 采用预训练的动作识别模型快速跟踪AI应用程序的开发
采用预训练的动作识别模型快速跟踪AI应用程序的开发
作为人类,我们每天都在不停地移动,做一些动作,比如走路、跑步和坐着。这些行为是我们日常生活的自然延伸。构建能够捕获这些特定动作的应用程序在体育分析领域、医疗保健领域、零售领域以及其他领域都非常有价值。
然而,构建和部署能够理解人类行为的时间信息的人工智能应用程序既具有挑战性又耗时,需要大量培训和深入的人工智能专业知识。
在这篇文章中,我们将展示如何快速跟踪 AI 应用程序的开发,方法是采用预训练的动作识别模型,使用 NVIDIA TAO Toolkit 自定义数据和类对其进行微调,并通过 NVIDIA DeepStream 部署它进行推理,而无需任何 AI 专业知识。
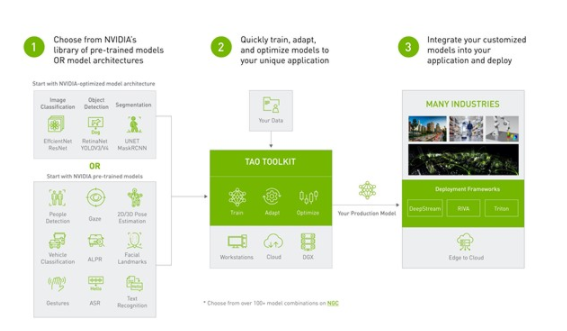
图 1 端到端工作流从预训练模型开始,使用 TAO 工具包进行微调,并使用 DeepStream 进行部署
动作识别模型
要识别一个动作,网络不仅要查看单个静态帧,还要查看多个连续帧。这提供了理解操作的时间上下文。这是与分类或目标检测模型相比的额外时间维度,其中网络仅查看单个静态帧。
这些模型是使用二维卷积神经网络创建的,其中的尺寸是宽度、高度和通道数。 2D 动作识别模型与其他 2D 计算机视觉模型类似,但通道维度现在也包含时间信息。
在 2D 动作识别模型中,将时间帧 D 与通道计数 C 相乘,形成通道维度输入。
对于三维模型,添加了表示时间信息的新维度 D 。
2D 和 3D 卷积网络的输出进入一个完全连接的层,然后是一个 Softmax 层来预测动作。
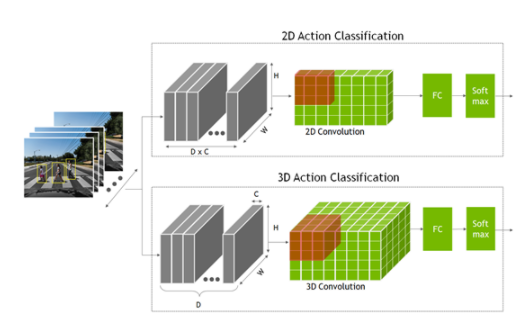
图 2 动作识别 2D 和 3D 卷积网络
pretrained model 是在代表性数据集上经过训练并使用权重和偏差进行微调的数据集。 NGC catalog 提供的动作识别模型已在五个常见类别上进行了培训:
行走
跑步
推
骑自行车
坠落
这是一个示例模型。更重要的是,该模型可以很容易地用自定义数据重新训练,只需花费很少的时间和从头开始训练所需的数据。
预训练模型是在 HMDB51 数据集中的几百个短视频剪辑上训练的。对于模型培训的五个类, 2D 模型的精度达到 83% , 3D 模型的精度达到 86% 。此外,如果选择按原样部署模型,下表显示了各种 GPU 上的预期性能。

在本实验中,您将使用三个新类对模型进行微调,这些新类包含简单动作,如俯卧撑、仰卧起坐和引体向上。您使用 HMDB51 数据集的子集,其中包含 51 个不同的操作。
先决条件
开始之前,您必须拥有以下培训和部署资源:
NVIDIA GPU 驱动程序版本:》 470
NVIDIA Docker:2.5.0-1
云中或本地的 NVIDIA GPU :
英伟达 A100
英伟达 V100
英伟达 T4
英伟达 RTX 30×0
工具包 NVIDIA:3.0-21-11
NVIDIA DeepStream:6.0
有关更多信息,请参阅 TAO 工具包快速入门指南 。
使用 TAO 工具包进行培训、调整和优化
在本节中,您将使用 TAO 工具包使用新类对模型进行微调。
TAO 工具包使用 transfer learning ,其中使用从现有神经网络模型学习的特征,并将其应用于新的神经网络模型。 TAO 工具包是 NVIDIA TAO 框架 基于 CLI 和 Jupyter 笔记本的解决方案,它抽象了 AI / DL 框架的复杂性,使您能够在没有任何 AI 专业知识的情况下为您的用例创建定制和生产就绪的模型。
您可以在 CLI 窗口中提供简单指令,也可以使用交钥匙 Jupyter 笔记本进行培训和微调。您可以使用 NGC 中的动作识别笔记本来训练自定义的三类模型。
下载 TAO Toolkit 计算机视觉示例工作流 的 1.3 版并解压缩包。在/action_recognition_net目录中,找到用于动作识别培训的 Jupyter 笔记本(actionrecognitionnet.ipynb),以及/specs目录,其中包含用于培训、评估和模型导出的所有规范文件。您可以为培训配置这些等级库文件。
启动 Jupyter 笔记本并打开action_recognition_net/actionrecognitionnet.ipynb文件:
jupyter notebook --ip 0.0.0.0 --port 8888 --allow-root
步骤 1 :设置并安装 TAO 工具包
所有培训步骤都在 Jupyter 笔记本中运行。启动笔记本后,运行笔记本中提供的设置环境变量和映射驱动器和安装 TAO 发射器步骤。
步骤 2 :下载数据集和预训练模型
安装 TAO 后,下一步是下载并准备数据集进行培训。 Jupyter 笔记本提供了下载和预处理 HMDB51 数据集的步骤。如果您有自己的自定义数据集,则可以在步骤 2.1 中使用它。
对于本文,您将使用 HMDB51 数据集中的三个类。修改几行以添加俯卧撑、引体向上和仰卧起坐课程。
$ wget -P $HOST_DATA_DIR http://serre-lab.clps.brown.edu/wp-content/uploads/2013/10/hmdb51_org.rar $ mkdir -p $HOST_DATA_DIR/videos && unrar x $HOST_DATA_DIR/hmdb51_org.rar $HOST_DATA_DIR/videos $ mkdir -p $HOST_DATA_DIR/raw_data $ unrar x $HOST_DATA_DIR/videos/pushup.rar $HOST_DATA_DIR/raw_data $ unrar x $HOST_DATA_DIR/videos/pullup.rar $HOST_DATA_DIR/raw_data $ unrar x $HOST_DATA_DIR/videos/situp.rar $HOST_DATA_DIR/raw_data
每个类的视频文件存储在$HOST_DATA_DIR/raw_data下各自的目录中。这些是经过编码的视频文件,必须解压缩为帧才能训练模型。已经提供了一个脚本来帮助您为培训准备数据。
下载帮助程序脚本并安装依赖项:
$ git clone https://github.com/NVIDIA-AI-IOT/tao_toolkit_recipes.git $ pip3 install xmltodict opencv-python
将视频文件解压缩为帧:
$ cd tao_recipes/tao_action_recognition/data_generation/ $ ./preprocess_HMDB_RGB.sh $HOST_DATA_DIR/raw_data \ $HOST_DATA_DIR/processed_data
下面的代码示例中显示了每个类的输出。f cnt: 82表示此视频剪辑已解压缩到 82 帧。对目录中的所有视频执行此操作。根据类的数量以及数据集和视频剪辑的大小,此过程可能需要一些时间。
Preprocess pullup f cnt: 82.0 f cnt: 82.0 f cnt: 82.0 f cnt: 71.0 ...
处理后的数据的格式类似于下面的代码示例。如果您正在对自己的数据进行培训,请确保数据集也遵循此目录格式。
$HOST_DATA_DIR/processed_data/ |-->|-->
下一步是将数据拆分为培训和验证集。 HMDB51 数据集为每个类提供了一个拆分文件,因此只需下载该文件,并将数据集划分为 70% 的培训和 30% 的验证。
$ wget -P $HOST_DATA_DIR http://serre-lab.clps.brown.edu/wp-content/uploads/2013/10/test_train_splits.rar $ mkdir -p $HOST_DATA_DIR/splits && unrar x \ $HOST_DATA_DIR/test_train_splits.rar $HOST_DATA_DIR/splits
使用助手脚本split_dataset.py拆分数据。这仅适用于 HMDB 数据集提供的拆分文件。如果您正在使用自己的数据集,那么这将不适用。
$ cd tao_recipes/tao_action_recognition/data_generation/ $ python3 ./split_dataset.py $HOST_DATA_DIR/processed_data \ $HOST_DATA_DIR/splits/testTrainMulti_7030_splits $HOST_DATA_DIR/train \ $HOST_DATA_DIR/test
用于培训的数据在$HOST_DATA_DIR/train下,用于测试和验证的数据在$HOST_DATA_DIR/test下。
准备好数据集后,从 NGC 下载预训练模型。按照 Jupyter 笔记本 2.1 中的步骤操作。
$ ngc registry model download-version "nvidia/tao/actionrecognitionnet:trainable_v1.0" --dest $HOST_RESULTS_DIR/pretrained
步骤 3 :配置培训参数
spec YAML 文件中提供了培训参数。在/ specs 目录中,查找所有用于培训、微调、评估、推断和导出的 spec 文件。对于培训,您可以使用train_rgb_3d_finetune.yaml。
对于本实验,我们将向您展示一些可以修改的超参数。有关所有不同参数的更多信息,请参阅ActionRecognitionNet。
您还可以在运行时覆盖任何参数。大多数参数保留为默认值。下面的代码块中突出显示了正在更改的少数代码。
## Model Configuration model_config: model_type: rgb input_type: "3d" backbone: resnet18 rgb_seq_length: 32 ## Change from 3 to 32 frame sequence rgb_pretrained_num_classes: 5 sample_strategy: consecutive sample_rate: 1 # Training Hyperparameter configuration train_config: optim: lr: 0.001 momentum: 0.9 weight_decay: 0.0001 lr_scheduler: MultiStep lr_steps: [5, 15, 25] lr_decay: 0.1 epochs: 20 ## Number of Epochs to train checkpoint_interval: 1 ## Saves model checkpoint interval ## Dataset configuration dataset_config: train_dataset_dir: /data/train ## Modify to use your train dataset val_dataset_dir: /data/test ## Modify to use your test dataset
第四步:训练你的人工智能模型
对于培训,请遵循 Jupyter 笔记本中的步骤 4 。设置环境变量。
训练动作识别的 TAO 工具包任务称为action_recognition。要进行培训,请使用tao action_recognition train命令。指定培训规范文件,并提供输出目录和预培训模型。或者,也可以在model_config规范中设置预训练模型。
$ tao action_recognition train \ -e $SPECS_DIR/train_rgb_3d_finetune.yaml \ -r $RESULTS_DIR/rgb_3d_ptm \ -k $KEY \ model_config.rgb_pretrained_model_path=$RESULTS_DIR/pretrained/actionrecognitionnet_vtrainable_v1.0/resnet18_3d_rgb_hmdb5_32.tlt ognition train \
根据您的 GPU 、序列长度或年代,这可能需要几分钟到几小时的时间。因为要保存每个历元,所以可以看到与历元数量相同的模型检查点。
模型检查点另存为ar_model_epoch=。选择模型评估和导出的最后一个历元,但可以使用验证损失最小的历元。
步骤 5 :评估经过培训的模型
有两种不同的抽样策略来评估视频剪辑上的训练模型:
- Center mode:拾取序列的中间帧进行推断。例如,如果模型需要 32 帧作为输入,而视频剪辑有 128 帧,则可以从索引 48 到索引 79 中选择帧进行推断。
- Conv mode:对单个视频中的 10 个序列进行卷积采样并进行推断。结果取平均值。
对于评估,请使用/specs目录中提供的评估规范文件(evaluate_rgb.yaml)。这就像训练配置。修改dataset_config参数以使用您正在培训的三个类。
dataset_config: ## Label maps for new classes. Modify this for your custom classes label_map: pushup: 0 pullup: 1 situp: 2
使用tao action_recognition evaluate命令进行计算。如前所述,对于video_eval_mode,您可以在中心模式或 conv 模式之间进行选择。使用训练运行中最后保存的模型检查点。
$ tao action_recognition evaluate \ -e $SPECS_DIR/evaluate_rgb.yaml \ -k $KEY \ model=$RESULTS_DIR/rgb_3d_ptm/ar_model_epoch=-val_loss= .tlt \ batch_size=1 \ test_dataset_dir=$DATA_DIR/test \ video_eval_mode=center
评价产出:
100%|███████████████████████████████████████████| 90/90 [00:03<00:00, 29.82it/s] ******************************* pushup 56.67 pullup 100.0 situp 90.0 ******************************* Total accuracy: 82.222 Average class accuracy: 82.222 2021-11-17 17:46:52,590 [INFO] tlt.components.docker_handler.docker_handler: Stopping container.
这是在 90 个视频数据集上评估的,该数据集包含所有三个动作的剪辑。总体准确率约为 82% ,这对于数据集的大小来说是合适的。数据集越大,模型的通用性越好。您可以尝试使用自己的剪辑测试准确性。
步骤 6 :导出以进行 DeepStream 部署
最后一步是导出用于部署的模型。要导出,请运行tao action_recognition export命令。您必须提供导出规范文件,该文件作为export_rgb.yaml包含在/specs目录中。修改export_rgb.yaml中的dataset_config值,以使用您培训的三个类。这类似于evaluate_rgb.yaml中的dataset_config。
$ tao action_recognition export \ -e $SPECS_DIR/export_rgb.yaml \ -k $KEY \ model=$RESULTS_DIR/rgb_3d_ptm/ar_model_epoch=-val_loss= .tlt \ /export/rgb_resnet18_3.etlt
祝贺您,您已成功培训了自定义 3D 动作识别模型。现在,使用 DeepStream 部署此模型。
使用 DeepStream 部署
在本节中,我们将展示如何使用 NVIDIA DeepStream 部署经过微调的模型。
DeepStream SDK帮助您快速构建高效、高性能的视频 AI 应用程序。 DeepStream 应用程序可以在由 NVIDIA Jetson 提供动力的边缘设备、本地服务器或云中运行。
为了支持动作识别模型, DeepStream 6.0 添加了Gst-nvdspreprocess插件。该插件加载一个自定义库( custom _ sequence _ preprocess.so ),以执行时间序列捕获和感兴趣区域( ROI )部分批处理,然后将批处理的张量缓冲区转发给下游推理插件。
您可以修改 DeepStream SDK 中包含的deepstream-3d-action-recognition应用程序,以测试使用 TAO 微调的模型。
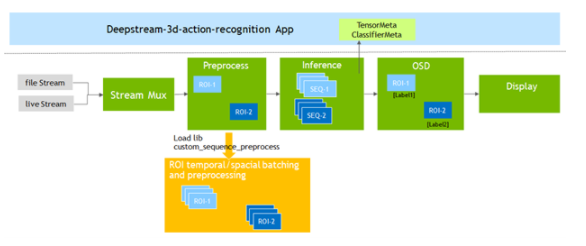 图 4 。三维动作识别应用程序管道
图 4 。三维动作识别应用程序管道示例应用程序同时对四个视频文件运行推断,并以 2 × 2 平铺显示结果。
在进行修改之前,先运行标准应用程序。首先,启动 DeepStream 6.0 开发容器:
$ xhost + $ docker run --gpus '"'device=0'"' -it -v /tmp/.X11-unix:/tmp/.X11-unix -e DISPLAY=$DISPLAY -w /opt/nvidia/deepstream/deepstream-6.0 nvcr.io/nvidia/deepstream:6.0-devel
有关 NVIDIA 提供的 DeepStream 集装箱的更多信息,请参阅NGC catalog。
在容器中,导航到 3D 动作识别应用程序目录,从 NGC 下载并安装标准 3D 和 2D 模型。
$ cd sources/apps/sample_apps/deepstream-3d-action-recognition/ $ wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/tao/actionrecognitionnet/versions/deployable_v1.0/zip -O actionrecognitionnet_deployable_v1.0.zip $ unzip actionrecognitionnet_deployable_v1.0.zip
现在,您可以使用 3D 推理模型执行应用程序并查看结果。
$ deepstream-3d-action-recognition -c deepstream_action_recognition_config.txt
预处理器插件配置
在修改应用程序之前,请熟悉运行应用程序所需的预处理器插件的关键配置参数。
从/app/sample_apps/deepstream-3d-action-recognition文件夹中,打开config_preprocess_3d_custom.txt文件并查看三维模型的预处理器配置。
第 13 行定义了三维模型所需的 5 维输入形状:
network-input-shape = 4;3;32;224;224
对于此应用程序,您将使用四个输入,每个输入有一个 ROI :
- 您的批次号为 4 (#输入*每个输入的 ROI )。
- 您的输入是 RGB ,因此通道数为 3 。
- 序列长度为 32 ,输入分辨率为 224 × 224 ( HxW )。
第 18 行告诉预处理器库您正在使用自定义序列:
network-input-order = 2
第 51 行和第 52 行定义了如何将帧传递给推理机:
stride=1 subsample=0
-
subsample值为 0 意味着您按顺序将帧(第 1 帧、第 2 帧……)传递到推断步骤。 -
stride值为 1 表示序列之间存在单个帧的差异。例如:- 序列 A :帧 1 , 2 , 3 , 4 …
- 序列 B :帧 2 , 3 , 4 , 5 …
最后,第 55-60 行定义了输入和 ROI 的数量:
src-ids=0;1;2;3 process-on-roi=1 roi-params-src-0=0;0;1280;720 roi-params-src-1=0;0;1280;720 roi-params-src-2=0;0;1280;720 roi-params-src-3=0;0;1280;720
有关所有应用程序和预处理器参数的更多信息,请参阅 DeepStream 文档的Action Recognition部分。
运行新模型
现在,您可以修改应用程序配置并测试练习动作识别模型。
因为您使用的是 Docker 映像,所以在主机文件系统和容器之间传输文件的最佳方法是在启动容器以设置可共享位置时使用-v mount标志。例如,使用-v /home:/home将主机的/home目录装载到容器的/home目录。
将新模型、标签文件和文本视频复制到/app/sample_apps/deepstream-3d-action-recognitionfolder.
# back up the original labels file $ cp ./labels.txt ./labels_bk.txt $ cp /home/labels.txt ./ $ cp /home/Exercise_demo.mp4 ./ $ cp /home/rgb_resnet18_3d_exercises.etlt ./
打开deepstream_action_recognition_config.txt并将第 30 行更改为指向运动测试视频。
uri-list=file:////opt/nvidia/deepstream/deepstream-6.0/sources/apps/sample_apps/deepstream-3d-action-recognition/Exercise_demo.mp4
打开config_infer_primary_3d_action.txt并将第 63 行用于推断的模型和第 68 行的批次大小从 4 更改为 1 ,因为您将从四个输入更改为一个输入:
tlt-encoded-model=./rgb_resnet18_3d_exercises.etlt .. batch-size=1
最后,打开config_preprocess_3d_custom.txt。更改network-input-shape值以反映第 35 行上运动识别模型的单个输入和配置:
network-input-shape= 1;3;3;224;224
修改第 77 – 82 行中单个输入和 ROI 的源设置:
src-ids=0 process-on-roi=1 roi-params-src-0=0;0;1280;720 #roi-params-src-1=0;0;1280;720 #roi-params-src-2=0;0;1280;720 #roi-params-src-3=0;0;1280;720
现在可以使用以下命令测试新模型:
$ deepstream-3d-action-recognition -c deepstream_action_recognition_config.txt
应用程序源代码
动作识别示例应用程序使您能够灵活地更改输入源、输入数量和使用的模型,而无需修改应用程序源代码。
要查看应用程序是如何实现的,请参阅/sources/apps/sample_apps/deepstream-3d-action-recognition文件夹中的应用程序源代码以及预处理器插件使用的自定义序列库。
总结
在这篇文章中,我们分别使用TAO Toolkit和DeepStream向您展示了一个端到端的工作流程,用于微调和部署动作识别模型。 TAO 工具包和 DeepStream 都是抽象出 AI 框架复杂性的解决方案,使您能够在生产中构建和部署 AI 应用程序,而无需任何 AI 专业知识。
通过从NGC catalog下载模型,开始使用动作识别模型。
关于作者
Chintan Shah 是 NVIDIA 的产品经理,专注于智能视频分析解决方案的 AI 产品。他管理工具箱,用于有效的深度学习培训和实时推理。在他之前的工作中,他正在为 NVIDIA GPU 开发硬件 IP 。他拥有北卡罗来纳州立大学电气工程硕士学位。
Alvin Clark 是 DeepStream 的产品营销经理。阿尔文的职业生涯始于设计工程师,然后转向技术销售和市场营销。他曾与多个行业的客户合作,应用范围从卫星系统、外科机器人到深海潜水器。阿尔文持有圣地亚哥加利福尼亚大学的工程学学位,目前正在乔治亚理工大学攻读硕士学位。
Akhil Docca 是 NVIDIA NGC 的高级产品营销经理,专注于 HPC 和 DL 容器。 Akhil 拥有加州大学洛杉矶分校安德森商学院工商管理硕士学位,圣何塞州立大学机械工程学士学位。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
5087浏览量
103931 -
gpu
+关注
关注
28文章
4797浏览量
129509
发布评论请先 登录
相关推荐
【「基于大模型的RAG应用开发与优化」阅读体验】+大模型微调技术解读
GPU是如何训练AI大模型的
AI模型部署边缘设备的奇妙之旅:如何实现手写数字识别
AI大模型的训练数据来源分析
如何训练自己的AI大模型
直播预约 |数据智能系列讲座第4期:预训练的基础模型下的持续学习






 工商网监
工商网监
评论