 用NVIDIA迁移学习工具箱如何训练二维姿态估计模型
用NVIDIA迁移学习工具箱如何训练二维姿态估计模型
本系列的第一篇文章介绍了在 NVIDIA 迁移学习工具箱中使用开源 COCO 数据集和 BodyPoseNet 应用程序的 如何训练二维姿态估计模型 。
在本文中,您将学习如何在 NVIDIA 迁移学习工具箱中优化姿势估计模型。它将引导您完成模型修剪和 INT8 量化的步骤,以优化用于推理的模型。
模型优化和导出
本节介绍模型优化和导出的几个主题:
修剪
INT8 量化
提高速度和准确性的最佳实践
修剪
BodyPoseNet 支持模型修剪以删除不必要的连接,从而将参数数量减少一个数量级。这将产生一个优化的模型体系结构。
修剪模型
要修剪模型,请使用以下命令:
tlt bpnet prune -m $USER_EXPERIMENT_DIR/models/exp_m1_unpruned/bpnet_model.tlt \
-o $USER_EXPERIMENT_DIR/models/exp_m1_pruned/bpnet_model.pruned-0.05.tlt \
-eq union \
-pth 0.05 \
-k $KEY
通常,您只需调整-pth(阈值)以进行精度和模型大小的权衡。对于一些内部研究,我们注意到pth值介于[0 . 05 , 3 . 0]之间是 BodyPoseNet 模型的良好起点。
重新训练修剪模型
在模型被删减之后,由于一些以前有用的权值可能已经被删除,因此 MIG 的精度可能会略有下降。为了重新获得准确度,我们建议在相同的数据集上重新训练这个修剪过的模型。您可以按照列车试验配置文件部分中的相同说明进行操作。现在主要的更改是指定pretrained_weights作为修剪模型的路径,并启用load_graph。因为模型是用剪枝的模型权重初始化的,所以模型收敛得更快。
# Retraining using the pruned model as model graph tlt bpnet train -e $SPECS_DIR/bpnet_retrain_m1_coco.yaml \ -r $USER_EXPERIMENT_DIR/models/exp_m1_retrain \ -k $KEY \ --gpus $NUM_GPUS
您可以按照Evaluation和模型验证部分中的类似说明来评估和验证修剪后的模型。在用pth 0.05重新训练修剪后的模型之后,您可以观察到多尺度推理的精度为 56 . 1% 的 AP 。以下是 COCO 验证集的指标:
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.561
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.776
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.609
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.567
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.556
...
导出. etlt 模型
推理吞吐量和创建有效模型的速度是部署深度学习应用程序的两个关键指标,因为它们直接影响到上市时间和部署成本。 TLT 包含一个 export 命令,用于导出和准备 TLT 模型以进行部署。
模型将导出为. etlt (加密的 TLT )文件。 TLT CV 推断可以使用该文件,它解密模型并将其转换为 TensorRT 引擎。导出模型将训练过程与推理分离,并允许转换到 TLT 环境之外的 TensorRT 引擎 TensorRT 引擎特定于每个硬件配置,应该为每个独特的推理环境生成。下面的代码示例显示了经过修剪、重新训练的模型的导出。
tlt bpnet export -m $USER_EXPERIMENT_DIR/models/exp_m1_retrain/bpnet_model.tlt \
-e $SPECS_DIR/bpnet_retrain_m1_coco.yaml \
-o $USER_EXPERIMENT_DIR/models/exp_m1_final/bpnet_model.etlt \
-k $KEY \
-t tfonnx
export 命令可以选择生成校准缓存,以便以 INT8 精度运行推断。这将在后面的章节中详细描述。
INT8 量化
BodyPoseNet 模型支持 TensorRT 中的 int8 推理模式。为此,首先对模型进行校准,以运行 8 位推断。要校准模型,需要一个目录,其中包含用于校准的一组采样图像。
我们提供了一个助手脚本,可以解析注释并根据指定的标准(如图像中的人数、每人的关键点数量等)随机抽取所需数量的图像。
# Number of calibration samples to use
export NUM_CALIB_SAMPLES=2000
python3 sample_calibration_images.py \
-a $LOCAL_EXPERIMENT_DIR/data/annotations/person_keypoints_train2017.json \
-i $LOCAL_EXPERIMENT_DIR/data/train2017/ \
-o $LOCAL_EXPERIMENT_DIR/data/calibration_samples/ \
-n $NUM_CALIB_SAMPLES \
-pth 1 \
--randomize
生成 INT8 校准缓存和引擎
下面的命令将经过修剪、重新训练的模型导出为. etlt 格式,执行 INT8 校准,并为当前硬件生成 INT8 校准缓存和 TensorRT 引擎。
# Set dimensions of desired output model for inference/deployment
export IN_HEIGHT=288
export IN_WIDTH=384
export IN_CHANNELS=3
export INPUT_SHAPE=288x384x3
# Set input name
export INPUT_NAME=input_1:0
tlt bpnet export \
-m $USER_EXPERIMENT_DIR/models/exp_m1_retrain/bpnet_model.tlt \
-o $USER_EXPERIMENT_DIR/models/exp_m1_final/bpnet_model.etlt \
-k $KEY \
-d $IN_HEIGHT,$IN_WIDTH,$IN_CHANNELS \
-e $SPECS_DIR/bpnet_retrain_m1_coco.yaml \
-t tfonnx \
--data_type int8 \
--engine_file $USER_EXPERIMENT_DIR/models/exp_m1_final/bpnet_model.$IN_HEIGHT.$IN_WIDTH.int8.engine \
--cal_image_dir $USER_EXPERIMENT_DIR/data/calibration_samples/ \
--cal_cache_file $USER_EXPERIMENT_DIR/models/exp_m1_final/calibration.$IN_HEIGHT.$IN_WIDTH.bin \
--cal_data_file $USER_EXPERIMENT_DIR/models/exp_m1_final/coco.$IN_HEIGHT.$IN_WIDTH.tensorfile \
--batch_size 1 \
--batches $NUM_CALIB_SAMPLES \
--max_batch_size 1 \
--data_format channels_last
确保 --cal_image_dir 中提到的目录中至少有( batch_size * batches )个图像。要为当前硬件生成 F16 引擎,请将 --data_type 指定为 FP16 。有关此处使用的参数的更多信息,请参阅 INT8 模型概述 。
评估 TensorRT 发动机
此评估主要用于对导出的 TRT ( INT8 / FP16 )模型进行健全性检查。这并不能反映模型的真实准确性,因为这里的输入纵横比可能与验证集中图像的纵横比有很大差异。这套设备有一组不同分辨率的图像。在这里,您保留严格的输入分辨率,并填充图像以重新训练纵横比。因此,这里的精度 MIG ht 根据纵横比和您选择的网络分辨率而变化。
您也可以在严格模式下运行 .tlt 模型的评估,以便与 INT8 / FP16 / FP32 模型的精度进行比较,以确定精度是否下降。在这一步中,与 .tlt 型号相比, FP16 和 FP32 型号的精度应无下降或下降最小。 INT8 模型的精度与 .tlt 模型相似(或在 2-3%AP 范围内可比)。
您可以按照 Evaluation 和 模型验证 部分中的类似说明来评估和验证模型。一个改变就是你现在使用 $SPECS_DIR/infer_spec_retrained_strict.yaml as inference_spec 和要使用的模型将是经过修剪的 TLT 模型、 INT8 引擎或 FP16 引擎。
可部署模型导出
在验证了 INT8 / FP16 / FP32 模型之后,您必须重新导出该模型,以便它可以用于在 TLT-CV 推理等推理平台上运行。您使用的准则与前几节中相同,但必须将 --sdk_compatible_model 标志添加到 export 命令中,这将向模型中添加一些不可训练的后期处理层,以实现与推理管道的兼容性。重用前面步骤中生成的校准张量文件( cal_data_file )以保持一致,但必须重新生成 cal_cache_file 和 .etlt 模型。
tlt bpnet export
-m $USER_EXPERIMENT_DIR/models/exp_m1_retrain/bpnet_model.tlt
-o $USER_EXPERIMENT_DIR/models/exp_m1_final/bpnet_model.deploy.etlt
-k $KEY
-d $IN_HEIGHT,$IN_WIDTH,$IN_CHANNELS
-e $SPECS_DIR/bpnet_retrain_m1_coco.txt
-t tfonnx
--data_type int8
--cal_image_dir $USER_EXPERIMENT_DIR/data/calibration_samples/
--cal_cache_file $USER_EXPERIMENT_DIR/models/exp_m1_final/calibration.$IN_HEIGHT.$IN_WIDTH.deploy.bin
--cal_data_file $USER_EXPERIMENT_DIR/models/exp_m1_final/coco.$IN_HEIGHT.$IN_WIDTH.tensorfile
--batch_size 1
--batches $NUM_CALIB_SAMPLES
--max_batch_size 1
--data_format channels_last
--engine_file $USER_EXPERIMENT_DIR/models/exp_m1_final/bpnet_model.$IN_HEIGHT.$IN_WIDTH.int8.deploy.engine
--sdk_compatible_model
提高速度和准确性的最佳实践
在本节中,我们将介绍一些用于提高模型性能和准确性的最佳实践。
部署的网络输入分辨率
模型的网络输入分辨率是决定自底向上方法精度的主要因素之一。自下而上的方法必须一次提供整个图像,从而使每个人的分辨率更小。因此,更高的输入分辨率产生更好的精度,特别是在中小型人员的图像比例方面。但是,随着输入分辨率的提高, CNN 的运行时间也会提高。因此,准确度/运行时权衡应该由目标用例的准确度和运行时需求来决定。
如果您的应用程序涉及到一个或多个靠近相机的人的姿势估计,使得该人的比例相对较大,那么您可以使用较小的网络输入高度。如果你的目标是为相对规模较小的人使用网络,比如拥挤的场景,你需要更高的网络输入高度。冻结网络高度后,可以根据部署期间使用的输入数据的纵横比来决定宽度。
不同分辨率的精度/运行时变化说明
这些是笔记本中使用的默认体系结构和规范的近似运行时和精度。对架构或参数的任何更改都会产生不同的结果。这主要是为了更好地了解哪种解决方案适合您的需要。
从 224 英镑开始,预计 area=medium 类别的应付账款将增长 7-10% × 320 至 288 × 384 和额外的 7-10%AP 当你选择 320 × 448 。在这些分辨率中, area=large 的精度几乎保持不变,所以如果需要的话,可以选择较低的分辨率。根据 COCO 关键点评估 , medium 区域被定义为居住面积在 36 ^ 2 到 96 ^ 2 之间的人。居住面积在 36 ^ 2 到 96 ^ 2 之间的人被归类为 large 。
我们使用默认大小 288 × 384 在这个岗位上。要使用不同的分辨率,需要进行以下更改:
用所需形状更新 INT8 量化 中提到的 env 变量。
更新 infer_spec_retrained_strict.yaml 中的 input_shape ,这使您能够对导出的 TRT 模型进行健全性评估。默认设置为[288384]。
高度和宽度应为 8 的倍数,最好为 16 / 32 / 64 的倍数。
网络中的细化阶段数
图 1 显示了模型体系结构包括细化阶段,每个阶段细化前一阶段的结果。您可以使用 model 部分下的 stages 参数来配置它 stages 包括初始预测阶段和细化阶段。我们建议使用最少一个细化阶段,最多六个细化阶段,对应于[2 , 7]范围内的 stages 。
当您使用更多的细化阶段时,这可能有助于提高准确性,但请记住,这将导致推理时间的增加。在这篇文章中,我们使用了默认的两个细化阶段( stages=3 ),这是为了获得最佳的性能和准确性而进行的调整。要获得更快的性能,请使用 stages=2 。
修剪和正则化
修剪有助于显著减少参数数量,并在保持精度的同时最大限度地提高速度,或者以精度下降为代价。剪枝阈值越高,模型越小,推理速度越快,但 MIG ht 会导致精度下降。
要使用的阈值取决于数据集。如果再培训的准确性是好的,你可以增加这个值得到更小的模型。否则,请降低此值以获得更好的精度。我们建议使用 prune-retain 循环进行迭代,直到您满意精度和速度的折衷。在修剪之前训练模型时,也可以使用更高的 L1 正则化权重。它会将更多的权重推向零,从而更容易删减网络权重。
模型精度和性能
在本节中,我们将深入探讨模型的准确性和性能,并将其与最新技术和跨平台进行比较。
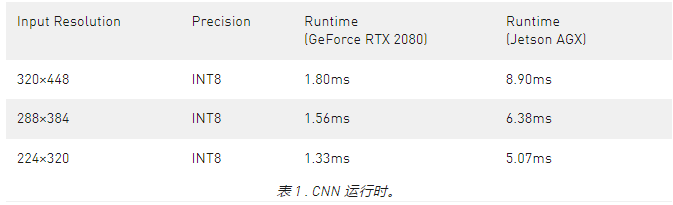
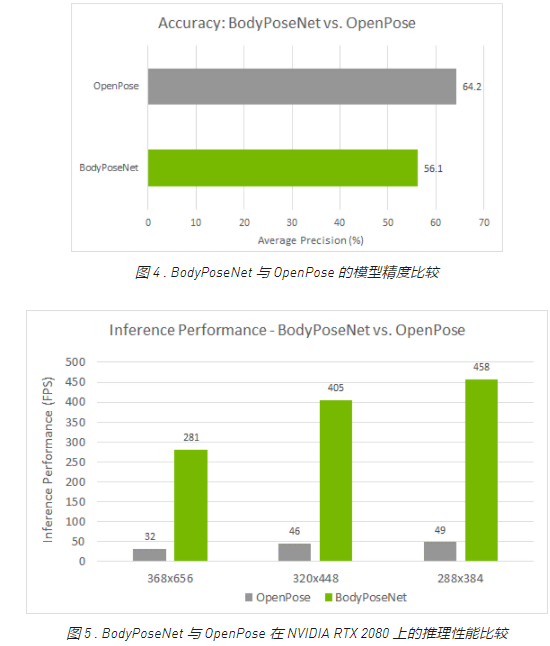
与 OpenPose 的比较
我们将此方法与 OpenPose 进行比较,因为此方法遵循类似的单次自底向上方法。图 4 显示,与 OpenPose 模型相比,您实现了更好的精度性能折衷。准确率较低约 8%AP ,而您实现了接近 9 倍的加速模型训练与默认参数在这篇文章中提供。
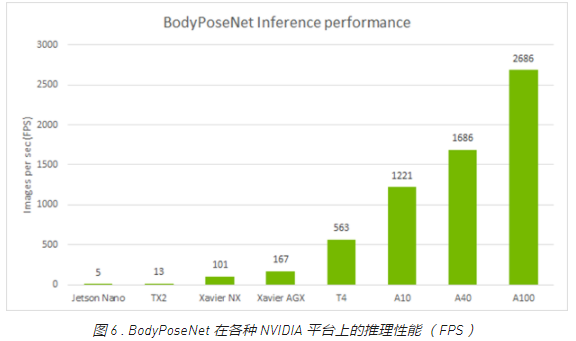
跨设备的独立性能
下表显示了使用默认参数使用 TLT 训练的 BodyPoseNet 模型的推理性能。我们使用 TensorRT 的 trtexec 命令分析了模型推理。
结论
在本文中,您学习了如何使用 TLT 中的 BodyPoseNet 应用程序优化身体姿势模型。文章展示了如何使用一个开源的 COCO 数据集和 NGC 的一个预训练主干来训练和优化一个 TLT 模型。有关模型部署的信息,请参阅 TLT CV 推断管道 快速启动脚本 和 Deployment 说明。
与 OpenPose 相比,使用此模型,您的推理性能可以提高 9 倍,甚至可以帮助您在嵌入式设备上实现实时性能。修剪加上 INT8 精度可以在边缘设备上提供最高的推理性能。
关于作者
Sakthivel Sivaraman 是 NVIDIA 的高级软件工程师,专注于开发深度学习和计算机视觉解决方案,并将其部署到边缘。在 2018 参加“ ZVK3]之前,他从宾夕法尼亚大学获得机器人学博士学位。他的研究兴趣包括计算机视觉、深度学习和机器人技术。
Rajath Shetty 是 NVIDIA 的工程经理,负责在汽车和医疗保健领域应用深度学习和计算机视觉的项目。他的兴趣涉及边缘计算、算法和人工智能应用软件栈。他拥有乔治亚理工学院的电子和计算机工程硕士学位。
Chintan Shah 是 NVIDIA 的产品经理,专注于智能视频分析解决方案的 AI 产品。他管理工具箱,用于有效的深度学习培训和实时推理。在他之前的工作中,他正在为 NVIDIA GPU 开发硬件 IP 。他拥有北卡罗来纳州立大学电气工程硕士学位。
Niral Pathak 是 NVIDIA 的软件工程师,致力于计算机视觉解决方案的部署。他拥有加州大学圣地亚哥分校电子和计算机工程硕士学位。他的兴趣包括计算机视觉、深度学习和机器人技术。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
5101浏览量
104322 -
计算机
+关注
关注
19文章
7572浏览量
89020 -
深度学习
+关注
关注
73文章
5526浏览量
121824
发布评论请先 登录
相关推荐
二维影像扫描引擎可以应用于哪些行业?

二维扫码头有效扫描距离是多少,影响二维扫描头扫码的因素有哪些

一维/二维条码识读器可以应用于哪些行业?

RS232接口的二维影像扫描引擎,广泛用在医疗设备上扫一维二维码

labview按行读取二维数组之后再按读取顺序重新组成二维数组如何实现?
二维扫描PDA用于仓库管理

llm模型训练一般用什么系统
预训练模型的基本原理和应用
如何使用MATLAB神经网络工具箱
matlab神经网络工具箱结果分析
MATLAB如何使用训练好的网络
技术|二维PDOA平面定位方案






 工商网监
工商网监
评论