 如何有效地从内核中访问设备的全局内存
如何有效地从内核中访问设备的全局内存
在前面的两文章中,我们研究了如何在主机和设备之间高效地移动数据。在我们的 CUDA C / C ++系列的第六篇文章中,我们将讨论如何有效地从内核中访问设备存储器,特别是全局内存。
在 CUDA 设备上有几种内存,每种内存的作用域、生存期和缓存行为都不同。到目前为止,在本系列中,我们已经使用了驻留在设备 DRAM 中的全局内存,用于主机和设备之间的传输,以及内核的数据输入和输出。这里的名称global是指作用域,因为它可以从主机和设备访问和修改。全局内存可以像下面代码片段的第一行那样使用__device__de Clara 说明符在全局(变量)范围内声明,或者使用cudaMalloc()动态分配并分配给一个常规的 C 指针变量,如第 7 行所示。全局内存分配可以在应用程序的生命周期内保持。根据设备的计算能力,全局内存可能被缓存在芯片上,也可能不在芯片上缓存。
__device__ int globalArray[256];
void foo()
{
...
int *myDeviceMemory = 0;
cudaError_t result = cudaMalloc(&myDeviceMemory, 256 * sizeof(int));
...
}在讨论全局内存访问性能之前,我们需要改进对 CUDA 执行模型的理解。我们已经讨论了如何将线程被分组为线程块分配给设备上的多处理器。在执行过程中,有一个更精细的线程分组到warps。 GPU 上的多处理器以 SIMD (单指令多数据)方式为每个扭曲执行指令。所有当前支持 CUDA – 的 GPUs 的翘曲尺寸(实际上是 SIMD 宽度)是 32 个线程。
全局内存合并
将线程分组为扭曲不仅与计算有关,而且与全局内存访问有关。设备coalesces全局内存加载并存储由一个 warp 线程发出的尽可能少的事务,以最小化 DRAM 带宽(在计算能力小于 2 . 0 的旧硬件上,事务合并在 16 个线程的一半扭曲内,而不是整个扭曲中)。为了弄清楚 CUDA 设备架构中发生聚结的条件,我们在三个 Tesla 卡上进行了一些简单的实验: a Tesla C870 (计算能力 1 . 0 )、 Tesla C1060 (计算能力 1 . 3 )和 Tesla C2050 (计算能力 2 . 0 )。
我们运行两个实验,使用如下代码(GitHub 上也有)中所示的增量内核的变体,一个具有数组偏移量,这可能导致对输入数组的未对齐访问,另一个是对输入数组的跨步访问。
#include #include // Convenience function for checking CUDA runtime API results // can be wrapped around any runtime API call. No-op in release builds. inline cudaError_t checkCuda(cudaError_t result) { #if defined(DEBUG) || defined(_DEBUG) if (result != cudaSuccess) { fprintf(stderr, "CUDA Runtime Error: %sn", cudaGetErrorString(result)); assert(result == cudaSuccess); } #endif return result; } template __global__ void offset(T* a, int s) { int i = blockDim.x * blockIdx.x + threadIdx.x + s; a[i] = a[i] + 1; } template __global__ void stride(T* a, int s) { int i = (blockDim.x * blockIdx.x + threadIdx.x) * s; a[i] = a[i] + 1; } template void runTest(int deviceId, int nMB) { int blockSize = 256; float ms; T *d_a; cudaEvent_t startEvent, stopEvent; int n = nMB*1024*1024/sizeof(T); // NB: d_a(33*nMB) for stride case checkCuda( cudaMalloc(&d_a, n * 33 * sizeof(T)) ); checkCuda( cudaEventCreate(&startEvent) ); checkCuda( cudaEventCreate(&stopEvent) ); printf("Offset, Bandwidth (GB/s):n"); offset<<>>(d_a, 0); // warm up for (int i = 0; i <= 32; i++) { checkCuda( cudaMemset(d_a, 0.0, n * sizeof(T)) ); checkCuda( cudaEventRecord(startEvent,0) ); offset<<>>(d_a, i); checkCuda( cudaEventRecord(stopEvent,0) ); checkCuda( cudaEventSynchronize(stopEvent) ); checkCuda( cudaEventElapsedTime(&ms, startEvent, stopEvent) ); printf("%d, %fn", i, 2*nMB/ms); } printf("n"); printf("Stride, Bandwidth (GB/s):n"); stride<<>>(d_a, 1); // warm up for (int i = 1; i <= 32; i++) { checkCuda( cudaMemset(d_a, 0.0, n * sizeof(T)) ); checkCuda( cudaEventRecord(startEvent,0) ); stride<<>>(d_a, i); checkCuda( cudaEventRecord(stopEvent,0) ); checkCuda( cudaEventSynchronize(stopEvent) ); checkCuda( cudaEventElapsedTime(&ms, startEvent, stopEvent) ); printf("%d, %fn", i, 2*nMB/ms); } checkCuda( cudaEventDestroy(startEvent) ); checkCuda( cudaEventDestroy(stopEvent) ); cudaFree(d_a); } int main(int argc, char **argv) { int nMB = 4; int deviceId = 0; bool bFp64 = false; for (int i = 1; i < argc; i++) { if (!strncmp(argv[i], "dev=", 4)) deviceId = atoi((char*)(&argv[i][4])); else if (!strcmp(argv[i], "fp64")) bFp64 = true; } cudaDeviceProp prop; checkCuda( cudaSetDevice(deviceId) ) ; checkCuda( cudaGetDeviceProperties(&prop, deviceId) ); printf("Device: %sn", prop.name); printf("Transfer size (MB): %dn", nMB); printf("%s Precisionn", bFp64 ? "Double" : "Single"); if (bFp64) runTest(deviceId, nMB); else runTest(deviceId, nMB);
}此代码可以通过传递“ fp64 ”命令行选项以单精度(默认值)或双精度运行偏移量内核和跨步内核。每个内核接受两个参数,一个输入数组和一个表示访问数组元素的偏移量或步长的整数。内核在一系列偏移和跨距的循环中被称为。
未对齐的数据访问
下图显示了 Tesla C870 、 C1060 和 C2050 上的偏移内核的结果。
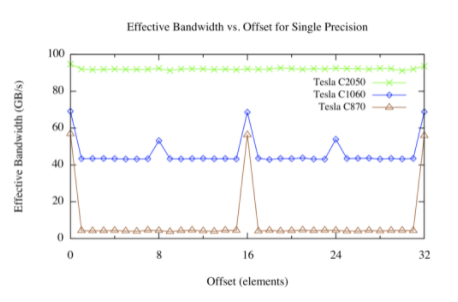
设备内存中分配的数组由 CUDA 驱动程序与 256 字节内存段对齐。该设备可以通过 32 字节、 64 字节或 128 字节的事务来访问全局内存。对于 C870 或计算能力为 1 . 0 的任何其他设备,半线程的任何未对齐访问(或半扭曲线程不按顺序访问内存的对齐访问)将导致 16 个独立的 32 字节事务。由于每个 32 字节事务只请求 4 个字节,因此可以预期有效带宽将减少 8 倍,这与上图(棕色线)中看到的偏移量(不是 16 个元素的倍数)大致相同,对应于线程的一半扭曲。
对于计算能力为 1 . 2 或 1 . 3 的 Tesla C1060 或其他设备,未对准访问的问题较少。基本上,通过半个线程对连续数据的未对齐访问在几个“覆盖”请求的数据的事务中提供服务。由于未请求的数据正在传输,以及不同的半翘曲所请求的数据有些重叠,因此相对于对齐的情况仍然存在性能损失,但是这种损失远远小于 C870 。
计算能力为 2 . 0 的设备,如 Tesla C250 ,在每个多处理器中都有一个 L1 缓存,其行大小为 128 字节。该设备将线程的访问合并到尽可能少的缓存线中,从而导致对齐对跨线程顺序内存访问吞吐量的影响可以忽略不计。
快速内存访问
步幅内核的结果如下图所示。
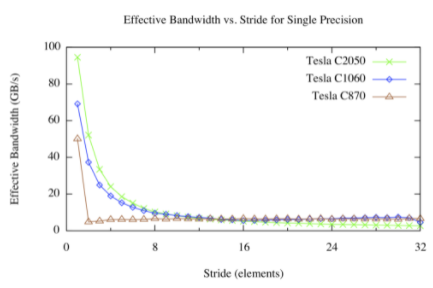
对于快速的全局内存访问,我们有不同的看法。对于大步进,无论架构版本如何,有效带宽都很差。这并不奇怪:当并发线程同时访问物理内存中相距很远的内存地址时,硬件就没有机会合并这些访问。从上图中可以看出,在 Tesla C870 上,除 1 以外的任何步幅都会导致有效带宽大幅降低。这是因为 compute capability 1 . 0 和 1 . 1 硬件需要跨线程进行线性、对齐的访问以进行合并,因此我们在 offset 内核中看到了熟悉的 1 / 8 带宽。 Compute capability 1 . 2 及更高版本的硬件可以将访问合并为对齐的段( CC 1 . 2 / 1 . 3 上为 32 、 64 或 128 字节段,在 CC 2 . 0 及更高版本上为 128 字节缓存线),因此该硬件可以产生平滑的带宽曲线。
当访问多维数组时,线程通常需要索引数组的更高维,因此快速访问是不可避免的。我们可以使用一种名为共享内存的 CUDA 内存来处理这些情况。共享内存是一个线程块中所有线程共享的片上内存。共享内存的一个用途是将多维数组的 2D 块以合并的方式从全局内存提取到共享内存中,然后让连续的线程跨过共享内存块。与全局内存不同,对共享内存的快速访问没有惩罚。我们将在下一篇文章中详细介绍共享内存。
概括
在这篇文章中,我们讨论了如何从 CUDA 内核代码中有效地访问全局内存的一些方面。设备上的全局内存访问与主机上的数据访问具有相同的性能特征,即数据局部性非常重要。在早期的 CUDA 硬件中,内存访问对齐和跨线程的局部性一样重要,但在最近的硬件上,对齐并不是什么大问题。另一方面,快速的内存访问会损害性能,使用片上共享内存可以减轻这种影响。在下一篇文章中,我们将详细探讨共享内存,之后的文章中,我们将展示如何使用共享内存来避免在矩阵转置过程中出现跨步全局内存访问。
关于作者
Mark Harris 是 NVIDIA 杰出的工程师,致力于 RAPIDS 。 Mark 拥有超过 20 年的 GPUs 软件开发经验,从图形和游戏到基于物理的模拟,到并行算法和高性能计算。当他还是北卡罗来纳大学的博士生时,他意识到了一种新生的趋势,并为此创造了一个名字: GPGPU (图形处理单元上的通用计算)。
审核编辑:郭婷
-
存储器
+关注
关注
38文章
7552浏览量
164842 -
NVIDIA
+关注
关注
14文章
5104浏览量
104387
发布评论请先 登录
相关推荐

如何有效地提高传感器的测试精度
如何有效地安装孔隙水压力计

如何使用内存加速存储访问速度
嵌入式工程师都在找的【Linux内核调试技术】建议收藏!
内存管理的硬件结构

FPGA开发过程中配置全局时钟需要注意哪些问题
使用 PREEMPT_RT 在 Ubuntu 中构建实时 Linux 内核

什么是HBM3E内存?Rambus HBM3E/3内存控制器内核





 工商网监
工商网监
评论