 NVIDIA Triton推理服务器简化人工智能推理
NVIDIA Triton推理服务器简化人工智能推理
人工智能的快速发展正在推高数据集的规模,以及网络的规模和复杂性。支持人工智能的应用程序,如电子商务产品推荐、基于语音的助手和呼叫中心自动化,需要数十到数百个经过培训的人工智能模型。推理服务帮助基础设施管理人员部署、管理和扩展这些模型,并在生产中保证实时服务质量( QoS )。此外,基础架构经理希望提供和管理用于部署这些 AI 模型的正确计算基础架构,最大限度地利用计算资源,灵活地放大或缩小规模,以优化部署的运营成本。将人工智能投入生产既是一项推理服务,也是一项基础设施管理挑战。
NVIDIA 与谷歌云合作,将 CPU 和 GPU 通用推理服务平台 NVIDIA Triton Inference Server的功能与谷歌 Kubernetes 引擎( GKE )相结合,使企业更容易将人工智能投入生产。NVIDIA Triton Inference Server 是一个托管环境,用于在安全的谷歌基础设施中部署、扩展和管理容器化人工智能应用程序。
使用 NVIDIA Triton 推理服务器在谷歌云上的 CPU 和 GPU 上提供推理服务
在企业应用程序中操作 AI 模型带来了许多挑战——为在多个框架中培训的模型提供服务,处理不同类型的推理查询类型,并构建一个能够跨 CPU 和 GPU 等多个部署平台进行优化的服务解决方案。
Triton 推理服务器通过提供一个单一的标准化推理平台来解决这些挑战,该平台可以从任何基于 TensorFlow 、TensorRT、 PyTorch 、 ONNX 运行时、 OpenVINO 或自定义 C ++/ Python 框架的本地存储或谷歌云的托管存储在任何基于 GPU 或 CPU 的基础设施上部署经过培训的 AI 模型。
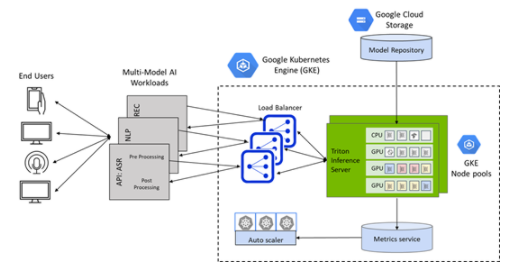
图 1 Triton 部署在 Google Kubernetes 引擎( GKE )上的推理服务器
在 GKE 集群上一键部署 NVIDIA Triton 推理服务器
Google Kubernetes Engine ( GKE )上的 Triton 为部署在 CPU 和 GPU 上的 AI 模型提供了通用推理服务平台,并结合了 Kubernetes 群集管理、负载平衡和基于需求的自动缩放计算的方便性。
使用谷歌市场上新的一键式 Triton GKE 推理服务器应用程序,可以将 Triton 无缝部署为 Google Kubernetes Engine ( GKE )管理的集群上的容器化微服务。
GKE 的 Triton 推理服务器应用程序是一个 helm chart 部署程序,可自动安装和配置 Triton ,以便在具有 NVIDIA GPU 节点池的 GKE 集群上使用,包括 NVIDIA A100 Tensor Core GPU s 和 NVIDIA T4 Tensor Core GPU s ,并利用谷歌云上的 Istio 进行流量进入和负载平衡。它还包括一个水平 pod autoscaler ( HPA ),它依赖堆栈驱动程序自定义度量适配器来监控 GPU 占空比,并根据推理查询和 SLA 要求自动缩放 GKE 集群中的 GPU 节点。
关于作者
Uttara Kumar 是 NVIDIA 的高级产品营销经理,专注于 GPU - 云计算中的人工智能加速应用。她非常关心让每个人都能获得技术的民主化,让开发者能够利用 NVIDIA 数据中心平台的力量来加快创新步伐。在 NVIDIA 之前,她领导半导体和科学计算软件公司的软件产品营销。她拥有安娜堡密歇根大学的 Eel CTR 工程硕士学位。
审核编辑:郭婷
-
cpu
+关注
关注
68文章
10850浏览量
211515 -
服务器
+关注
关注
12文章
9097浏览量
85309 -
人工智能
+关注
关注
1791文章
47137浏览量
238113
发布评论请先 登录
相关推荐
嵌入式和人工智能究竟是什么关系?
什么是AI服务器?AI服务器的优势是什么?
AMD助力HyperAccel开发全新AI推理服务器






 工商网监
工商网监
评论