 用于实例分割的Mask R-CNN框架
用于实例分割的Mask R-CNN框架
一、介绍
我们的方法称为 Mask R-CNN,扩展了 Faster RCNN ,方法是在每个感兴趣区域 (RoI) 上添加一个用于预测分割掩码的分支,与用于分类和边界框回归的现有分支并行(图 1)。掩码分支是应用于每个 RoI 的小型 FCN,以像素到像素的方式预测分割掩码。鉴于 Faster R-CNN 框架,Mask R-CNN 易于实现和训练,这有助于广泛的灵活架构设计。此外,掩码分支仅增加了少量计算开销,从而实现了快速系统和快速实验。原则上,Mask R-CNN 是 Faster R-CNN 的直观扩展,但正确构建 mask 分支对于获得良好结果至关重要。最重要的是,Faster R-CNN 并不是为网络输入和输出之间的像素到像素对齐而设计的。这在 RoIPool(处理实例的事实上的核心操作)如何为特征提取执行粗略空间量化时最为明显。为了解决错位问题,我们提出了一个简单的、无量化的层,称为 RoIAlign,它忠实地保留了精确的空间位置。尽管是一个看似很小的变化,但 RoIAlign 具有很大的影响:它将掩模准确度提高了 10% 到 50%,在更严格的定位指标下显示出更大的收益。其次,我们发现解耦掩码和类别预测至关重要:我们独立地为每个类别预测一个二进制掩码,没有类别之间的竞争,并依靠网络的 RoI 分类分支来预测类别。相比之下,FCN 通常执行逐像素多类分类,将分割和分类结合起来,并且根据我们的实验,实例分割效果不佳。
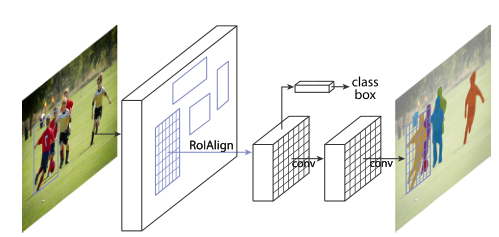
图 1. 用于实例分割的 Mask R-CNN 框架

图 2. 在 COCO 测试集上的 Mask R-CNN 结果。这些结果基于 ResNet-101,实现了 35.7 的掩码 AP 并以 5 fps 运行。掩码以颜色显示,并且还显示了边界框、类别和置信度.
作为一个通用框架,Mask R-CNN 与为检测/分割开发的互补技术兼容,正如过去几年在 Fast/Faster R-CNN 和 FCN 中广泛见证的那样。这份手稿还描述了一些改进了我们在 中发表的原始结果的技术。由于其通用性和灵活性,Mask R-CNN 被 COCO 2017 实例分割竞赛的三个获胜团队用作框架(图2),均显着优于之前的最新技术。我们已经发布了代码以促进未来的研究。
二、MASK R-CNN
Mask R-CNN 在概念上很简单:Faster R-CNN 对每个候选对象有两个输出,一个类标签和一个边界框偏移量;为此,我们添加了输出对象掩码的第三个分支。因此,Mask R-CNN 是一个自然而直观的想法。但是额外的掩码输出与类和框输出不同,需要提取更精细的对象空间布局。接下来,我们介绍 Mask R-CNN 的关键元素,包括像素到像素对齐,这是 Fast/Faster R-CNN 的主要缺失部分。更快的 R-CNN。我们首先简要回顾一下 Faster R-CNN 检测器 。Faster R-CNN 由两个阶段组成。第一阶段,称为区域提议网络,提出候选对象边界框。第二阶段,本质上是 Fast R-CNN,使用 RoIPool 从每个候选框中提取特征,并执行分类和边界框回归。两个阶段使用的特征可以共享以加快推理速度。掩码 R-CNN。Mask R-CNN 采用相同的两阶段程序,具有相同的第一阶段(即 RPN)。在第二阶段,在预测类和框偏移的同时,Mask R-CNN 还为每个 RoI 输出一个二进制掩码。这与最近的系统形成对比,其中分类取决于掩码预测。我们的方法遵循了 Fast R-CNN 的原则,它并行应用边界框分类和回归(结果证明这在很大程度上简化了原始 R-CNN的多阶段管道)。
为了解决量化时引入 RoI 和提取的特征之间的错位,我们提出了一个 RoIAlign 层,它消除了 RoIPool 的苛刻量化,将提取的特征与输入正确对齐。我们提出的改变很简单:我们避免对 RoI 边界或 bin 进行任何量化(即,我们使用 x/16 而不是 [x/16])。我们使用双线性插值来计算每个 RoI 箱中四个定期采样位置的输入特征的精确值,并聚合结果(使用最大值或平均值)。请参见图 3 了解我们的实现细节。我们注意到,只要没有对所涉及的任何坐标进行量化,结果对四个采样点在 bin 中的位置或采样的点数不敏感。
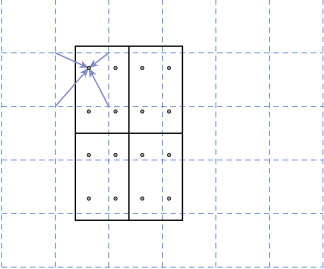
图3.RoIAlign 的实现:虚线网格是在其上执行 RoIAlign 的特征图,实线表示 RoI(在此示例中具有 2?2 个 bin),点表示每个 bin 内的 4 个采样点。每个采样点的值是通过特征图上附近网格点的双线性插值计算的。不对任何涉及 RoI、其 bin 或采样点的坐标执行量化。.使用原始输出反馈(RF)和模式相似性生物反馈(PSB)进行训练的假设效果。聚类表示与投影到2D子空间(即,在步骤1中创建的训练空间)上的运动类相关联的多维数据(特征)集合。C1已经用这两种方法进行了再培训(结果是C1Rf和C1OB)。
对于网络头,我们密切遵循之前工作中提出的架构,我们在其中添加了一个完全卷积的掩码预测分支。具体来说,我们从 ResNet 和 FPN 论文中扩展了 Faster R-CNN 盒头。详细信息如图 4 所示。ResNetC4 主干上的头部包括 ResNet 的第 5 阶段(即 9 层“res5”),这是计算密集型的。对于 FPN,主干已经包含 res5,因此允许使用更少过滤器的更高效的头部。
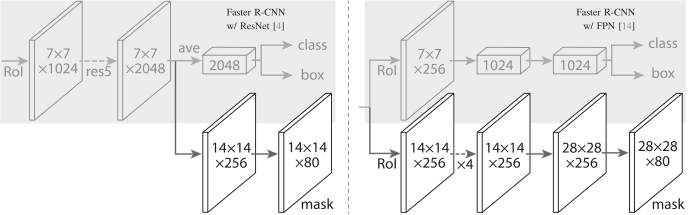
图4. 头部架构
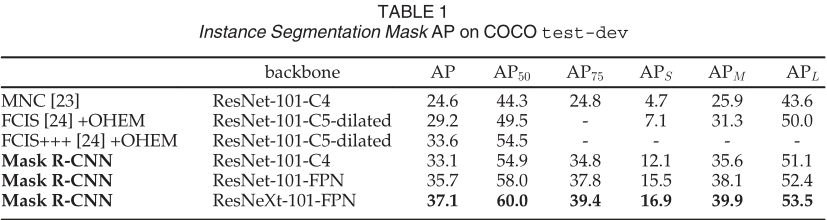
MNC 和 FCIS分别是 COCO 2015 和 2016 细分挑战赛的获胜者。没有花里胡哨的东西,Mask R-CNN 优于更复杂的 FCIS+++,其中包括多尺度训练/测试、水平翻转测试和 OHEM。所有条目都是单模型结果。
我们将 Mask R-CNN 与表 1 中实例分割中的最先进方法进行了比较。我们模型的所有实例都优于先前最先进模型的基线变体。
Mask R-CNN 输出在图 2 和图 5 中可视化。即使在具有挑战性的条件下,Mask R-CNN 也能取得良好的效果。在图 6 中,我们比较了我们的 Mask R-CNN 基线和 FCIS+++ 。FCIS+++ 在重叠实例上表现出系统性伪影,这表明它受到实例分割基本困难的挑战。Mask R-CNN 没有显示出这样的伪影。

图 5. Mask R-CNN 在 COCO 测试图像上的更多结果,使用 ResNet-101-FPN,以 5 fps 运行,具有 35.7 mask AP

图 6. FCIS+++(上)与 Mask R-CNN(下,ResNet-101-FPN)。FCIS 在重叠对象上展示系统伪影。
三、 实验:实例分割

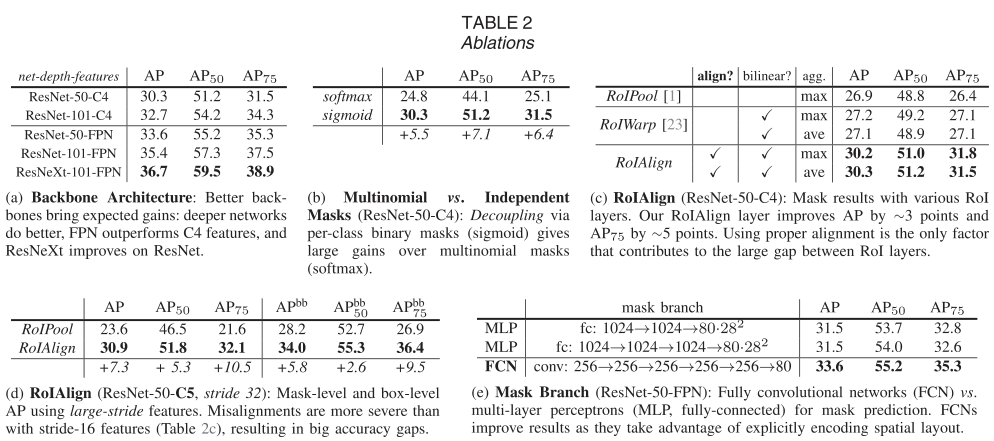
我们在 trainval35k 上进行训练,在 minival 上进行测试,并报告 mask AP,除非另有说明
表 2a 显示了具有各种主干的 Mask R-CNN。在表 2b 中,我们将其与使用每像素 softmax 和多项损失(如 FCN 中常用的)进行比较。这种替代方案将掩码和类别预测的任务结合起来,并导致掩码 AP 的严重损失(5.5 分)。这表明,一旦实例被分类为一个整体(通过框分支),就足以预测二进制掩码而无需考虑类别,这使得模型更容易训练。 我们提出的 RoIAlign 层的评估如表 2c 所示。对于这个实验,我们使用 ResNet50-C4 主干,步长为 16。
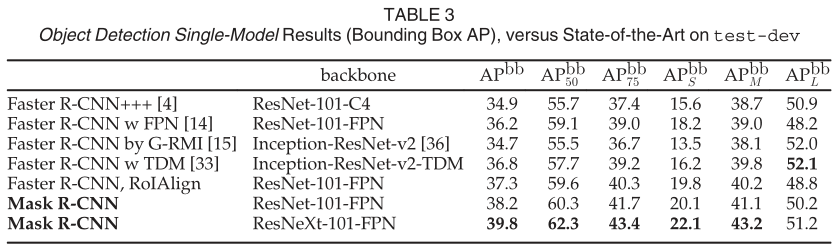
我们将 Mask R-CNN 与表 3 中最先进的 COCO 边界框目标检测进行了比较。对于这个结果,即使训练了完整的 Mask R-CNN 模型,也只使用了分类和框输出推理(掩码输出被忽略)。使用 ResNet-101-FPN 的 Mask R-CNN 优于所有先前最先进模型的基本变体,包括 G-RMI 的单模型变体,它是 COCO 2016 检测挑战赛的获胜者。使用 ResNeXt-101-FPN,Mask R-CNN 进一步改进了结果,与 (使用 Inception-ResNetv2-TDM)的最佳先前单个模型条目相比,框 AP 的边距为 3.0 点。
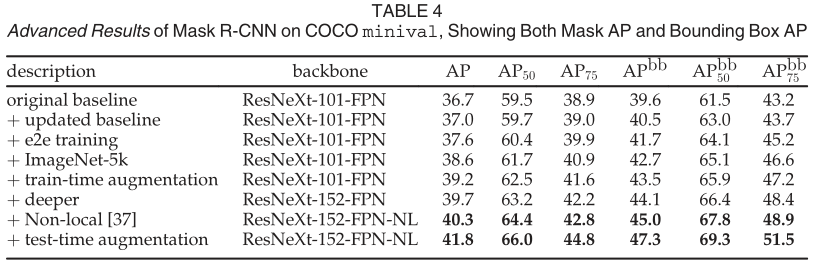
每行显示一个额外的组件递增到上面的行
Mask R-CNN 是一个通用框架,并且与在许多其他检测/分割系统中看到的正交改进兼容。为了完整起见,我们在表 4 中报告了 Mask RCNN 的一些高级结果。此表中的结果可以通过我们发布的代码 (https://github.com/facebookresearch/Detectron) 重现,这可以作为未来研究的更高基线。
总体而言,我们实现的改进总共实现了 5.1 点掩码 AP(从 36.7 到 41.8)和 7.7 点盒子 AP(从 39.6 到 47.3)增加。通常,改进的每个组件都一致地增加了 mask AP 和 box AP,显示了 Mask RCNN 作为框架的良好泛化。我们从具有不同超参数集的更新基线开始。我们将训练延长到 180k 次迭代,其中在 120k 和 160k 次迭代时学习率降低了 10。我们还将 NMS 阈值更改为 0.5(默认值为 0.3)。更新后的基线有 37.0 mask AP 和 40.5 box AP。
四、 关键点估计与实景监测
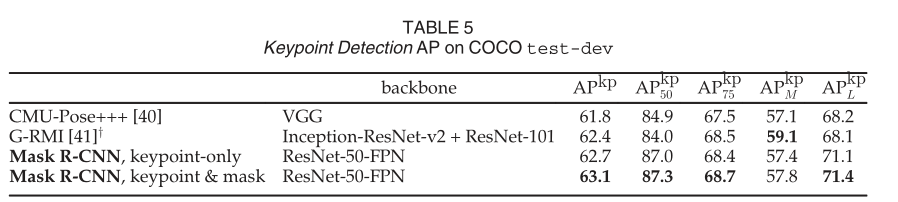
我们的 (ResNet-50-FPN) 是一个以 5 fps 运行的单一模型。CMU-Pose+++ 是 2016 年竞赛的获胜者,它使用多尺度测试、使用 CPM 进行后处理,并使用对象检测器进行过滤,增加了累积的 5 分(在个人交流中澄清)。y:G-RMI 在 COCO plus MPII (25k 图像)上进行训练,使用两个模型(Inception-ResNet-v2 用于边界框检测,ResNet-101 用于关键点)。

图 7. 使用 Mask R-CNN (ResNet-50-FPN) 在 COCO 测试中的关键点检测结果,以及从同一模型预测的人分割掩码。该模型的关键点 AP 为 63.1,运行速度为 5 fps
更重要的是,我们有一个统一的模型,可以同时预测框、段和关键点,同时以 5 fps 运行。添加一个段分支(针对人员类别)在 test-dev 上将 APkp 提高到 63.1(表 5)。更多关于 minival 的多任务学习消融在表 6 中。将掩码分支添加到仅盒子(即 Faster R-CNN)或仅关键点版本持续改进了这些任务。然而,添加关键点分支会略微减少框/掩码 AP,这表明虽然关键点检测受益于多任务训练,但它反过来并不能帮助其他任务。然而,联合学习所有三个任务使统一系统能够同时有效地预测所有输出(图 7)。Cityscapes 的示例结果如图 8 所示。

图 8. 在 Cityscapes 测试(32.0 AP)上的 Mask R-CNN 结果。右下角的图像显示了故障预测。
五、结论
我们提出了一个简单而有效的实例分割框架,该框架在边界框检测方面也显示出良好的结果,并且可以扩展到姿态估计。我们希望这个框架的简单性和通用性将有助于未来对这些和其他实例级视觉识别任务的研究。
原文标题:【AI+机器人】Mask-CNN 一种目标识别与实例分割算法
文章出处:【微信公众号:机器视觉智能检测】欢迎添加关注!文章转载请注明出处。
审核编辑:汤梓红
-
框架
+关注
关注
0文章
403浏览量
17639 -
分割
+关注
关注
0文章
17浏览量
11957 -
mask
+关注
关注
0文章
10浏览量
2988
原文标题:【AI+机器人】Mask-CNN 一种目标识别与实例分割算法
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
介绍目标检测工具Faster R-CNN,包括它的构造及实现原理

分享下Kaiming大神在CVPR‘18 又有了什么新成果?

什么是Mask R-CNN?Mask R-CNN的工作原理
引入Mask R-CNN思想通过语义分割进行任意形状文本检测与识别
手把手教你操作Faster R-CNN和Mask R-CNN
FAIR何恺明、Ross等人最新提出实例分割的通用框架TensorMask
Facebook AI使用单一神经网络架构来同时完成实例分割和语义分割

一种基于Mask R-CNN的人脸检测及分割方法

基于Mask R-CNN的遥感图像处理技术综述
深度学习部分监督的实例分割环境
3D视觉技术内容理解领域的研究进展
PyTorch教程14.8之基于区域的CNN(R-CNN)

PyTorch教程-14.8。基于区域的 CNN (R-CNN)






 工商网监
工商网监
评论