 NVIDIA推理平台和全栈方法提供最佳性能
NVIDIA推理平台和全栈方法提供最佳性能

三个趋势继续推动着人工智能推理市场的训练和推理:不断增长的数据集,日益复杂和多样化的网络,以及实时人工智能服务。 MLPerf 推断 0 。 7 是行业标准 AI 基准测试的最新版本,它解决了这三个趋势,为开发人员和组织提供了有用的数据,以便为数据中心和边缘的平台选择提供信息。
基准测试扩展了推荐系统、语音识别和医学成像系统。它已经升级了自然语言处理( NLP )的工作负载,以进一步挑战测试中的系统。下表显示了当前的一组测试。

表 1 。 MLPerf 推断 0 。 7 工作负载。
*新工作量
此外,针对数据中心和边缘的多个场景进行了基准测试:
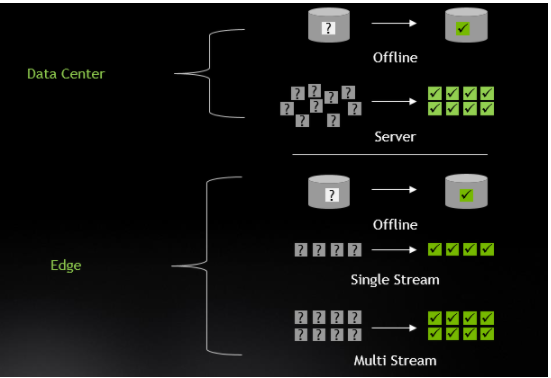
图 1 。 MLPerf 推理 0 。 7 平台类别和场景。
NVIDIA 轻松赢得了数据中心和边缘类别的所有测试和场景。虽然这种出色的性能大部分可以追溯到我们的 GPU 体系结构,但更多的是与我们的工程师所做的出色的优化工作有关,现在开发人员社区可以使用这些工作。
在这篇文章中,我深入研究了导致这些优秀结果的因素,包括软件优化以提高执行效率,多实例 GPU ( MIG )使一个 A100GPU 最多可以作为七个独立的 GPUs 运行,以及 Triton 推断服务器 支持在数据中心规模轻松部署推理应用程序。
检查的优化
NVIDIA GPUs 支持 int8 和 FP16 的高吞吐量精确推断,因此您可以在默认情况下获得出色的推断性能,而无需任何量化工作。然而,在保持精度的同时将网络量化到 int8 精度是最高的性能选项,可以使数学吞吐量提高 2 倍。
在本次提交的资料中,我们发现 FP16 需要满足 BERT 的最高精度目标。对于这个工作负载,我们使用了我们的 FP16 张量核心。在其他工作负载中,我们使用 int8 精度达到了最高精度目标( DLRM 和 3D Unet 的 FP32 的 99 。 9% 以上)。此外, int8 提交的性能得益于 TensorRT 7 。 2 软件版本中的全面加速。
许多推断工作负载需要大量的预处理工作。 NVIDIA 开源 DALI 库旨在加速对 GPU 的预处理并避免 CPU 瓶颈。在本文中,我们使用 DALI 实现了 RNN-T 基准的 wav 到 mel 的转换。
NLP 推断对具有特定序列长度(输入中的单词数)的输入文本进行操作。对于批处理推理,一种方法是将所有输入填充到相同的序列长度。但是,这会增加计算开销。 TensorRT 7 。 2 增加了三个插件来支持 NLP 的可变序列长度处理。我们提交的 BERT 使用这些插件获得了超过 35% 的端到端性能。
加速稀疏矩阵处理是 A100 中引入的一种新功能。稀疏化网络确实需要重新训练和重新校准权值才能正常工作,因此稀疏性在封闭类别中不是可用的优化,但在开放类别中是允许的。我们的开放类别 BERT 提交使用稀疏性实现了 21% 的吞吐量提高,同时保持了与封闭提交相同的准确性。
了解 MLPerf 中的 MIG
MIG 内存。 MIG 允许您选择是将 A100 作为单个大的 GPU 操作,还是将多个较小的 GPU 作为一个单独的大型 GPU 来运行,每个小的 GPU 可以在它们之间隔离的情况下为不同的工作负载提供服务。图 2 显示了将此技术用于测试的 MLPerf 结果。

图 2 。 MIG 与完整 T4 相比的推理性能。
图 2 比较了单个 MIG 实例与完整的 T4GPU 实例的边缘脱机性能,因为 A100 最多可支持七个 MIG 实例。您可以看到,超过四个 MIG 测试结果得分高于完整的 T4GPU 。这对应用程序意味着,您可以加载一个包含多个网络和应用程序的单个 A100 ,并以与 T4 相同或更好的性能运行每个网络和应用程序。这样可以减少部署的服务器数量,释放机架空间,并降低能耗。此外,在单个 A100 上同时运行多个网络有助于保持 GPU 的高利用率,因此基础设施管理人员可以优化使用已部署的计算资源。
Triton 推断服务器
在一个网络经过训练和优化之后,它就可以部署了,但这并不像打开交换机那么简单。在一个以人工智能为动力的服务上线之前,有几个挑战需要解决。这包括提供适当数量的服务器来维护 sla ,并确保在 AI 基础设施上运行的所有服务都有良好的用户体验。然而,“正确的数字”可能会随着时间的推移或由于工作量需求的突然变化而改变。理想的解决方案还可以实现负载平衡,从而使基础设施得到最佳利用,但不会出现超额订阅。此外,一些管理者希望在单个 GPUs 上运行多个网络。 Triton 推断服务器解决了这些挑战和其他问题,使基础设施管理人员更容易部署和维护负责提供人工智能服务的服务器群。
在这一轮中,我们也使用 Triton 推理服务器提交了结果,这简化了人工智能模型在生产中的大规模部署。这个开源推理服务软件允许团队从任何框架( TensorFlow 、 TensorRT 、 PyTorch 、 ONNX 运行时或自定义框架)部署经过训练的 AI 模型。它们还可以从本地存储、 Google 云平台或 Amazon S3 部署在任何基于 GPU – 或 CPU 的基础设施(云、数据中心或边缘)上。
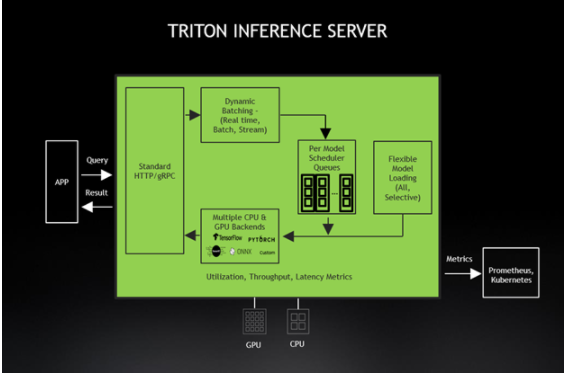
图 3 。 Triton 推断服务器与 Kubernetes 完全集成。
Triton ®声波风廓线仪也可作为 Docker 容器提供,是为基于微服务的应用而设计的。 Triton ®声波风廓线仪与 Kubernetes 紧密集成,实现动态负载平衡,保证所有网络推理操作顺利进行。 Triton ®声波风廓线仪的 GPU 指标帮助 Kubernetes 将推断工作转移到可用的 GPU 上,并在需要时扩展到数百个 GPUs 。新的 Triton ®声波风廓线仪 2 。 3 支持使用 KFServing 的无服务器推断、 Python 自定义后端、用于会话式人工智能的解耦推理、支持 A100MIG 以及 Azure ML 和 DeepStream 5 。 0 集成。
图 4 显示了 Triton ®声波风廓线仪与运行 A100 定制推理服务解决方案相比的总体效率,这两种配置都使用 TensorRT 运行。
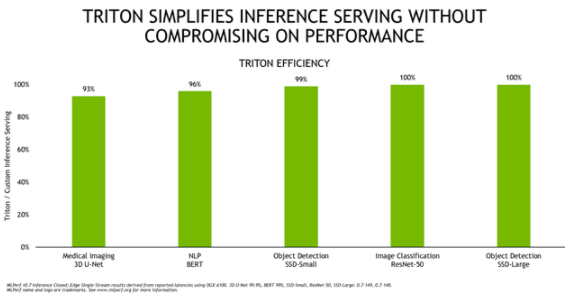
图 4 。 Triton ®声波风廓线仪在 MLPerf 推理 0 。 7 结果中提供了与高度定制的推理服务实现几乎相同的性能。
Triton ®声波风廓线仪的效率很高,在这五个网络中提供同等或接近它的性能。为了提供这样的性能,该团队对 Triton ®声波风廓线仪进行了许多优化,例如用于与应用程序进行低延迟通信的新的轻量级数据结构、用于改进动态批处理的批处理数据加载以及用于 TensorRT 后端的 CUDA 图形以获得更高的推理性能。这些增强功能可作为 20 。 09 Triton ®声波风廓线仪集装箱 的一部分提供给每个应用程序。除此之外, Triton ®声波风廓线仪还简化了部署,无论是在本地还是在云端。这使得所有网络推断都能顺利进行,即使在意外的需求高峰来袭时也是如此。
加速推理应用程序
考虑到驱动人工智能推理的持续趋势, NVIDIA 推理平台和全栈方法提供了最佳性能、最高通用性和最佳可编程性, MLPerf 推理 0 。 7 测试性能证明了这一点。现在,您和开发人员社区的其他成员都可以使用这些成果,主要是以开源软件的形式。此外, TensorRT 和 Triton 推理服务器可从 NVIDIA NGC 免费获得,以及预训练模型、深度学习框架、行业应用框架和头盔图。 A100GPU 已经证明了其充分的推理能力。随着完整的 NVIDIA 推理平台, A100GPU 已经准备好迎接最严峻的人工智能挑战。
关于作者
Dave Salvator 是 NVIDIA 旗下 Tesla 集团的高级产品营销经理,专注于超规模、深度学习和推理。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
5682浏览量
110100 -
人工智能
+关注
关注
1819文章
50290浏览量
266834
发布评论请先 登录
Vibe Coding AI全栈开发实战
曙光云AI全栈平台解锁政企AI新效能
是德科技推出全新AI推理仿真平台

NVIDIA DGX Spark为自主智能体提供全栈平台
NVIDIA DGX SuperPOD为Rubin平台横向扩展提供蓝图
NVIDIA BlueField-4数据处理器重塑新型AI原生存储基础设施
通过NVIDIA Jetson AGX Thor实现7倍生成式AI性能
NVIDIA TensorRT LLM 1.0推理框架正式上线
NVIDIA Nemotron Nano 2推理模型发布

自动驾驶中常提的“全栈”是个啥?有必要“全栈”吗?



评论