 利用MLPerf 推理 1.1提升NVIDIA绩效领导力
利用MLPerf 推理 1.1提升NVIDIA绩效领导力

人工智能继续推动跨行业的突破性创新,包括消费互联网、医疗保健和生命科学、金融服务、零售、制造和超级计算。研究人员继续推动快速发展的模型在规模、复杂度和多样性方面的发展。此外,其中许多复杂的大规模模型需要为聊天机器人、数字助理和欺诈检测等人工智能支持的服务提供实时结果。
考虑到人工智能推理的广泛用途,评估性能对开发人员和基础设施管理人员提出了许多挑战。对于数据中心、 edge 和移动平台上的 AI 推理, MLPerf 推理 1.1 是一个行业标准基准,用于衡量计算机视觉、医学成像、自然语言和推荐系统的性能。这些基准由人工智能行业领导者组成的联盟制定,为人工智能培训和推理提供了当今最全面的同行评审绩效数据集。
要在这一基准测试中完成大量测试,需要一个具有强大生态系统支持的全堆栈平台,无论是框架还是网络。 NVIDIA 是唯一一家提交所有数据中心和边缘测试并提供全面领先性能的公司。
这项工作的一个重要副产品是,这些优化中的许多已经进入了推理开发工具,如TensorRT和 NVIDIA Triton 。用于高性能深度学习推理的 TensorRT SDK 包括一个深度学习推理优化器和运行时,为深度学习推理应用程序提供低延迟和高吞吐量。
Triton 推理服务器软件简化了人工智能模型在大规模生产中的部署。这种开源推理服务软件使团队能够在任何基于 GPU 或 CPU 的基础设施上从本地存储或云平台的任何框架部署经过培训的人工智能模型。
按数字
在数据中心和边缘两大类中, NVIDIA 凭借 NVIDIA A100 张量核 GPU 和 NVIDIA A30 张量核 GPU 在性能测试中名列榜首。自从 MLPerf 推断 0.7 的结果发布以来,在过去一年中, NVIDIA 仅通过软件改进就提高了 50% 的性能。
在另一个行业中, NVIDIA 首次使用基于 GPU – 加速 ARM 的服务器提交数据中心类别,该服务器支持所有工作负载,并提供与类似配置的基于 x86 的服务器相同的结果。这些基于 ARM 的新提交为 GPU 加速 ARM 服务器创造了新的性能世界记录。这标志着这些平台的一个重要里程碑,因为它们现在已经在同行评审的行业标准基准中证明了自己,以提供市场领先的性能。它还展示了 NVIDIA ARM 软件生态系统的性能、多功能性和就绪性,以应对数据中心的计算挑战。

图 1 。使用 Ampere Altra CPU s 的基于 ARM 的服务器提供的性能与类似配置的基于 x86 的服务器相当
MLPerf v1.1 推理关闭;每个加速器的性能源自使用数据中心脱机中报告的加速器计数的各个提交的最佳 MLPerf 结果。 x86 服务器: 1.1-034 、 ARM 服务器: 1.1-033 MLPerf 名称和徽标是商标。
综观整体表现, NVIDIA 全面领先。图 2 显示了服务器场景的结果,其中使用泊松分布为测试中的系统生成推理工作,以更紧密地模拟真实世界的工作负载模式。
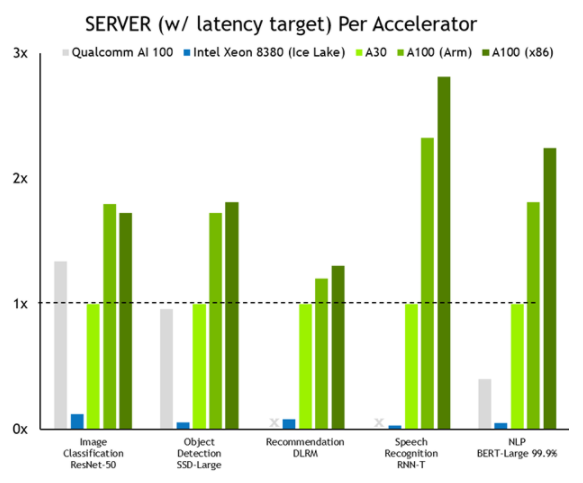
图 2 。 NVIDIA 与 CPU 纯服务器的性能比较
MLPerf v1.1 推理关闭;使用数据中心脱机和服务器中报告的加速器计数,从各个提交的最佳 MLPerf 结果中得出每个加速器的性能。高通 AI 100 : 1.1-057 和 1.1-058 ,英特尔至强 8380 : 1.1-023 和 1.1-024 , NVIDIA A30 : 1.1-43 , NVIDIA A100 ( ARM ): 1.1-033 , NVIDIA A100 ( x86 ): 1.1-047 。 MLPerf 名称和徽标是商标。
NVIDIA 比 CPU 纯服务器的性能全面提高了 104 倍。这种性能优势转化为对更大、更复杂的模型以及在对话 AI 、推荐系统和数字助理中实时作业中运行的多个模型进行推理的能力。
结果背后的优化
我们的工程团队实施了一些优化,使这些伟大的结果成为可能。首先,基于 ARM 的服务器和基于 x86 的服务器的所有这些结果都是使用 TensorRT 8 生成的,现在普遍可用。特别令人感兴趣的是双内核的非幂函数的使用,这是为了加速工作负载而实现的,比如 BERT – 大型单流场景测试。
NVIDIA 提交利用添加到 NVIDIA Triton 推理服务器的新主机策略功能。您可以在配置 NVIDIA Triton 服务器时指定主机策略,以在服务器应用程序中启用线程和内存固定。利用此功能, NVIDIA Triton 可以为系统中的每个 GPU 指定输入的最佳位置。最佳位置可以基于系统的非统一内存体系结构( NUMA )配置,在这种情况下,每个 NUMA 节点上都有一个查询样本库。
您还可以使用主机策略启用“从设备启动”配置设置,服务器将在选择执行的 GPU 上拾取输入。此设置还可以将网络输入直接输入 GPU 内存,完全绕过 CPU 和系统内存副本。
推理能力三人组: TensorRT , NVIDIA Triton 和 NGC
NVIDIA 推理领导力来自于构建最优秀的人工智能加速器,用于培训和推理。但同样重要的是支持所有 AI 框架和 800 多个 HPC 应用程序的 NVIDIA 端到端、全栈软件生态系统。
所有这些软件都可以在NGC、 NVIDIA 集线器上获得,该集线器带有 GPU ——用于深度学习、机器学习和 HPC 的优化软件。 NGC 负责所有管道,因此数据科学家、开发人员和研究人员可以专注于构建解决方案、收集 i NSight 并提供业务价值。
NGC 可通过您首选的云提供商的市场免费获得。在那里,您可以找到 TensorRT 和 NVIDIA Triton 的最新版本,这两个版本都有助于生成最新的 MLPerf 推断 1.1 结果。
关于作者
Dave Salvator 是 NVIDIA 旗下 Tesla 集团的高级产品营销经理,专注于超规模、深度学习和推理。
Jesus Corbal San Adrian 是 NVIDIA 计算架构组的杰出工程师,专注于深度学习推理 GPU 分析和优化。
Madhumitha Sridhara 是 TensorRT 团队的高级软件工程师,专注于使用 Triton 推理服务器的 NVIDIA MLPerf推理提交。她拥有卡内基梅隆大学计算机工程硕士学位和印度卡纳塔克邦苏拉特卡尔国家理工学院电子和通信工程学士学位。
审核编辑:郭婷
-
人工智能
+关注
关注
1819文章
50290浏览量
266826 -
机器学习
+关注
关注
67文章
8561浏览量
137208 -
深度学习
+关注
关注
73文章
5603浏览量
124609 -
MLPerf
+关注
关注
0文章
37浏览量
980
发布评论请先 登录
NVIDIA 推出 Alpamayo 系列开源 AI 模型与工具,加速安全可靠的推理型辅助驾驶汽车开发

DEKRA德凯荣获2025社会责任与可持续增长领导力奖
安波福荣获2025年度最佳实践奖之产品领导力大奖
NVIDIA TensorRT LLM 1.0推理框架正式上线
MediaTek携手NVIDIA开启个人AI算力新纪元
利用NVIDIA DOCA GPUNetIO技术提升MoE模型推理性能
什么是AI模型的推理能力
使用NVIDIA NVLink Fusion技术提升AI推理性能
NVIDIA Nemotron Nano 2推理模型发布

NVIDIA从云到边缘加速OpenAI gpt-oss模型部署,实现150万TPS推理

利用NVIDIA推理模型构建AI智能体

伟创力荣获制造业“奥斯卡”大奖 美国制造商协会颁发的“制造业领导力奖”

伟创力凭借在数字供应链领域的卓越成就,荣膺"2025年制造业领导力奖"




评论