 通过利用机器学习模型破译古籍
通过利用机器学习模型破译古籍
为了揭示过去的秘密,世界各地的历史学者花费毕生精力翻译古代手稿。圣母大学的一个研究小组希望帮助这项任务,用一种新开发的机器学习模型来翻译和记录几百年前的手写文档。
利用圣加尔修道院图书馆的数字化手稿和一个考虑到人类感知的机器学习模型 study 在深度学习转录能力方面有显著提高。
“我们正在处理历史文件,这些文件的书写风格早已过时,可以追溯到几个世纪以前,并且使用拉丁语等语言,而拉丁语已经很少使用了。你可以得到这些材料的美丽照片,但我们已经着手做的是以一种模仿专家读者眼睛对页面感知的方式自动转录,并提供快速、可搜索的文本阅读,”圣母大学副教授、资深作者沃尔特·舍勒在新闻稿中说。
圣加尔修道院图书馆建于 719 年,是世界上最古老、最丰富的图书馆藏品之一。该图书馆藏有大约 160000 卷书和 2000 份手稿,可追溯到八世纪。在羊皮纸上用现在很少使用的语言手工书写,这些材料中的许多尚未被阅读——这是一笔潜在的历史档案财富,等待发掘。
机器学习方法能够自动转录这些类型的历史文件已经在工作中,但挑战仍然存在。
到目前为止,大型数据集对于提高这些语言模型的性能是必不可少的。由于可供查阅的书籍数量巨大,这项工作需要时间,并且需要相对较少的专家学者进行注释。缺少知识,如从未编纂过的中世纪拉丁语词典,构成了更大的障碍。
该团队将传统的机器学习方法与研究物理世界和人类行为之间关系的视觉心理物理学相结合,以创建更多信息丰富的注释。在这种情况下,他们在处理古代文本时将人类视觉测量纳入神经网络的训练过程。
“这是机器学习中通常不使用的策略。我们通过这些心理物理测量来标记数据,这些测量直接来自于通过行为测量对感知进行的心理学研究。然后,我们通知网络在感知这些角色方面的常见困难,并可以根据这些测量结果进行纠正,” Scheirer 说。
为了训练、验证和测试这些模型,研究人员使用了一套来自圣加尔的可追溯到九世纪的数字化手写拉丁手稿。他们要求专家阅读并将文本行中的手动抄本输入定制的软件中。测量每次抄写的时间,可以洞察单词、字符或段落的难度。根据作者的说法,这些数据有助于减少算法中的错误,并提供更真实的读数。
所有的实验都是使用 cuDNN-accelerated PyTorch 深度学习框架和 GPU 。“如果没有 NVIDIA 硬件和软件,我们肯定不可能完成我们所做的事情。
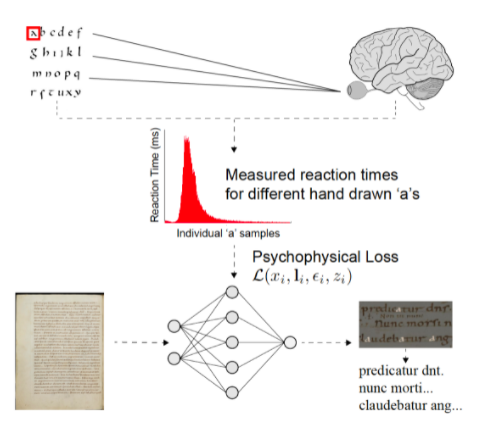
该研究引入了一种新的深度学习损失公式,该公式结合了人类视觉测量,可应用于手写文档转录的不同处理管道。信贷: Scheirer 等人/ IEEE
团队仍在努力改进某些方面。损坏和不完整的文档以及插图和缩写对模型提出了特殊的挑战。
“由于互联网规模的数据和 GPU 硬件,人工智能达到了拐点,这将使文化遗产和人文学科与其他领域一样受益。我们只是初步了解我们可以对这个项目做些什么。
关于作者
Michelle Horton 是 NVIDIA 的高级开发人员通信经理,拥有通信经理和科学作家的背景。她在 NVIDIA 为开发者博客撰文,重点介绍了开发者使用 NVIDIA 技术的多种方式。
审核编辑:郭婷
-
gpu
+关注
关注
28文章
4739浏览量
128940 -
互联网
+关注
关注
54文章
11154浏览量
103299 -
机器学习
+关注
关注
66文章
8418浏览量
132624
发布评论请先 登录
相关推荐
《具身智能机器人系统》第7-9章阅读心得之具身智能机器人与大模型
什么是机器学习?通过机器学习方法能解决哪些问题?

AI大模型与深度学习的关系
AI大模型与传统机器学习的区别
构建语音控制机器人 - 线性模型和机器学习
【《时间序列与机器学习》阅读体验】+ 时间序列的信息提取
【《大语言模型应用指南》阅读体验】+ 基础知识学习
【《大语言模型应用指南》阅读体验】+ 基础篇
Al大模型机器人
人工神经网络与传统机器学习模型的区别
【大语言模型:原理与工程实践】揭开大语言模型的面纱

通过新的ONNX导出器简化模型导出流程







 工商网监
工商网监
评论