 状态向量模拟和cuStateVec库的介绍
状态向量模拟和cuStateVec库的介绍
量子计算渴望为某些类型的经典难题提供更强大的计算能力和更快的结果。量子电路模拟对于理解量子计算和量子算法的发展至关重要。在量子电路中,量子器件由 N 量子位组成,通过对量子位应用一系列量子门和测量来执行计算。
从数学上来说, N 量子比特系统的量子态可以描述为一个复杂的 2 N – 维向量。在经典计算机上模拟量子电路最直观的方法是状态向量模拟,它将这个向量与其 2 N 复杂值直接存储在内存中。该电路通过将向量乘以一系列矩阵来执行,这些矩阵对应于构成该电路的门序列。
然而,随着状态向量的维数随着量子位的数量呈指数增长,完整描述状态的内存需求将这种方法限制在 30 – 50 量子位的电路中。基于张量网络的替代方法可以模拟更多的量子位,但通常在能够有效模拟的电路的深度和复杂性方面受到限制。
NVIDIA cuQuantum SDK 具有用于状态向量和张量网络方法的库。在本文中,我们将重点介绍状态向量模拟和 cuStateVec 库。有关张量网络方法库的更多信息,请参阅 利用 NVIDIA cuTensorNet 进行量子电路模拟 。
cuStateVec 图书馆
cuStateVec 库提供了单个 GPU 原语来加速状态向量模拟。由于状态向量方法是模拟量子电路的基础,大多数量子计算框架和库都包含自己的状态向量模拟器。为了便于与这些现有模拟器集成, cuStateVec 提供了一套 API ,以涵盖常见用例:
测量
门应用
期望值
采样器
状态向量运动
测量
一个量子位可以存在于两个态|0》和|1》的叠加中。当进行测量时,其中一个值被概率选择和观察,另一个值崩溃。 cuStateVec 测量 API 模拟量子位测量,并支持基于 Z 基产品的测量用例和批量单量子位测量。
门应用
量子电路有量子逻辑门来修改和准备量子态,以观察理想的结果。量子逻辑门用酉矩阵表示。 cuStateVec gate 应用程序 API 提供了将量子逻辑门应用于某些矩阵类型的功能,包括:
稠密的
斜线的
广义置换
泡利矩阵的矩阵指数
期望值
在量子力学中,计算算符和量子态的期望值。对于量子电路,我们还计算了给定电路和量子态的期望值。 cuStateVec 有一个 API ,可以用较小的内存占用计算期望值。
采样器
状态向量模拟在数值上将量子态保留在状态向量中。通过计算每个状态向量元素的概率,您可以有效地多次模拟多个量子位的测量,而不会破坏量子态。 cuStateVec sampler API 以较小的内存占用在 GPU 上执行采样。
状态向量运动
将状态向量放置在 GPU 上,以加速 GPU 的模拟。要在 CPU 上分析模拟结果,请将生成的状态向量复制到 CPU 。 cuStateVec 提供访问器 API 来代表用户执行此操作。在复制过程中,状态向量元素的顺序可以被重新安排,这样你就可以将量子位重新排序为所需的量子位顺序。
谷歌 Cirq / qsim 和 NVIDIA cuStateVec
宣布NVIDIA CuStEVEEC 文库集成的第一个项目是 Google’s qsim ,一个优化的模拟器,用于他们的量子计算框架, Cirq 。 Google Quantum 人工智能团队通过一个新的基于 cuStateVec 的 GPU 模拟后端扩展了 qsim ,以补充他们的 CPU 和 CUDA 模拟引擎。
使用 cuStateVec 为 Cirq 和 qsim 构建说明
要通过 Cirq 启用 cuStateVec ,请从源代码编译 qsim ,并安装 qsimcirq Python 包提供的 Cirq 绑定。
# Prerequisite: # Download cuQuantum Beta2 from https://developer.nvidia.com/cuquantum-downloads # Extract cuQuantum Beta2 archive and set the path to CUQUANTUM_ROOT $ tar -xf cuquantum-linux-x86_64-0.1.0.30-archive.tar.xz $ export CUQUANTUM_ROOT=`pwd`/cuquantum-linux-x86_64-0.1.0.30-archive $ ln -sf $CUQUANTUM_ROOT/lib $CUQUANTUM_ROOT/lib64 # Clone qsim repository from github and checkout v0.11.1 branch $ git clone https://github.com/quantumlib/qsim.git $ git checkout v0.11.1 # Build and install qsimcirq with cuStateVec $ pip install . # Install cirq $ pip install cirq
在本例中,我们运行一个电路,创建格林伯格 – 霍恩 – 齐林格( GHZ )状态,并对实验结果进行采样。以下 Python 脚本通过调用三个不同的模拟器来获取|0…00>和|1…11>中的振幅:
- Cirq 内置模拟器
- 基于 CPU 的模拟器共享
- 使用 cuStateVec 加速拆分
我们启用了两个基于 CIRQS 和 77YC 的 CPU 插槽,这两个插槽分别用于基于 CPU 的 CPU 模拟器。对于 cuStateVec 加速模拟,我们使用单个 A100 GPU 。
import cirq
import qsimcirq
n_qubits = 32
qubits = cirq.LineQubit.range(n_qubits)
circuit = cirq.Circuit()
circuit.append(cirq.H(qubits[0]))
circuit.append(cirq.CNOT(qubits[idx], qubits[idx + 1]) \ for idx in range(n_qubits - 1))
# Cirqs = cirq.sim.Simulator()
result = s.compute_amplitudes(circuit, [0, 2**n_qubits-1])
print(f'cirq.sim : {result}')
# qsim(CPU)
options = qsimcirq.QSimOptions(max_fused_gate_size=4, cpu_threads=512)
s = qsimcirq.QSimSimulator(options)
result = s.compute_amplitudes(circuit, [0, 2**n_qubits-1])
print(f'qsim(CPU) : {result}')
# qsim(cuStateVec)
options = qsimcirq.QSimOptions(use_gpu=True, max_fused_gate_size=4, gpu_mode=1)
s = qsimcirq.QSimSimulator(options)
result = s.compute_amplitudes(circuit, [0, 2**n_qubits-1])
print(f'cuStateVec: {result}')
以下控制台输出显示,通过使用 CPU SIMD 指令和 OpenMP 进行优化, qsim 的 CPU 版本比 Cirq 的模拟器快 5.1x 。通过使用 cuStateVec 版本,模拟速度进一步加快,比 Cirq 的模拟器快 30.04 倍,比 qsim 的 CPU 版本快 5.9 倍。
cirq.sim : [0.70710677+0.j 0.70710677+0.j], 87.51 s qsim(CPU) : [(0.7071067690849304+0j), (0.7071067690849304+0j)], 17.04 s cuStateVec: [(0.7071067690849304+0j), (0.7071067690849304+0j)], 2.88 s
绩效结果
下图显示了一些常用电路的门应用的初步性能结果。所有量子位计数的模拟都会加速。然而,随着量子位数量的增加,模拟速度显著加快,对于最大的电路,模拟速度大约是 10-20 倍。这种性能为探索更大量子电路的开发和评估提供了机会。
A100 与 64 核 CPU 上的 Cirq / qsim + cuStateVec
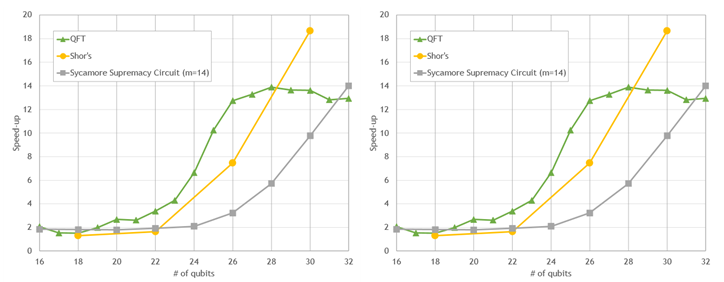
图 1 。与 64 核 EPYC 7742 CPU 上的 Cirq / qsim 相比,在单个 NVIDIA A100 GPU 上使用 cuStateVec 的流行量子电路的模拟性能
相对于 EPYC 7742 中的 64 个 CPU 内核,一个 NVIDIA A100 上的 VQE 加速
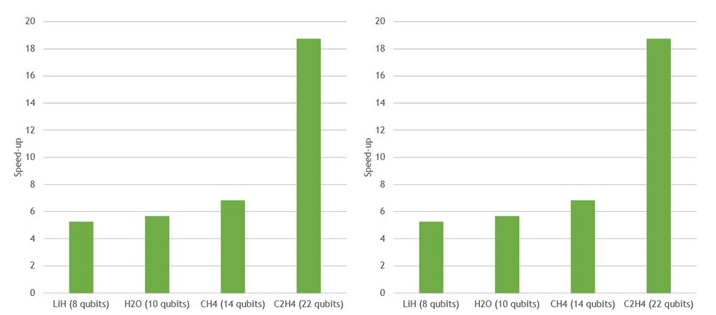
图 2 。与 64 核 EPYC 7742 CPU 上的 Cirq / qsim 相比,在单个 NVIDIA A100 GPU 上使用 cuStateVec 的多个不同分子的变分量子本征解算器加速
多 GPU 状态向量仿真
状态向量模拟也非常适合在多个 GPU 上执行。大多数门应用是一种完全并行的操作,通过拆分状态向量并将其分布在多个 GPU 上来加速。
在大约 30 个量子位之外,多 GPU 模拟是不可避免的。这是因为一个状态向量无法适应单个 GPU 的内存,因为它的大小随着附加的量子位呈指数增长。
当多个 GPU 在一个模拟中协同工作时,每个 GPU 可以将一个门并行应用于其状态向量部分。在大多数情况下,每个 GPU 只需要本地数据来更新状态向量,每个 GPU 都可以独立应用门。
然而,根据门作用于哪个模拟量子位, GPU 有时可能需要存储在不同 GPU 中的部分状态向量来执行更新。在这种情况下, GPU 必须交换大部分状态向量。这些部分的大小通常为数百兆字节或几千兆字节。因此,多 GPU 状态向量模拟对 GPU 互连的带宽非常敏感。
DGX A100 完全符合这些要求,八款 NVIDIA A100 GPU 使用 NVLink 提供 600GB / s 的 GPU 到 GPU 直接带宽。我们选择了三种 30-32 量子位的常见量子计算算法,在 DGX A100 上用 cuStateVec 对 Cirq / qsim 进行基准测试:
量子傅里叶变换( QFT )
肖尔算法
梧桐至上电路
与单次 GPU 运行相比,在八次 GPU 运行中,所有基准测试都显示出 4.5 – 7 倍加速之间良好的强缩放行为。
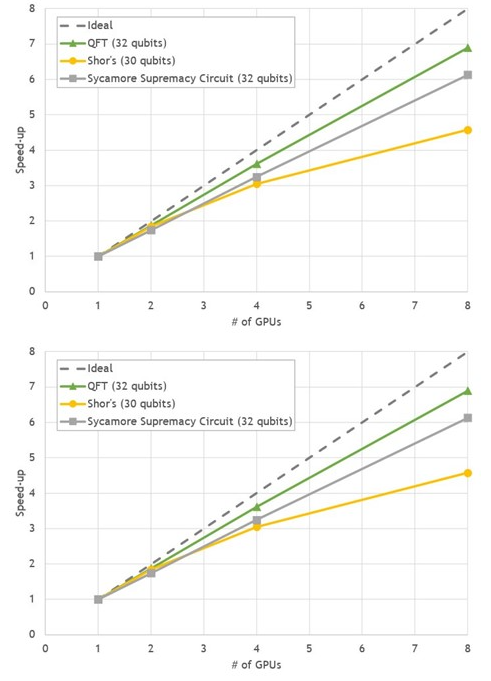
图 3 。 DGX A100 上流行电路状态向量模拟的多重 GPU 缩放
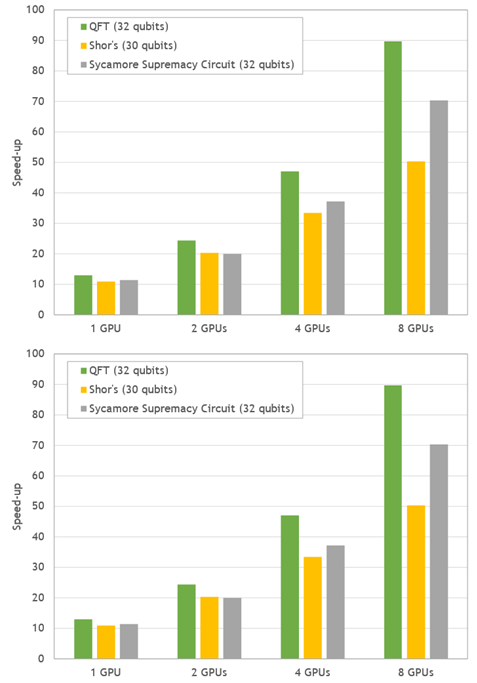
图 4 。流行量子电路模拟的加速比。在 DGX A100 上测量了 GPU 模拟的性能,并与 EPYC 7742 的两个插座的性能进行了比较。
与两个 64 核 CPU 上的模拟时间相比, DGX-A100 在 50-90 倍之间提供了令人印象深刻的整体速度提升。
总结
NVIDIA CuQuin SDK 中的 CuStEVEVEC 库旨在加速 GPU 上的量子电路的状态向量模拟器。谷歌针对 Cirq qsim 的模拟器是首批采用该库的模拟器之一,该库对现有程序的 GPU 加速使 Cirq 用户受益。随后将集成到更多量子电路框架,包括 IBM 的 Qiskit 软件。
我们也在扩大规模。基于 cuStateVec 的多 GPU 模拟的初步结果显示,关键量子算法的加速比为 50 – 90 倍。我们希望 cuStateVec 成为开创量子计算新领域的宝贵工具。
关于作者
Shinya Morino 是NVIDIA 高级解决方案架构师,隶属于NVIDIA 人工智能技术中心( NVAITC )。他已经在 NVAITC 中原型化了一个 GPU 加速状态向量模拟器,并正在利用他的知识推动 cuStateVec 的开发。新亚拥有日本东京大学的工程学博士学位。
Andreas Hehn 是NVIDIA 的开发技术工程师。他帮助客户使用 GPU 加速他们的科学工作流程,重点关注基因组学、高能物理实验和量子计算。安德烈亚斯拥有瑞士苏黎世 ETH 的物理学博士学位,他在那里从事大规模凝聚态物理模拟。
Leo Fang 是NVIDIA 的高级工程师,专注于 HPC 、量子计算和 Python 软件。 2017 年,他在杜克大学获得物理学博士学位。在加入 NVIDIA 之前,他是布鲁克海文国家实验室计算科学倡议的助理计算科学家。他也是许多开源项目的定期贡献者,包括 CuPy 、 mpi4py 、 conda forge 和 Python 数据 API 标准联盟。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
4994浏览量
103162 -
gpu
+关注
关注
28文章
4743浏览量
128995 -
API
+关注
关注
2文章
1502浏览量
62105
发布评论请先 登录
相关推荐
触发器的无效状态怎么判断
什么是IO模拟量模块?

玩转Spring状态机
请问STM8L052R8的USART2中断向量在哪?
IAP升级,boot和app分别是用标准库和HAL库写的,跳转不成功是怎么回事?
搭载英伟达GPU,全球领先的向量数据库公司Zilliz发布Milvus2.4向量数据库
Zilliz携手大模型生态企业玩转GDC 2024,向量数据库和RAG成行业焦点

与NVIDIA深度参与GTC,向量数据库大厂Zilliz与全球顶尖开发者共迎AI变革时刻
ocl电路工作在什么状态
什么是中断向量偏移,为什么要做中断向量偏移?
博途用户自定义库的使用-库的编辑及管理





 工商网监
工商网监
评论