 NVIDIA CUDA C ++编译器的新特性
NVIDIA CUDA C ++编译器的新特性
CUDA 11 . 5 C ++编译器解决了不断增长的客户请求。具体来说,如何减少 CUDA 应用程序构建时间。除了消除未使用的内核外, NVRTC 和 PTX 并发编译有助于解决这个关键问题 CUDA C ++应用程序开发的关注点。
CUDA 11 . 5 NVCC 编译器现在添加了对 Clang 12 . 0 作为主机编译器的支持。我们还提供了 128 位整数支持的有限预览版本,这在高保真计算中变得至关重要。
CUDA C ++编译器工具链上的技术演练补充了编程指南(需要链接),并提供了在 CUDA 11 . 5 工具包版本中引入的新特性的广泛概述。
并发编译
NVRTC 编译过程分为三个主要阶段:
Parser -> NVVM optimizer -> PTX Compiler
其中一些阶段不是线程安全的,因此 NVRTC 以前会使用全局锁序列化来自多个用户线程的并发编译请求。
在 CUDA 11 . 5 中,对 NVRTC 实现进行了增强,以提供部分并发编译支持。这是通过移除全局锁和使用每阶段锁来实现的,这会导致不同的线程并发执行编译管道的不同阶段。
图 1 显示了 CUDA 11 . 5 之前的 NVRTC 如何序列化来自四个线程的同时编译请求。
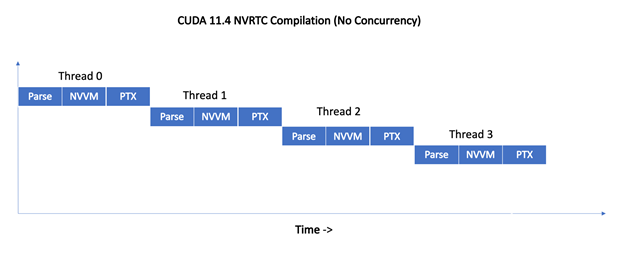
图 1 。序列化编译
对于 11 . 5 , NVRTC 不会序列化编译请求。相反,来自不同线程的编译请求是管道化的,从而使编译管道的不同阶段能够同时进行。
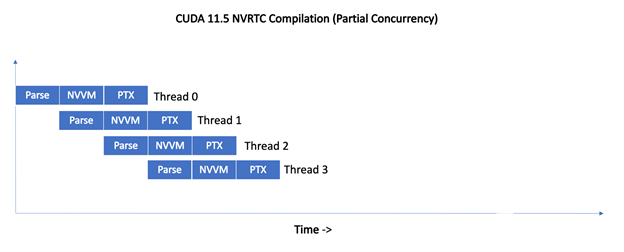
图 2 。并发编译
图 3 中的图表显示了编译一组 100 个相同的示例 NVRTC 程序的总编译时间,这些程序按可用线程数进行划分。
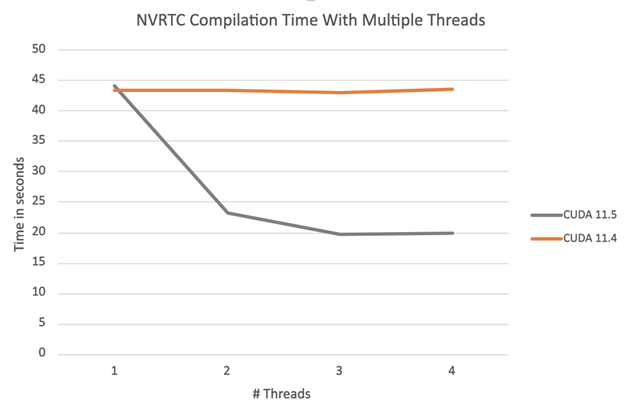
图 3 。 CUDA 11 . 4 和 11 . 5 的编译时间比较
正如所料,对于 CUDA 11 . 4 NVRTC ,总编译时间不会随着线程数的增加而改变,而编译是使用全局 NVRTC 锁序列化的。使用 CUDA 11 . 5 NVRTC ,总编译时间会随着线程数的增加而减少。我们将继续使单个 stage 线程更安全,这将为本例实现近乎线性的加速。
PTX 并发编译
沿着 JIT 编译路径进行 PTX 编译,以及使用 PTX 静态库进行多个内部阶段。这些阶段以前的实现不能保证从多个线程进行并发编译。相反, PTX 编译器使用全局锁来序列化并发编译。
在 CUDA 11 . 5 和 R495 驱动程序中, PTX 编译器实现现在使用更细粒度的本地锁,而不是全局锁。这允许并发执行多个编译请求,并显著缩短了编译时间。
下图显示了编译 104 个相同的示例程序所需的总编译时间,这些程序在给定数量的线程上拆分到cuLinkAddData使用CU_JIT_INPUT_PTX作为CUjitInputType。
正如 R470 CUDA 驱动程序所预期的那样,总编译时间不会随着线程数的增加而改变,因为编译是用全局锁序列化的。使用 R495 CUDA 驱动程序,总编译时间随着线程数的增加而减少。
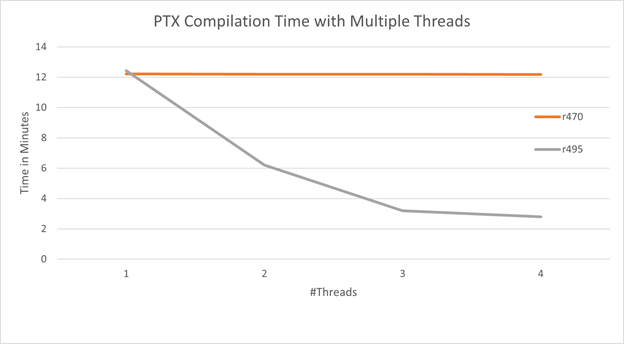
图 4 。 CUDA 11 . 4 和 11 . 5 的 PTX 并发编译比较
消除未使用的内核
单独编译模式允许 CUDA 内核函数和设备函数作为 CUDA 设备代码库发布,并使用设备链接器 NVLink 针对任何用户应用程序进行链接。然后在运行时在 GPU 上加载并执行生成的设备程序。
在 CUDA 11 . 5 之前, NVLink 无法确定从链接设备程序中删除未使用的内核是否安全,因为这些内核函数可以从主机代码中引用。
考虑一个定义四个内核函数的库:
//library.cu
__global__ void AAA() { /* code */ }
__global__ void BBB() { /* code */ }
__global__ void CCC() { /* code */ }
__global__ void DDD() { /* code */ }
该库的构建和发布:
$nvcc -rdc=true library.cu -lib -o testlib.a
用户代码引用库中的单个内核:
//user.cu
extern __global__ void AAA();
int main() { AAA<<<1,1>>>(); }
代码链接为:
$nvcc -rdc=true user.cu testlib.a -o user
以 CUDA 11 . 4 为例,链接设备程序将包含所有四个内核体,即使链接设备程序中只使用一个内核(“ AAA ”)。对于链接到较大库的应用程序来说,这可能是一个负担。
增加的二进制大小和应用程序加载时间并不是冗余设备代码的唯一问题。当使用设备链接时间优化(DLTO –修复链接)时,在优化之前未删除的未使用内核可能会导致更长的构建时间,并可能阻碍代码优化。
使用 CUDA 11 . 5 , CUDA 编译器将跟踪主机代码中对内核的引用,并将此信息传播到设备链接器( NVLink )。 NVLink 然后从链接的设备程序中删除未使用的内核。对于前面的示例,未使用的内核 BBB 、 CCC 和 DDD 将从链接设备程序中删除。
在 CUDA 11 . 5 中,默认情况下禁用此优化,但可以通过将-Xnvlink -use-host-info选项添加到 NVCC 命令行来启用:
$nvcc -rdc=true user.cu testlib.a -o user -Xnvlink -use-host-info
在随后的 CUDA 工具包版本中,默认情况下将启用优化,并提供一个退出标志。
这里有一些警告。在 CUDA 11 . 5 中,编译器对内核引用的分析在以下情况下是保守的。编译器可以考虑一些未从宿主代码实际引用的内核,如:
- 如果模板实例化是从主机代码引用的,则该模板的所有实例都被视为是从主机代码引用的。
template
__global__ void foo() { }
__device__ void doit() { foo<<<1,1>>>(); }
int main() {
// compiler will mark all instances of foo template as referenced
// from host code, including "foo", which is only actually
// referenced from device code
foo<<<1,1>>>();
}
-
__global__ or __device__函数体之外的任何引用都被视为主机代码引用。
__global__ void foo() { }
__device__ auto *ptr = foo; // foo is considered as referenced
// from host code.
- 当对函数的引用为template-dependent时,具有该名称的所有内核都被视为主机引用。
__global__ void foo(int) { }
namespace N1 {
template
__global__ void foo(T) { }
}
template
void doit() {
// the reference to 'foo' is template dependent, so
// both ::foo and all instances of ::N1::foo are
// considered as referenced from host code.
foo<<<1,1>>>(T{});
}
另一个警告是,当设备链接步骤推迟到主机应用程序启动( JIT 链接)时,而不是在构建时,将不会删除未使用的内核。
// With nonvirtual architecture (sm_80), NVLink is invoked
// at build time, and kernel pruning will occur.
$nvcc -Xnvlink -use-host-info -rdc=true foo.cu bar.cu -o foo -arch sm_80
// With virtual architecture (compute_80), NVLink is not invoked
// at build time, but only during host application startup.
// kernel pruning will not occur.
$nvcc -Xnvlink -use-host-info -rdc=true foo.cu bar.cu -o foo -arch compute_80
今后的工作
在 CUDA 11 . 5 中, NVLink 在设备链接时间优化( DLTO – FIXME link )期间尚未使用有关未使用内核的信息。我们的目标是使 NVLink 能够使用此信息删除未使用的内核,减少优化器时间,并通过减少代码膨胀来提高生成的代码质量。
有限的 128 位整数支持
11 . 5 CUDA C ++编译器支持主机编译器支持 128 位整数的平台的 128 位整数数据类型。基本的算术、逻辑和位运算将在 128 位整数上工作。未来版本计划支持 CUDA 固有类型和 CUDA 数学函数的 128 位整数变体。
类似地,对 128 位整数的调试支持以及与开发人员工具的集成将在后续版本中提供。目前,我们正在开发者论坛上寻求您对此预览功能的早期反馈。
NVRTC 静态库
CUDA 11 . 5 提供了 NVRTC 库的静态版本。一些应用程序可能更喜欢链接静态 NVRTC 库,以保证部署期间的稳定性能和功能。静态库用户还希望静态链接 NVRTC 内置库和 PTX 编译器库的静态版本。有关链接静态 NVRTC 库的更多信息,请参阅NVRTC 用户指南。
__builtin_assume
CUDA 11 . 5 改进了__builtin_assume应用于__isShared(pointer)等地址空间谓词函数的结果时加载和存储的代码生成。有关其他支持的功能,请参阅地址空间谓词函数。
如果没有地址空间说明符,编译器将生成通用加载和存储指令,这需要一些额外的指令来计算特定的内存段,然后再执行实际的内存操作。使用__builtin_assume(expr)提示编译器使用泛型指针的地址空间,这可能会提高代码的性能。
Correct Usage:
bool b = __isShared(ptr);
__builtin_assume(b); // OK: Proof that ptr is a pointer to shared memory
Incorrect Usage:
These hints are ignored unless the boolean expression is stored in a separate variable:
__builtin_assume(__isShared(ptr)); // IGNORED
与其他__builtin_assume一样,如果表达式不为 TRUE ,则行为未定义。如果您有兴趣了解__builtin_assume的更多信息,请参阅 CUDA 11 . 2 编译器文章。
Pragma 诊断控制
在 CUDA 11 . 5 中, NVCC CUDA 编译器前端增加了对大量杂注的支持,这些杂注提供了对诊断消息的更多控制。
您可以使用以下杂注来控制特定错误号的编译器诊断:
#pragma nv_diag_suppress // suppress the specified diagnostic
// message
#pragma nv_diag_warning // make the specified diagnostic a warning
#pragma nv_diag_error // make the specified diagnostic an error
#pragma nv_diag_default // restore the specified diagnostic level
// to default
#pragma nv_diag_once // only report the specified diagnostic once
Uses of these pragmas have the following form:
#pragma nv_diag_xxx error_number, error_number …
要了解如何使用这些带有更详细警告的杂注,请参阅 CUDA 内部编程指南。以下示例将取消foo的 Clara 选项上的“declared but never referenced”警告:
#pragma nv_diag_suppress 177
void foo()
{
int xxx=0;
}
杂注nv_diagnostic推送和nv_diagnostic弹出可用于保存和恢复当前诊断pragma状态:
#pragma nv_diagnostic push
#pragma nv_diag_suppress 177
void foo()
{
int xxx=0;
}
#pragma nv_diagnostic pop
void bar()
{
int xxx=0;
}
这些杂注都不会对主机编译器产生任何影响。
不推荐使用注意:不带nv_前缀的诊断杂注已不推荐使用。例如,#pragma diag_suppress支持将从所有未来版本中删除。使用这些诊断标记将引发如下警告消息:
pragma "diag_suppress" is deprecated, use "nv_diag_suppress" instead
宏__NVCC_DIAG_PRAGMA_SUPPORT__有助于过渡到使用新宏:
#ifdef __NVCC_DIAG_PRAGMA_SUPPORT__
#pragma nv_diag_suppress 177
#else
#pragma diag_suppress 177
#endif
新选项 -arch = all | all major
在 CUDA 11 . 5 版本之前,如果您想为所有受支持的体系结构生成代码,必须在--generate-code选项中列出所有目标。如果添加了较新的版本,或旧版本失效,则必须相应地更改--generate-code选项。现在,新选项-arch=all|all-major提供了一种更简单、更高效的方法。
如果指定了-arch=all, NVCC 将为所有受支持的体系结构(sm_*)嵌入编译后的代码映像,并为最高的主要虚拟体系结构嵌入 PTX 程序。
如果指定了-arch=all-major, NVCC 将为所有受支持的主要版本(sm_*0)嵌入编译后的代码映像,从最早受支持的sm_x体系结构(此版本为sm_35)开始,并为最高的主要虚拟体系结构嵌入 PTX 程序。
例如,简单的-arch=all选项相当于此版本的以下一长串选项:
-gencode arch=compute_35,"code=sm_35"
-gencode arch=compute_37,"code=sm_37"
-gencode arch=compute_50,"code=sm_50"
-gencode arch=compute_52,"code=sm_52"
-gencode arch=compute_53,"code=sm_53"
-gencode arch=compute_60,"code=sm_60"
-gencode arch=compute_61,"code=sm_61"
-gencode arch=compute_62,"code=sm_62"
-gencode arch=compute_70,"code=sm_70"
-gencode arch=compute_72,"code=sm_72"
-gencode arch=compute_75,"code=sm_75"
-gencode arch=compute_80,"code=sm_80"
-gencode arch=compute_86,"code=sm_86"
-gencode arch=compute_87,"code=sm_87"
-gencode arch=compute_80,"code=compute_80"
简单的-arch=all-major选项相当于此版本的以下一长串选项:
-gencode arch=compute_35,"code=sm_35"
-gencode arch=compute_50,"code=sm_50"
-gencode arch=compute_60,"code=sm_60"
-gencode arch=compute_70,"code=sm_70"
-gencode arch=compute_80,"code=sm_80"
-gencode arch=compute_80,"code=compute_80"
有关所有受支持的虚拟体系结构,请参阅虚拟体系结构功能列表。有关所有受支持的真实体系结构,请参阅 GPU 功能列表。
确定性代码生成
在以前的 CUDA 工具包中,设备代码中内部链接变量或函数的名称在每次 nvcc 调用时都会更改,即使源代码没有更改。某些软件管理和构建系统检查生成的程序位是否已更改。先前的 nvcc 编译器行为导致此类系统触发,并错误地假设源程序中存在语义更改;例如,可能触发冗余的依赖生成。
在 CUDA 11 . 5 中, NVCC 编译器行为已更改为确定性。例如,考虑这个测试用例:
//--
static __device__ void foo() { }
auto __device__ fptr = foo;
int main() { }
//--
在 CUDA 11 . 4 中,两次编译同一程序会在 PTX 中生成稍微不同的名称:
//--
$cuda-11.4/bin/nvcc -std=c++14 -rdc=true -ptx test.cu -o test1.ptx
$cuda-11.4/bin/nvcc -std=c++14 -rdc=true -ptx test.cu -o test2.ptx
$diff -w test1.ptx test2.ptx
13c13
< .func _ZN57_INTERNAL_39_tmpxft_00000a46_00000000_7_test_cpp1_ii_main3fooEv
---
> .func _ZN57_INTERNAL_39_tmpxft_00000a4e_00000000_7_test_cpp1_ii_main3fooEv
16c16
< .visible .global .align 8 .u64 fptr = _ZN57_INTERNAL_39_tmpxft_00000a46_00000000_7_test_cpp1_ii_main3fooEv;
---
> .visible .global .align 8 .u64 fptr = _ZN57_INTERNAL_39_tmpxft_00000a4e_00000000_7_test_cpp1_ii_main3fooEv;
18c18
< .func _ZN57_INTERNAL_39_tmpxft_00000a46_00000000_7_test_cpp1_ii_main3fooEv()
---
> .func _ZN57_INTERNAL_39_tmpxft_00000a4e_00000000_7_test_cpp1_ii_main3fooEv()
$
//--
使用 CUDA 11 . 5 ,两次编译同一程序会生成相同的 PTX :
//--
$nvcc -std=c++14 -rdc=true -ptx test.cu -o test1.ptx
$nvcc -std=c++14 -rdc=true -ptx test.cu -o test2.ptx
$diff -w test1.ptx test2.ptx
$
//--
结论
通过阅读在 CUDA 11 . 5 工具包中展示新功能文章,了解更多关于 CUDA 11 . 5 工具包的信息。
关于作者
Arthy Sundaram 是 CUDA 平台的技术产品经理。她拥有哥伦比亚大学计算机科学硕士学位。她感兴趣的领域是操作系统、编译器和计算机体系结构。
Jaydeep Marathe 是 NVIDIA 的高级编译工程师。他拥有北卡罗来纳州立大学计算机科学硕士和博士学位。
Hari Sandanagobalane 是 NVIDIA 的高级编译工程师。他拥有新加坡国立大学计算机科学硕士学位。
Mike Murphy 是 NVIDIA 的高级编译工程师。
Xiaohua Zhang 是 NVIDIA 的高级编译工程师。他拥有清华大学计算机科学硕士学位。
Girish Bharambe 是 NVIDIA 的高级编译经理。他拥有印度浦那大学计算机工程学士学位。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
5087浏览量
103915 -
代码
+关注
关注
30文章
4841浏览量
69195
发布评论请先 登录
相关推荐
Triton编译器如何提升编程效率
Triton编译器的优化技巧
Triton编译器在机器学习中的应用
Triton编译器支持的编程语言
Triton编译器与其他编译器的比较
Triton编译器功能介绍 Triton编译器使用教程
HighTec C/C++编译器支持Andes晶心科技RISC-V IP

AI编译器技术剖析
人工智能编译器与传统编译器的区别
SEGGER编译器优化和安全技术介绍 支持最新C和C++语言

C语言:嵌入式开发中的关键编译器角色





 工商网监
工商网监
评论