 ML从业者如何阅读研究论文
ML从业者如何阅读研究论文
数据科学家或机器学习专家有必要阅读研究论文吗?
简而言之,答案是肯定的。如果你没有正式的学术背景,或者只获得了机器学习领域的本科学位,也不要担心。
对于没有广泛教育背景的个人来说,阅读学术研究论文可能会有威胁。然而,缺乏学术阅读经验不应妨碍数据科学家利用 machine learning 和 AI development 的宝贵信息和知识来源。
这篇文章为任何技能水平的数据科学家提供了一个实践教程,他们可以阅读 NeurIPS 、 JMLR 、 ICML ,以及 等学术期刊上发表的研究论文。
在全神贯注于如何阅读研究论文之前,学习如何阅读研究论文的第一阶段包括选择相关主题和研究论文。
步骤 1 :确定一个主题
机器学习和数据科学领域拥有大量可以研究的学科领域。但这并不一定意味着在机器学习中处理每个主题是最好的选择。
虽然建议入门级实践者进行泛化,但我猜当涉及到长期机器学习时,职业前景、实践者和行业兴趣通常会转向专业化。
确定一个适合的主题可能很难,但很好。不过,经验法则是选择一个 ML 领域,你要么对获得专业职位感兴趣,要么已经有经验。
深度学习 是我的兴趣之一,我是一名计算机视觉工程师,在应用程序中使用深度学习模型专业地解决 computer vision 问题。因此,我对姿势估计、动作分类和手势识别等主题感兴趣。
基于角色,以下是 ML / DS 职业和相关主题要考虑的例子。

图 1 :机器学习和数据科学角色及相关主题。作者创造的形象 。
对于本文,我将选择姿势估计这一主题进行探索,并选择相关的研究论文进行研究。
第二步:寻找研究论文
在阅读与机器学习相关的研究论文、数据集、代码和其他相关材料时,最优秀的工具之一是 PapersWithCode 。
我们使用 PapersWithCode 网站上的搜索引擎来获取所选主题“姿势估计”的相关研究论文和内容下图显示了它是如何完成的。
搜索结果页面包含对搜索主题的简短说明,然后是相关数据集、模型、论文和代码的表格。在不深入太多细节的情况下,本用例感兴趣的领域是“最伟大的代码论文”。本节包含与任务或主题相关的论文。出于本文的目的,我将选择 DensePose :野外密集的人类姿势估计 。
第 3 步:第一步(获得背景和理解)
在这一点上,我们选择了一篇研究论文进行研究,并准备从其内容中提取任何有价值的经验教训和发现。
很自然,你的第一个冲动就是开始写笔记,从头到尾地阅读文档,也许在其间休息一下。然而,为研究论文的内容提供一个上下文是阅读它的一种更实际的方式。标题、摘要和结论是理解任何研究论文的三个关键部分。
您所选论文的第一关的目标是实现以下目标:
确保论文是相关的。
通过学习论文的内容、方法和发现,了解论文的背景。
认识作者的目标、方法和成就。
标题
标题是作者和读者之间信息共享的第一点。因此,研究论文的标题是直接的,并且以一种不会留下歧义的方式组成。
研究论文的标题是最能说明问题的方面,因为它表明了研究与你的工作的相关性。标题的重要性在于对论文的内容有一个简要的了解。
在这种情况下,标题是“ DensePose :野外密集的人类姿势估计”这提供了一个工作的广泛概述,并意味着它将研究如何在高活动水平和真实情况下提供姿势估计。
摘要
摘要部分给出了论文的摘要。这是一个简短的部分,包含 300-500 字,简单地告诉你这篇论文是关于什么的。摘要是一篇简短的文章,概述了文章的内容、研究人员的目标、方法和技巧。
在阅读机器学习研究论文摘要时,您通常会遇到提到的数据集、方法、算法和其他术语。与文章内容相关的关键字提供上下文。在这一点上记笔记和跟踪所有关键字可能会有所帮助。
对于论文“ DensePose :野外密集的人类姿势估计 ”,我在摘要中确定了以下关键词:姿势估计、 COCO 数据集、 CNN 、基于区域的模型、实时。
总结
在你第一次通过考试时,从上到下阅读论文时会感到疲劳是很常见的,尤其是对于没有高级学术经验的数据科学家和从业者来说。虽然在长时间的研究之后,从论文的后面部分提取信息可能看起来很乏味,但结论部分通常很短。因此,建议阅读第一遍的结论部分。
结论部分简要概述了该作品的作者和/或贡献、成就以及对未来发展和局限性的承诺。
在阅读研究论文的主要内容之前,先阅读结论部分,看看研究者的贡献、问题领域和结果是否符合你的需要。
遵循这一简单的第一步可以充分理解和概述研究论文的范围和目标,以及内容的背景。你可以用激光注意力再次浏览,从内容中获得更详细的信息。
第 4 步:第二关(内容熟悉)
内容熟悉是一个与初始步骤相关的过程。阅读本文研究论文的系统方法。熟悉过程是一个步骤,包括研究论文的引言部分和图表。
如前所述,不需要直接深入研究论文的核心,因为知识适应可以在以后的过程中更轻松、更全面地检查研究。
介绍
研究论文的导论部分旨在概述研究工作的目标。该目标提及并解释了问题领域、研究范围、先前的研究工作和方法。
使用相似或不同的方法,在这一领域找到与过去研究工作相似的地方是很正常的。其他论文的引用提供了问题领域的范围和广度,为读者拓宽了探索领域。在这一点上,合并步骤 3 中概述的程序就足够了。
导言部分提供的另一个好处是提供了接触和理解研究论文内容所需的必要知识。
图表
研究论文中的说明性材料确保读者能够理解支持问题定义或所提出方法解释的因素。通常,研究论文中使用表格来提供与类似方法相比的新技术定量性能的信息。
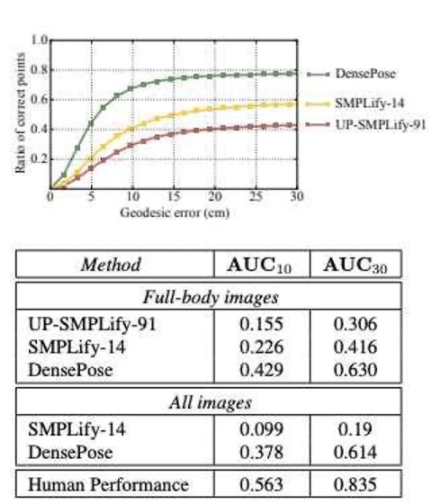
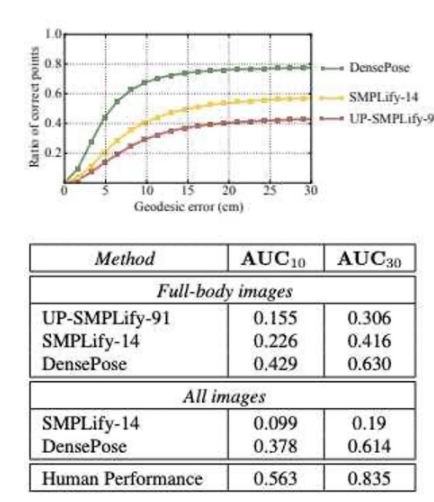
图 4 : 显示 DensePose 与其他单人姿势估计解决方案比较的图像。
一般来说,数据和性能的可视化表示可以帮助您直观地理解论文的上下文。在前面提到的密集姿势论文中,使用插图描述了作者姿势估计和创建方法的性能。全面了解生成和注释数据样本所涉及的步骤。
在深度学习领域,经常会发现描述人工神经网络结构的拓扑图。这再次为任何读者创造了直观的理解。通过插图和数字,读者可以自己解释信息,并获得更全面的观点,而不必对结果有任何先入为主的概念。
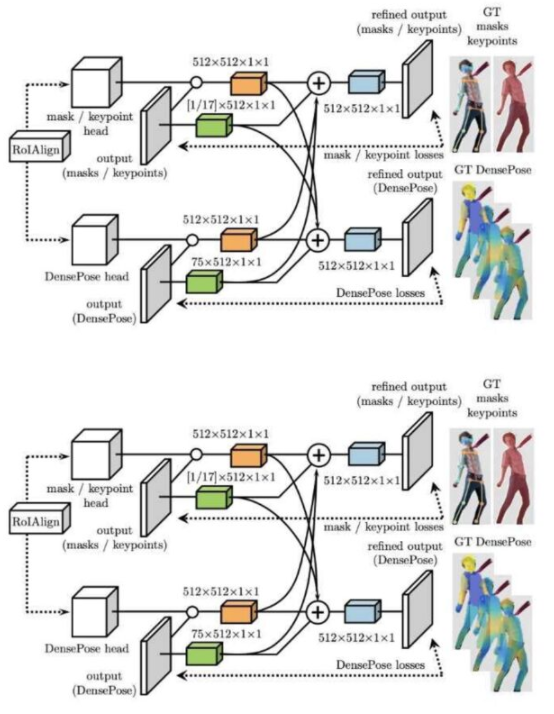
图 5 : 显示 DensePose 交叉级联架构的图像。
第五步:第三遍(深度阅读)
论文的第三遍与第二遍相似,尽管它涵盖了正文的大部分。关于这个过程最重要的一点是,你要避免任何复杂的算术或技术公式,这对你来说可能是困难的。在此过程中,您还可以跳过任何您不理解或不熟悉的单词和定义。应注意这些不熟悉的术语、算法或技术,以便稍后返回。
在本课程中,你的主要目标是对论文内容有一个广泛的了解。接近论文,从摘要到结论再开始,但一定要在各部分之间进行中间休息。此外,建议有一个记事本,在记事本中记录所有重要的见解和收获,以及不熟悉的术语和概念。
Pomodoro 技术是管理深度阅读或学习时间的有效方法。简单地说, Pomodoro 技术将一天分成几部分工作,然后是短暂的休息。
对我有效的是 50 / 15 分割,也就是说, 50 分钟的学习和 15 分钟的休息时间。我倾向于在延长 30 分钟的休息时间之前,连续执行两次分割。如果您不熟悉这种时间管理技巧,请采用相对简单的划分,如 25 / 5 ,并根据您的注意力和时间容量调整时间划分。
第六步:第四关(最后一关)
最后一关通常涉及到发挥你的智力和学习能力,因为它涉及到在前一关中提到的不熟悉的术语、术语、概念和算法。这一关的重点是使用外部材料来理解论文中记录的不熟悉的方面。
对不熟悉的主题进行深入研究没有规定的时间长度,有时甚至需要几天或几周的时间。最终成功通过的关键因素是为进一步勘探找到合适的油源。
不幸的是,互联网上没有一个来源能提供你所需要的丰富信息。尽管如此,有多个来源,如果协调使用并适当使用,可以填补知识空白。下面是其中的一些资源。
机器学习子系统
深度学习子系统
PapersWithCode
顶级会议搜索为 NIPS 、 ICML 、 ICLR
Research Gate
机器学习苹果
研究论文的参考部分提到了技术和算法。因此,当前的论文要么从中汲取灵感,要么以之为基础,这就是为什么参考部分是一个有用的来源,可用于您的深度阅读课程。
步骤 7 :摘要(可选)
在近十年的与技术相关的学科和角色的学术和专业研究中,通过重述所探索的主题,确保所学到的任何新信息保留在我的长期记忆中的最有效方法。通过用我自己的语言重写新信息,无论是书面的还是打字的,我都能够以一种可理解和令人难忘的方式强化提出的观点。
更进一步,可以通过博客平台和社交媒体宣传学习成果和笔记。试图向广大读者解释新探索的概念,假设读者不习惯该主题或主题,则需要理解主题的内在细节。
结论
毫无疑问,为新手数据科学家和 ML 实践者阅读研究论文是令人畏惧和具有挑战性的;即使是经验丰富的实践者也发现很难一次成功地消化研究论文的内容。
数据科学专业的性质是非常实用和涉及的。这意味着,数据科学领域与人工智能密切相关,人工智能仍然是一个发展中的领域,因此,它的从业者必须具备学术思维。
总而言之,以下是阅读研究论文应遵循的所有步骤:
确定一个主题。
寻找相关研究论文
阅读标题、摘要和结论,对研究工作目标和成果有一个模糊的理解。
通过深入介绍,熟悉内容;包括对文中给出的图形和图表的探索。
在自上而下阅读论文的过程中,利用深度阅读课程来消化论文的主要内容。
使用外部资源探索不熟悉的术语、术语、概念和方法。
用你自己的话总结基本的要点、定义和算法。
关于作者
Richmond Alake 是一名机器学习和计算机视觉工程师,他与多家初创公司和公司合作,整合深度学习模型,以解决商业应用中的计算机视觉任务。
审核编辑:郭婷
-
机器学习
+关注
关注
66文章
8406浏览量
132563 -
深度学习
+关注
关注
73文章
5500浏览量
121111
发布评论请先 登录
相关推荐
【「大话芯片制造」阅读体验】+内容概述,适读人群
学嵌入式好找工作吗?
贝思科尔ReviewHub在线评审工具开放限时免费试用名额,快速领取!

贝思科尔DX-BST原理图智能工具,限时免费试用开启,不容错过!

名单公布!【书籍评测活动NO.50】亲历芯片产线,轻松图解芯片制造,揭秘芯片工厂的秘密
特征工程实施步骤

大数据从业者必知必会的Hive SQL调优技巧
半导体封装材料全解析:分类、应用与发展趋势!






 工商网监
工商网监
评论