分类上对KLMo中实体和关系知识进行了消融实验,结果如下可以看出通过预训练,知识信息已经被融入KLMo中。
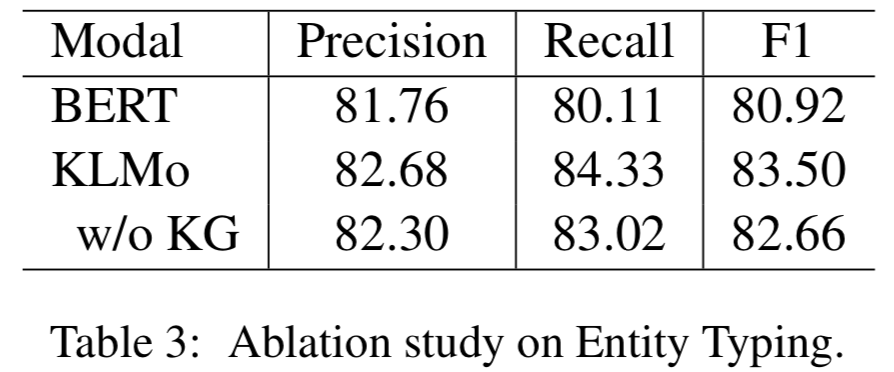
2

论文动机
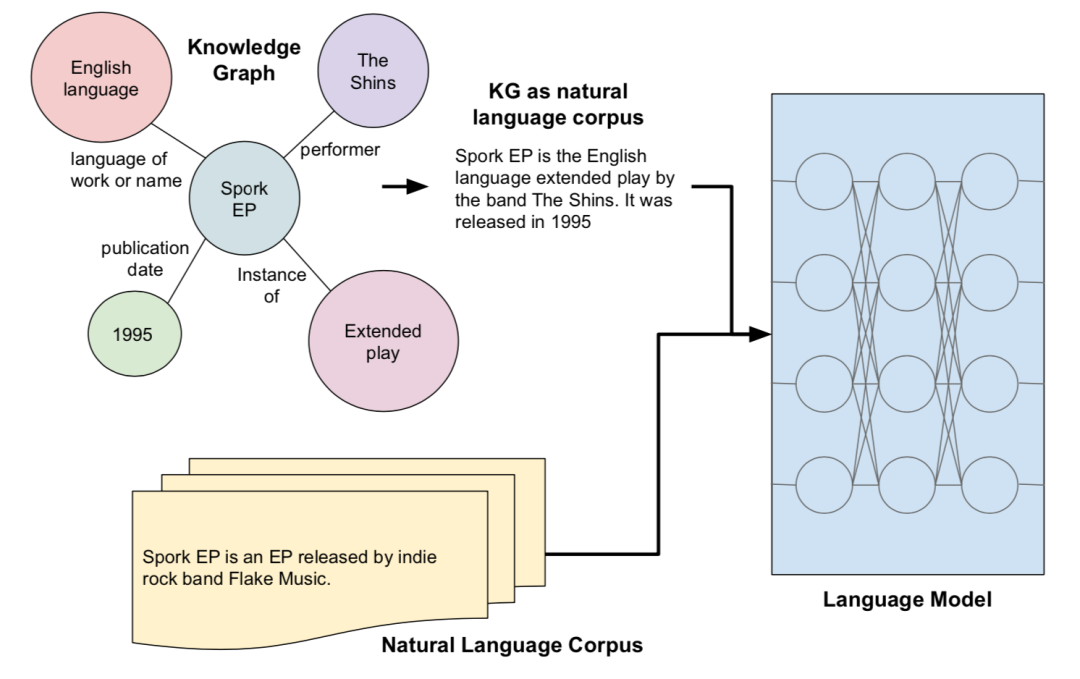
本文基于检索型预训练语言模型,通过从外部知识语料集检索知识来增强语言模型,然而以前都是从文本语料集中检索知识,只能覆盖有限的世界知识而忽略了结构化知识,并且知识在文本中的表达没有在KG中那么明确,文本质量的变化也会导致结果模型中的偏差。为了将结构化知识整合到语言模型中,文章将结构化知识图谱转换为自然文本,来为检索型语言模型REALM[2]扩充检索知识语料库KELM,从而使得结构化知识无缝地集成到现有的预训练语言模型中。
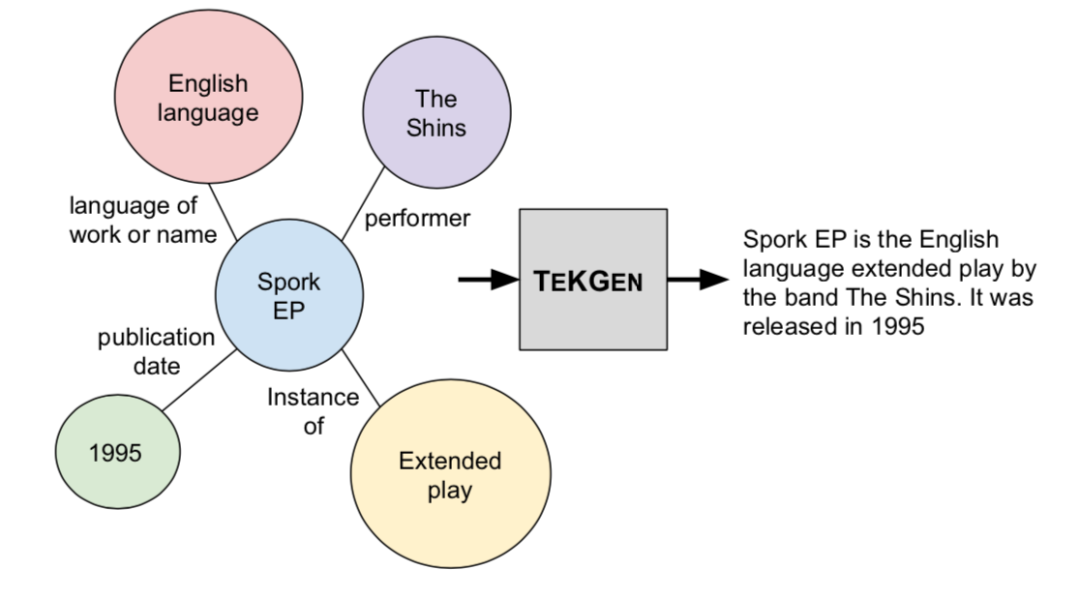
本文提出将英文维基百科知识图谱转化成自然语言文本,如上图,并构建了一个英文Wikidata KG-Wikipedia Text的对齐数据集来训练文本化模型,从而生成了KELM数据集,扩充REALM的检索知识语料库。
模型
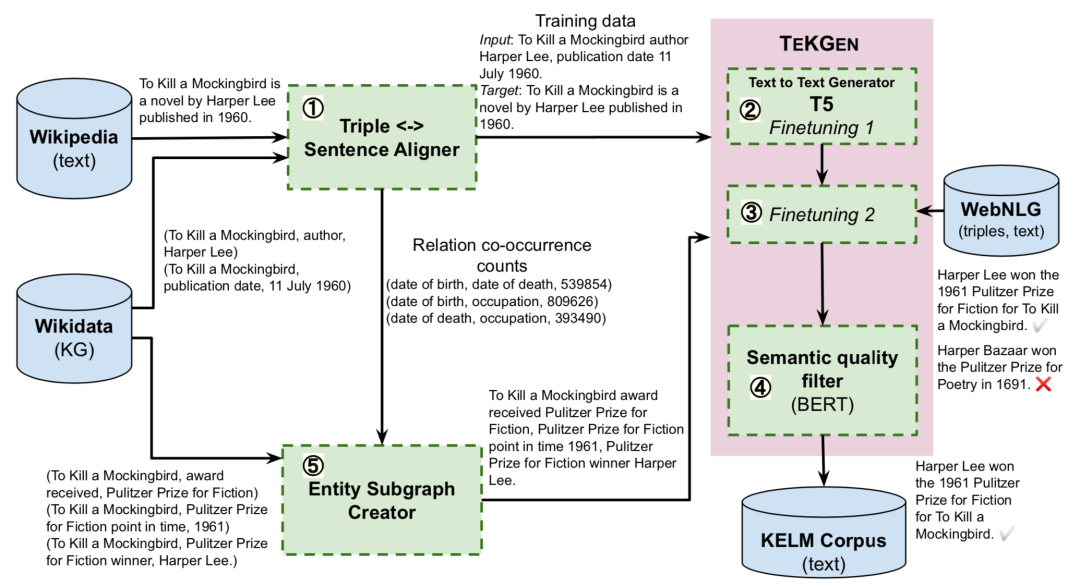
1. 基于KG的文本生成器TEKGEN
文章首先提出了一个端到端的基于KG的文本化模型TEKGEN,具体流程如上图:首先使用远程监督来对齐维基百科文本和KG三元组;随后T5模型按顺序首先在这个语料库上进行微调来提升实体和关系覆盖率,随后在标准WebNLG语料库上进行少量步骤的训练来减少错误;最后通过对BERT微调构建一个过滤器,为生成文本针对三元组的语义质量打分。
2. 合成知识检索数据集KELM Corpus
这一步利用TEKGEN模型和过滤器来构建一个合成语料库KELM,以自然语言的格式捕获KG知识。首先使用前面构造的英文Wikidata KG-Wikipedia Text的对齐数据集的关系对创建实体子图,随后子图中的知识三元组通过TEKGEN模型转化为自然语言文本,从而构建KELM数据集。
3.知识增强语言模型
文章将生成的KELM语料库作为将KGs集成到预训练语言模型,如下图所示,采用了基于检索的预训练语言模型REALM,预训练过程中,除了掩码句还会从检索语料集中抽取一个文本作为辅助知识用来联合预测掩盖的单词,而KELM则被用来替换/扩充REALM中的检索语料集,帮助语言模型引入结构化知识。
实验
实验在知识探测(LAMA数据集)和开放域QA(NaturalQuestions和WebQuestions)上进行,作者分别尝试REALM上的三种检索语料集设定:ORIGINAL(Wikipedia Text)、REPLACED(only KELM Corpus)和AUGMENTED(Wikipedia text + KELM Corpus),结果如下:
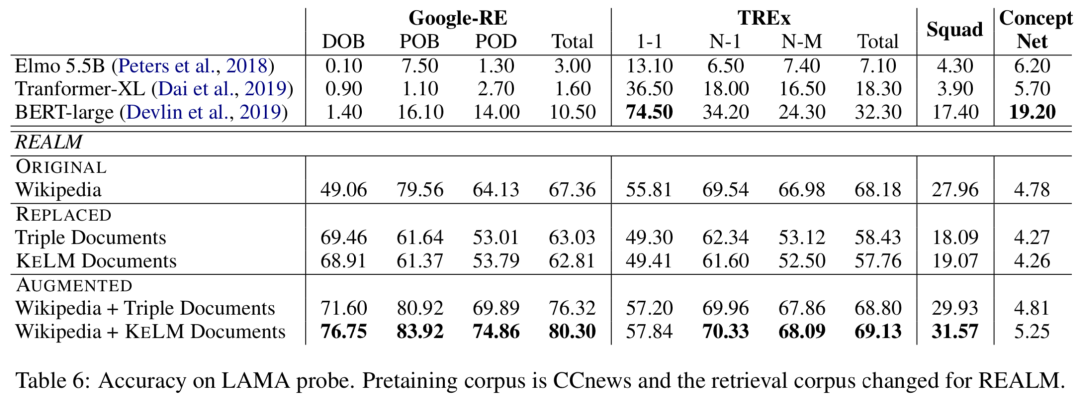
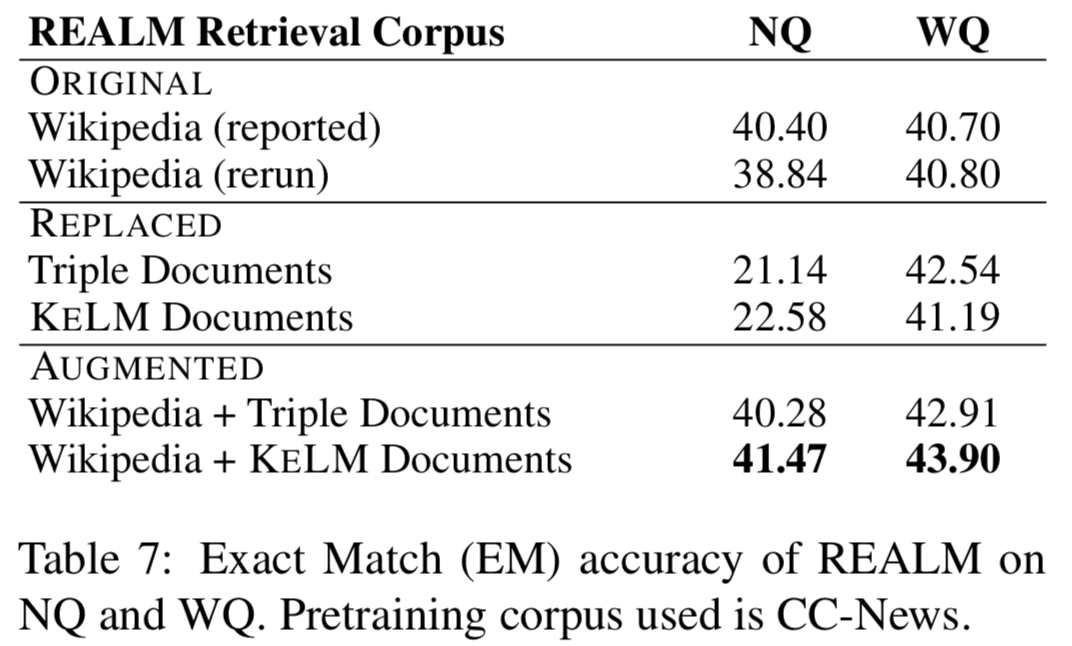
可以看出通过文本化结构知识来扩充检索语料集,在知识探测和开放域QA上都有提升。作者还进行了实验,将原始的Wikidata三元组而非KELM语料库整合进语言模型,结果确认了结构化知识文本化的有效性。
3

论文动机
本文通过知识监督的方式来建模文本中的关系事实从而增强预训练语言模型,包括同时建模句子内以及跨句子的关系信息,并提出对比学习的框架ERICA来全面学习实体和关系的交互,从而更好捕捉文本中关系事实。具体包含了两个预训练任务:(1)实体判别:给定一个头实体和关系,推断可能的尾实体;(2)关系判别:判别两个关系是否语义相似。
模型
ERICA根据无监督数据集和外部知识图谱构建远程监督帮助预训练。给定一个段落,枚举出所有实体以及它们之间存在的关系,从而构建整个对比学习的正样本集。
1. 实体&关系表示
给定一个文本,首先使用PLM进行编码并得到每个token的隐表示,然后对提及实体的连续tokens上的表示做mean pooling得到当前实体表示,如果一个文本多次提及一个实体,则对多个表示进行平均得到最终实体表示,而对于关系表示,通过组合关系的首尾实体的表示得到其表示。
2. 实体判别任务
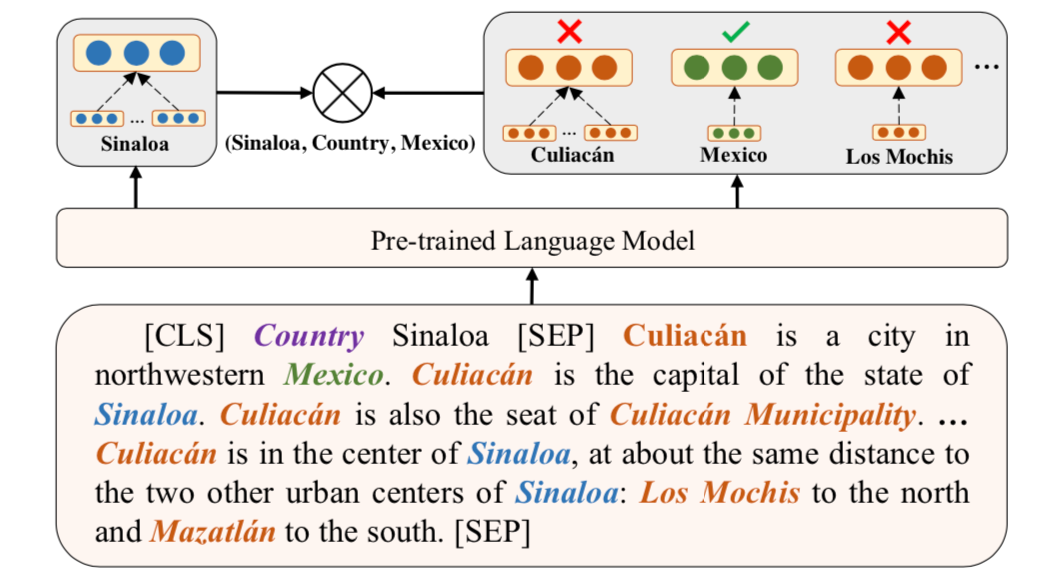
从正样本集中选择一个元组,给定其中的头实体和关系,通过对比学习使得正确尾实体相较于文本中其他实体,要和头实体更相近,具体公式如下。
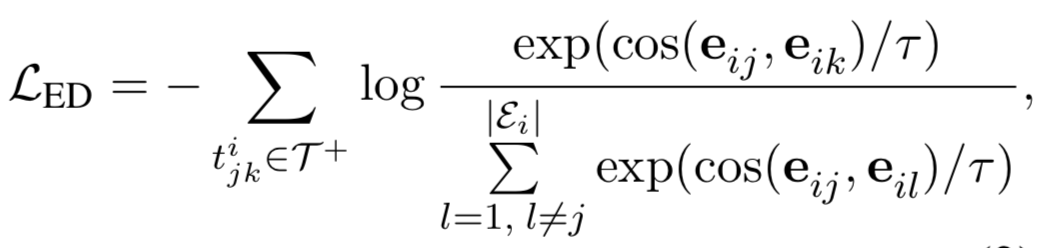
3. 关系判别任务
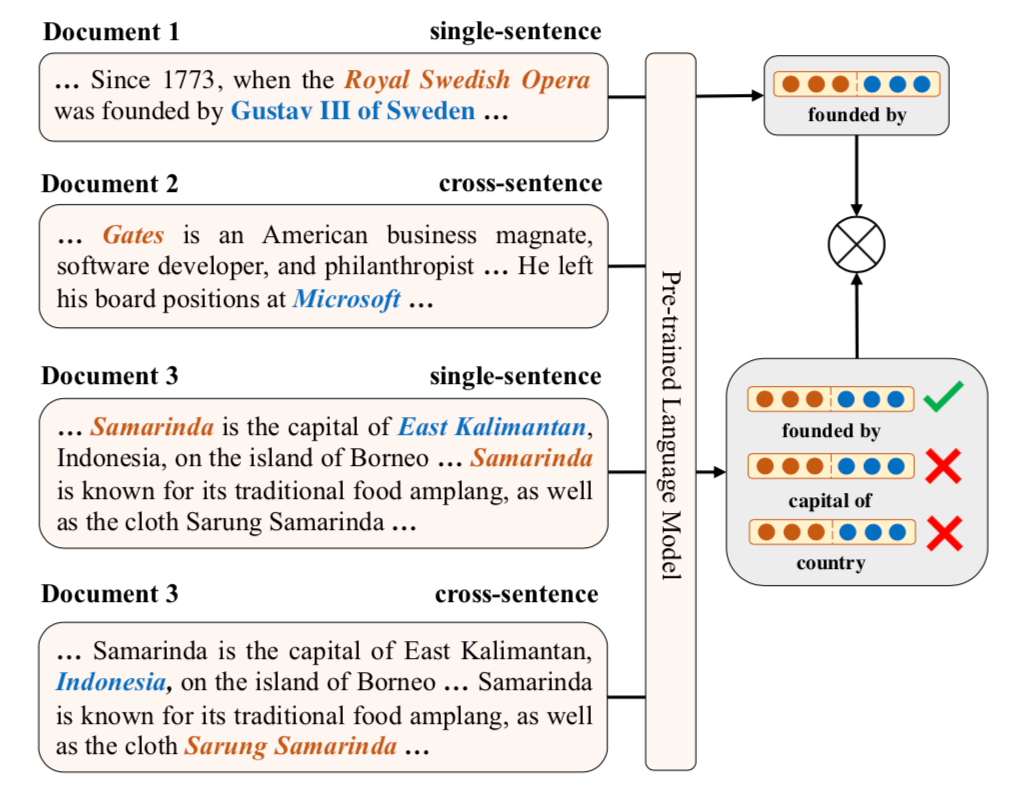
这个任务需要判别两个关系是否语义相似,这里考虑到了句子内以及跨句子的关系,从而使得模型隐式地学习到了复杂关系链。具体方法如上图,通过对比学习使得相同的关系表示(由实体对表示计算得到)应该更相近。
实验
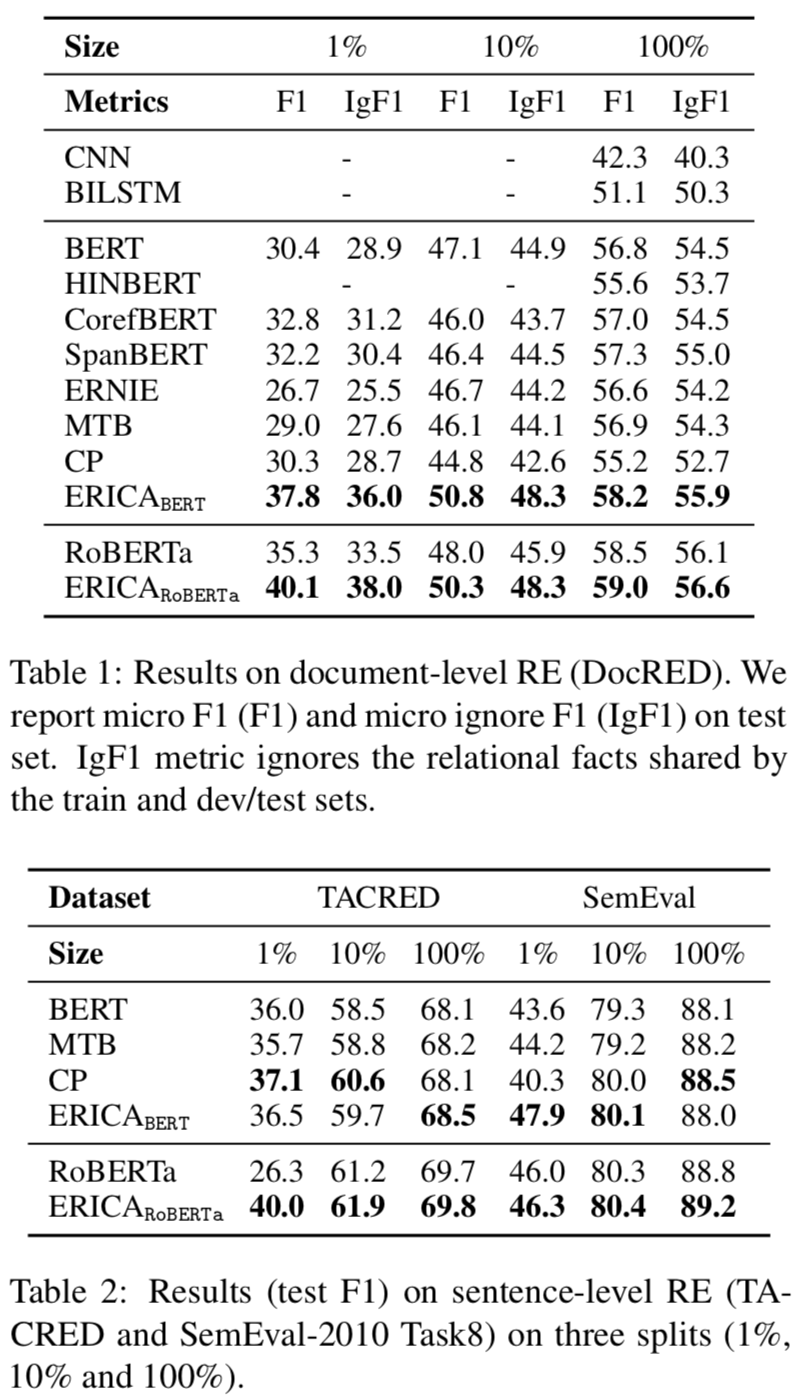
本文在BERT和RoBERTa都进行了增强训练,远程监督根据English Wikipedia和Wikidata构建,评估实验在关系抽取、实体分类和问题回答任务上进行的,实验结果分别如下:
Relation Extraction
Entity Typing
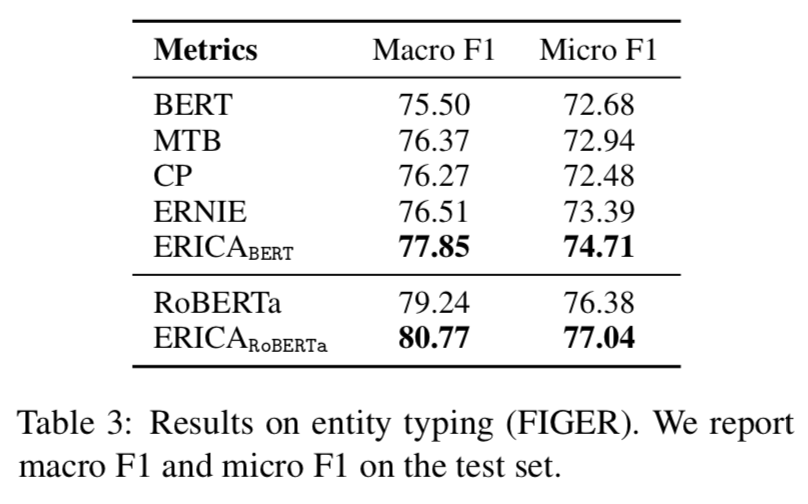
Question Answering
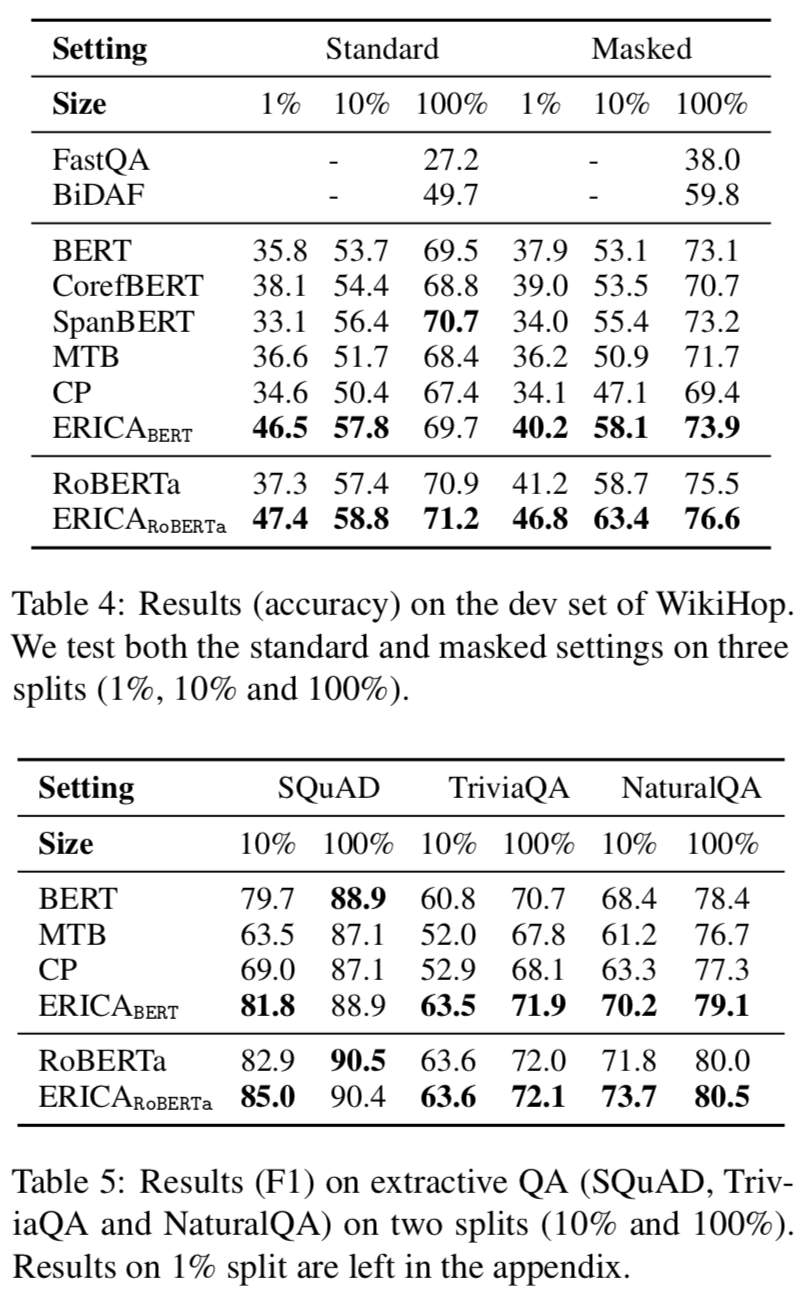
可以看出ERICA模型在不同任务不同数据集合上都有一定的提升。
总结
本次分享我们介绍了三篇知识增强的预训练语言模型文章,分别围绕知识向量、知识检索以及知识监督的方法来向语言模型中注入知识。第一篇通过一个知识聚合器将KG中的实体和关系向量显式注入语言模型;第二篇通过将知识图谱转换为自然文本,为检索型语言模型扩充检索知识语料库,从而将结构化知识无缝地注入到语言模型中;第三篇基于知识监督的方式来建模文本中的关系事实从而增强预训练语言模型。
原文标题:从最新的ACL、NAACL和EMNLP中详解知识增强的语言预训练模型
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
审核编辑:汤梓红
-
语言模型
+关注
关注
0文章
547浏览量
10373
原文标题:从最新的ACL、NAACL和EMNLP中详解知识增强的语言预训练模型
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【大语言模型:原理与工程实践】大语言模型的预训练
检索增强型语言表征模型预训练

Multilingual多语言预训练语言模型的套路
一种基于乱序语言模型的预训练模型-PERT
CogBERT:脑认知指导的预训练语言模型
预训练数据大小对于预训练模型的影响
基于预训练模型和语言增强的零样本视觉学习

基于医学知识增强的基础模型预训练方法





 工商网监
工商网监
评论