 WSL2上CUDA性能的当前状态和发展
WSL2上CUDA性能的当前状态和发展
2020 年 6 月,我们发布了第一个 NVIDIA 显示驱动程序,该驱动程序为 Windows Insider Program ( WIP )预览用户启用了 Windows Subsystem for Linux ( WSL ) 2 中的 GPU 加速功能。当时,这仍然是一个早期预览,功能有限。一年后,随着我们稳步增加新功能,我们也一直专注于优化 CUDA 驱动程序,以在 WSL2 上提供最佳性能。
WSL 是 Windows 10 的一项功能,它使您能够直接在 Windows 上运行本机 Linux 命令行工具,而不需要双启动环境的复杂性。在内部, WSL 是一个与 Microsoft Windows 操作系统紧密集成的容器化环境。 WSL2 使您能够与传统 Windows 桌面和现代商店应用程序一起运行 Linux 应用程序。有关 WSL 上 CUDA 的更多信息,请参阅 在 Linux 2 的 Windows 子系统上宣布 CUDA 。
在本文中,我们将重点介绍 WSL2 上 CUDA 性能的当前状态、已经进行的各种以性能为中心的优化,以及未来的展望。
WSL 性能的当前状态
在过去的几个月里,我们一直在通过分析和优化 NVIDIA 和 Microsoft 方面的多个关键驱动程序路径来调整 WSL2 上 CUDA 驱动程序的性能。在本文中,我们将详细介绍我们为达到当前性能水平所做的工作。在我们开始之前,这里是 WSL2 在几个基准上的当前状态。
在 WSL2 上,所有 GPU 操作都通过 VMBUS 序列化并发送到主机内核接口。 WSL2 最常见的性能问题之一是上述操作的开销。我们知道,开发人员想知道,与直接在本机 Linux 上运行工作负载相比,在 WSL2 中运行工作负载是否有任何开销。有区别吗?这项开销大吗?
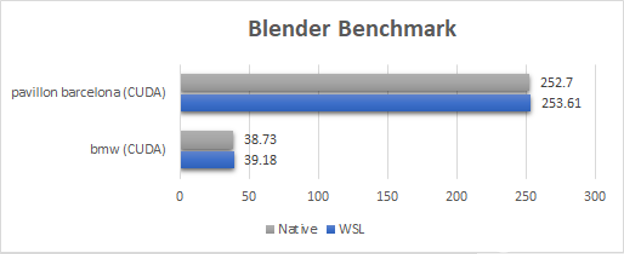
图 1 。 Blender 基准测试结果( WSL2 与 Native ,结果以秒为单位,越低越好) 。
对于 Blender 基准测试, WSL2 性能与本机 Linux 相当或接近(在 1% 以内)。因为 Blender 循环将长时间运行的内核推送到 GPU 上,所以 WSL2 的开销在这些基准上都是不可见的。
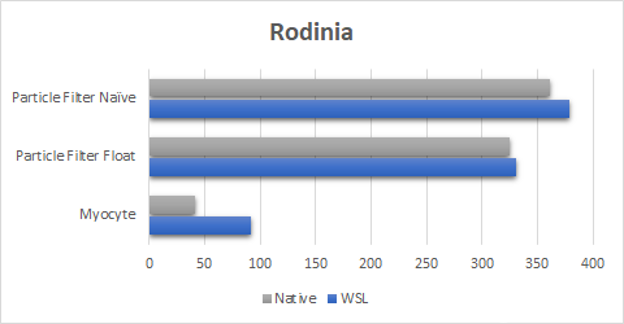
图 2 。 Rodinia 基准测试套件结果( WSL2 与本机比较,结果以秒为单位,越低越好)。
谈到 Rodinia 基准测试套件(图 2 ),我们在第一次启动对 WSL2 的支持时已经取得了很大的成绩。
新的驱动程序可以执行得更好,甚至可以达到接近粒子过滤器测试的本机执行时间。它也最终缩小了心肌细胞基准的差距。这对于 Myocyte 基准测试尤其重要,与本机 Linux 相比, WSL2 的早期结果慢了 10 倍。 Myocyte 在 WSL2 上特别难,因为这个基准由许多非常小的顺序提交(小于微秒)组成,使其成为顺序启动延迟微基准。这是我们正在调查的一个领域,以实现完全的性能对等。
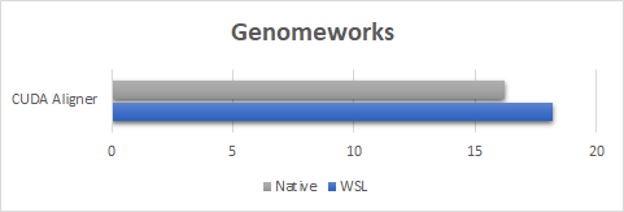
图 3 。 GenomeWorks CUDA 对齐器示例执行时间( WSL2 与本机比较,结果以秒为单位,越低越好) 。
对于 GenomeWorks 基准测试(图 3 ),我们使用 CUDA 对齐器进行 GPU 加速成对对齐。为了显示性能开销的最坏情况,这里的基准测试运行是使用由短时间运行的内核组成的样本数据集完成的。由于内核启动有多短,您可以观察 WSL2 上的启动延迟开销。但是,即使对于这个最坏的示例,性能也等于或超过本机速度的 90% 。我们的期望是,对于数据集大小通常较大的实际用例,性能将接近本机性能。
要探索内核大小和 WSL2 性能之间的关键权衡,请查看下一个基准测试。
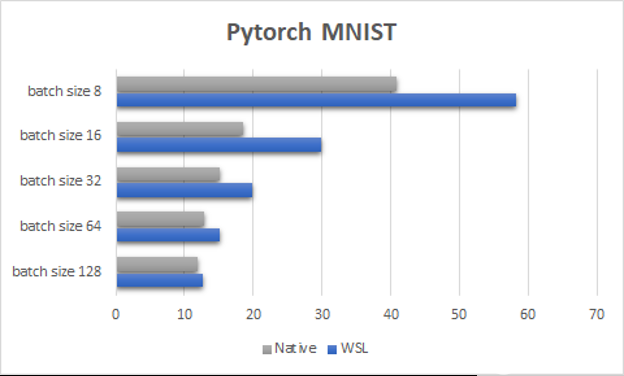
图 4 。 PyTorch MNIST 每个历元的采样时间,具有不同的批大小( WSL2 与本机,结果以秒为单位,越低越好) 。
图 4 显示了 PyTorch MNIST 测试,这是一个专门设计的小型玩具机器学习示例,它强调了让 GPU 保持忙碌以在 WSL2 上达到令人满意的性能是多么重要。与本机 Linux 一样,工作负载越小,启动 GPU 进程的开销越可能导致性能下降。这种降级在 WSL2 上更为明显,与本机 Linux 相比,其扩展性也有所不同。
随着对 WSL2 驱动程序的不断改进,对于非常小的工作负载,这种伸缩性差异应该越来越不明显。在 WSL2 和本机 Linux 上避免这些陷阱的最佳方法是尽可能使 GPU 保持忙碌。
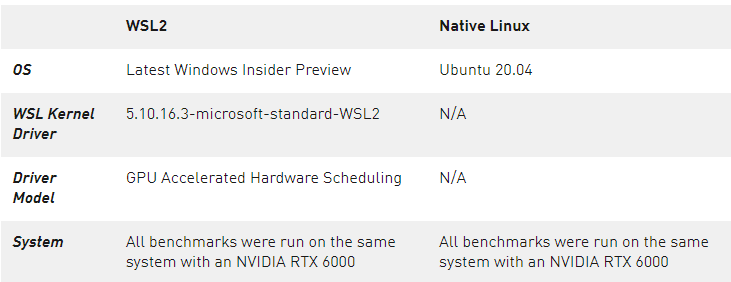
表 1 。用于基准测试的系统配置和软件版本
。

表 2 。使用的基准测试名称以及每个测试的简要说明
。
启动延迟优化
启动延迟是一些本机 Linux 应用程序与 WSL2 之间性能差异的主要原因之一。这里有两个重要指标:
GPU 内核启动延迟: 通过 CUDA 调用启动内核并由 GPU 启动执行所需的时间。
端到端开销 (启动延迟加上同步开销):通过 CUDA 调用启动内核并在 CPU 上等待其完成所需的总时间,不包括内核运行时本身。
当推送到 GPU 上的工作负载明显大于延迟本身时,启动延迟通常可以忽略不计。多亏了 CUDA 原语(如流和图),您可以让 GPU 保持忙碌,并可以利用这些 API 的异步特性来克服任何延迟问题。但是,当发送到 GPU 的工作负载的执行时间接近启动延迟时,它很快就会成为一个主要的性能瓶颈。启动延迟将充当启动速率限制器,这将导致内核执行性能下降。
本机 Windows 上的启动延迟
在深入探讨在 WSL2 上启动延迟是一个需要克服的重大障碍之前,我们先解释一下本机 Windows 上 CUDA 内核的启动路径。 CUDA Windows 驱动程序中实现了两种不同的启动模型:一种用于数据包调度,另一种用于硬件加速 GPU 调度。
分组调度
在数据包调度中,操作系统负责大部分的调度工作。然而,为了补偿提交模型和显著的启动开销, CUDA 驱动程序总是尝试基于各种启发式方法批处理一定数量的内核启动。图 5 显示,在数据包调度模式下,操作系统调度提交,并针对给定上下文对提交进行序列化。这意味着一次提交的所有工作必须在下一次提交的任何工作开始之前完成。
为了提高数据包调度模式下的吞吐量, CUDA 驱动程序尝试在一次提交中聚合一些启动,即使它们在内部跨多个 GPU 队列调度。这种启发式方法有助于解决错误依赖性和并行性问题,还可以减少提交的数据包数量,减少调度开销时间。
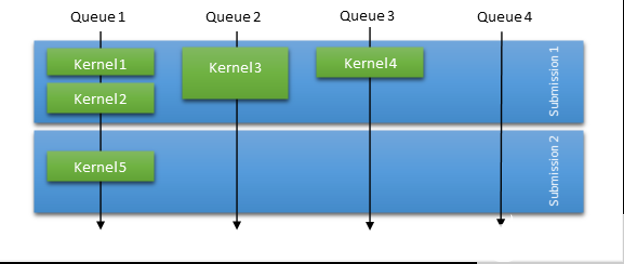
图 5 。 WDDM 数据包调度模型概述及其在 CUDA 驱动程序中的使用 。
在这个提交模型中,当工作负载受启动延迟限制时,您会看到性能达到极限。您可以通过查询具有较小挂起工作负载的流的状态,强制发布未完成的提交。在这种情况下,除了必须处理潜在的错误依赖项外,它还面临着高调度开销。
硬件加速 GPU 调度
最近,微软推出了一种称为硬件加速 GPU 调度的新模式。使用此模型,可以直接为给定上下文公开硬件队列,并且用户模式驱动程序(在本例中为 CUDA )全权负责管理工作提交和工作项之间的依赖关系。它消除了将多个内核启动批处理到单个提交中的需要,使您能够采用与本地 Linux 驱动程序相同的策略,在本地 Linux 驱动程序中,工作提交几乎是即时的(图 6 )。
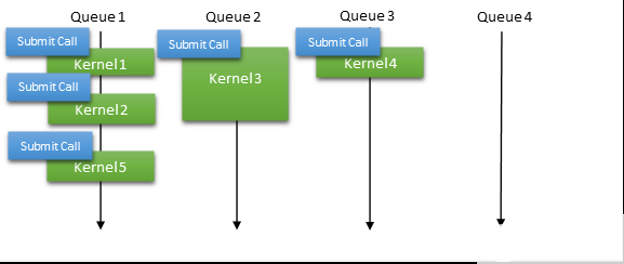
图 6 。 CUDA 驱动程序中使用的 WDDM 硬件调度模型概述 。
这种基于硬件调度的提交模型消除了错误的依赖性,避免了缓冲的需要。它还通过将以前在 CPU 上处理的一些操作系统调度任务卸载到 GPU 来减少开销。
在 WSL2 上利用硬件加速 GPU 调度
为什么这些日程安排细节很重要?传统上,本机 Windows 应用程序设计为隐藏较高的延迟。然而,对于本机 Linux 应用程序来说,启动延迟从来不是一个因素,在本机 Linux 应用程序中,延迟影响性能的阈值比 Windows 上的阈值小一个数量级。
当这些相同的 Linux 应用程序在 WSL2 中运行时,启动延迟变得更加突出。在这里,硬件加速 GPU 调度的好处可以抵消延迟导致的性能损失,因为 CUDA 在 WSL2 和本机 Windows 上采用了与本机 Linux 相同的提交策略。我们强烈建议在运行 WSL2 时切换到硬件加速 GPU 调度模式。
即使使用硬件加速的 GPU 调度,向 GPU 提交工作仍然是通过调用操作系统完成的,就像在数据包调度中一样。不仅提交,而且在某些情况下,同步 MIG ht 还必须进行一些操作系统调用以进行错误检测。在 WSL2 上对操作系统的每次此类调用都涉及跨越 WSL2 边界,通过 VMBUS 到达主机内核模式。这可能很快成为驱动程序的单一瓶颈(图 7 )。同时进行小批量 GPU 工作的 Linux 应用程序可能仍然不能很好地运行。
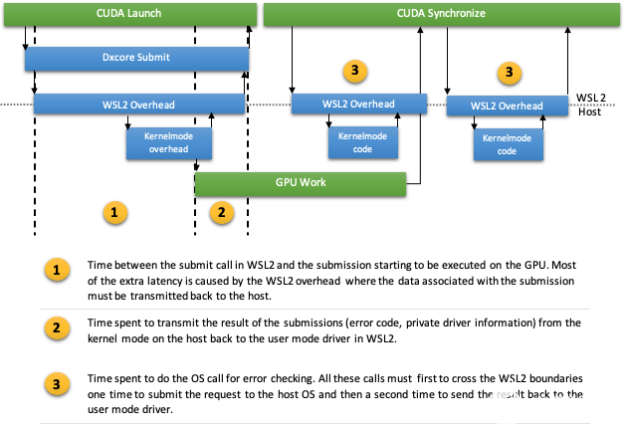
图 7 。 WSL2 上提交路径的概述以及额外开销的各个位置 。
异步提交以减少启动延迟
我们找到了一个解决方案,通过 Microsoft 更改提交调用的异步性来减轻 WSL 上额外的启动延迟。通过利用此调用,您可以在提交过程中开始重叠其他操作,并以这种方式隐藏额外的 WSL 开销。由于 submit 调用的新异步特性,启动延迟现在可与本机 Windows 媲美。
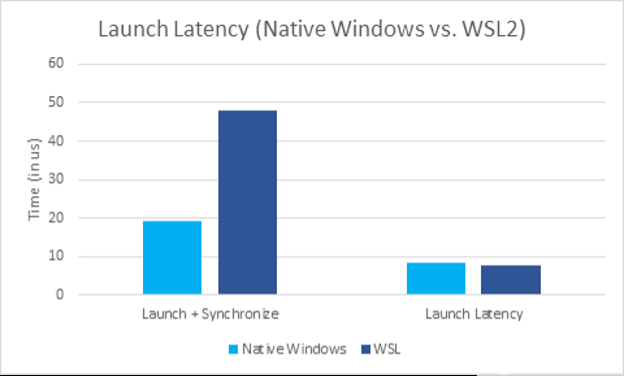
图 8 。 WSL2 和本机 Windows 上启动延迟的微基准 。
尽管在同步路径中进行了优化,但与本机 Windows 相比,在提交时启动和同步的总开销仍然更高。点 1 的 VMBUS 开销导致了这一点,而不是同步路径本身(图 7 )。这种影响可以在图 8 中看到,在图 8 中,我们测量了一次发射的开销,然后是同步。 VMBUS 引起的额外延迟是显而易见的。
使提交调用异步并不一定完全消除启动延迟成本。相反,它使您能够通过同时执行其他操作来抵消它。例如,一个应用程序可以在一个流上通过管道进行多次启动,前提是内核启动足够长,可以覆盖额外的延迟。在这种情况下,这一成本可以被隐藏起来,并设计成只有在一系列提交的开始时才可见。
简而言之,我们已经并将继续改进和优化 WSL2 的性能。尽管有到目前为止提到的所有优化,但如果应用程序在 GPU 上没有管道化足够的工作负载,或者更糟糕的是,如果工作负载太小,那么本机 Linux 和 WSL2 之间的性能差距将开始出现。这也是为什么 WSL2 和本机 Linux 之间的比较具有挑战性,并且在不同的基准测试中差异很大。
假设应用程序正在进行足够多的流水线工作,以隐藏延迟开销,并在应用程序的整个生命周期内保持 GPU 忙碌。使用当前的一组优化,性能很可能接近甚至与本机 Linux 应用程序相当。
当应用程序提交的 GPU 工作负载不足以克服该延迟时,本机 Linux 和 WSL2 之间的性能差距将开始出现。间隔与总延迟和一次推送的工作大小之间的差异成正比。
这也是为什么,尽管在这方面做了很多改进,我们仍将继续关注减少延迟,使其越来越接近本机 Linux 。
新的分配优化
我们关注的另一个领域是内存分配。与启动延迟(只要应用程序在 GPU 上启动工作,启动延迟就会影响性能)不同,内存分配主要影响程序的启动、加载和卸载阶段。
这并不意味着它不重要;远非如此。即使与仅提交 GPU 上的工作相比,这些操作并不频繁,但相关的驱动程序开销通常要高出一个数量级。一次分配几兆字节最终需要几毫秒才能完成。
为了优化此路径,我们的主要方法之一是在 CUDA 中启用异步分页操作。这种功能在 Windows 显示驱动程序模型中已经使用了一段时间,但 CUDA 驱动程序直到现在才使用它。此策略的主要优点是,您可以退出分配调用,并将控制权交还给用户代码。您不必等待昂贵的 GPU 操作完成,例如更新页表。相反,等待被推迟到引用分配的下一个操作。
这不仅可以改善 CPU 和 GPU 工作之间的重叠,而且还可以完全消除等待。如果分页操作提前完成, CUDA 驱动程序可以通过监听映射的围栏值来避免发出 OS 调用以等待分页操作。在 WSL2 上,这一点尤为重要。只要避免调用主机内核模式,就可以避免 VMBUS 开销。
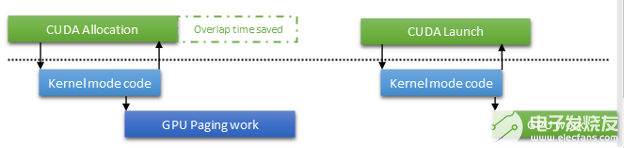
图 9 。在 CUDA 驱动程序中完成的分配异步映射概述。
我们到了吗?
在过去的几个月里,我们在 WSL2 性能方面取得了长足的进步,现在我们看到许多基准测试的结果与本机 Linux 相当或接近。这并不意味着我们已经达到了目标,我们将停止优化驱动程序。一点也不!
首先,微软目前正在研究硬件调度的未来优化, MIG ht 使我们能够将启动开销降至最低。同时,在这些功能完全开发之前,我们将继续优化 WSL 上的 CUDA 驱动程序,并为本机 Windows 提供建议。
其次,我们将关注通过某种特殊形式的内存拷贝快速高效地分配内存。我们还将很快开始研究 WSL2 上更好的多 GPU 功能和优化,以使更密集的工作负载能够快速运行。
WSL2 是 NVIDIA 完全受支持的平台,它将获得 CUDA 为其所有其他受支持平台所努力提供的相同功能和性能重点。我们的目的是使 WSL2 性能更好并适合开发。我们还将使其成为一个 CUDA 平台,它对每个用例都有吸引力,性能尽可能接近任何本机 Linux 系统。
最后,但并非最不重要的一点是,我们衷心感谢开发人员社区在过去一年中迅速采用 GPU 加速 WSL2 预览、报告问题并不断提供反馈。通过与我们分享我们 MIG ht 在其他方面错过的性能用例,您帮助我们发现了潜在的问题,并在性能方面取得了长足的进步。如果没有您坚定不移的支持, WSL2 上的 GPU 加速将不会达到今天的水平。我们期待着与社区进一步合作,努力实现 CUDA 在 WSL2 上的未来里程碑。
要访问驱动程序安装程序和文档,请注册 NVIDIA 开发人员计划 和 Microsoft Windows Insider 程序 。
以下资源包含有助于您了解 CUDA 如何使用 WSL2 的宝贵信息,包括如何开始运行应用程序和深入学习容器:
WSL 上的 CUDA 下载页面
WSL 用户指南上的 CUDA
在 Linux 2 的 Windows 子系统上宣布 CUDA
GPU 在 Linux 的 Windows 子系统中加速了 ML 培训
什么是 WSL ?
使用 WSL2 ( Linux 的 Windows 子系统)在 Microsoft Windows 10 上运行 RAPIDS
关于作者
Raphael Boissel 领导 Windows 平台的 CUDA 工程。他拥有法国工程学院 EPITA 计算机科学硕士学位。
Arthy Sundaram 是 CUDA 平台的技术产品经理。她拥有哥伦比亚大学计算机科学硕士学位。她感兴趣的领域是操作系统、编译器和计算机体系结构。
审核编辑:郭婷
-
cpu
+关注
关注
68文章
10942浏览量
213784 -
gpu
+关注
关注
28文章
4828浏览量
129728 -
Linux
+关注
关注
87文章
11372浏览量
211161
发布评论请先 登录
相关推荐
无法在Windows Subsystem for Linux 2上使用对象检测Python演示运行YoloV4模型?
RHEL即将成为微软WSL的官方Linux发行版
用SecureCRT连接串口却没有登录Ubuntu界面
在MATLAB中开发状态监控算法






 工商网监
工商网监
评论