 无人车业务中的视觉三维重建
无人车业务中的视觉三维重建
业务背景
高精地图也称为高分辨率地图(High Definition Map, HDMap)或者高度自动驾驶地图(Highly Automated Driving Map, HAD Map)。近些年,随着自动驾驶技术以及业务的蓬勃发展,高精地图成为了实现高等级自动驾驶必不可少的数据。
高精地图是一类拥有精确的地理位置信息和丰富的道路元素语义信息的地图数据,能起到构建类似于人脑对于空间的整体记忆与认知功能,可以帮助自动驾驶车辆预知路面复杂信息,如坡度、曲率、航向等,更好的规避潜在的风险。是实现自动驾驶的关键所在。
高精地图以精细描述道路及其车道线、路沿、护栏、交通灯、交通标志牌、动态信息为主要内容,具有精度高、数据维度多、时效性高等特点。为自动驾驶汽车的规划、决策、控制、定位、感知等应用提供支撑,是自动驾驶解决方案的基础及核心。
高精地图与普通的导航地图不同,主要面向自动驾驶汽车,通过车辆自身特有的定位导航体系,协助自动驾驶系统完成规划、决策、控制等功能,以及解决自动驾驶车辆计算性能限制问题,拓展传感器检测范围。
通俗来讲,高精地图是比普通导航地图精度更高,数据维度更广的地图。其精度更高体现在地图精度精确到厘米级,数据维度更广则体现在地图数据除了道路信息以外还包括与交通相关的周围静态、动态信息。
普通导航地图(左)vs高精地图(右)
1.2 高精地图对自动驾驶的价值
高精地图作为自动驾驶的稀缺资源和必备构件,能够满足自动驾驶车辆在行驶过程中地图精确计算匹配、实时路径规划导航、辅助环境感知、驾驶决策辅助和智能汽车控制的需要,并在每个环节都发挥着至关重要的作用。主要有以下几个方面: 辅助环境感知 传感器作为自动驾驶的感官,有其局限性,如易受恶劣环境影响,性能受限或者算法鲁棒性不足等。高精地图可以对传感器无法探测或者探测精度不够的部分进行补充,实现实时状况的检测以及外部信息的反馈,进而获取当前位置精准的交通状况。
通过对高精地图的解析,可以将当前自动驾驶车辆周边的道路、交通设施、基础设施等元素和元素质检的拓扑连接关系提取出来。如果自动驾驶汽车在行驶过程中检测到高精地图不存在的元素,则在一定程度上可将这些元素视为障碍物。通过该方式,可以帮助感知系统识别周围环境,提高检测精度和检测速度,并节约计算资源。
辅助定位 由于定位系统可能因环境关系或者系统稳定性问题存在定位误差,无人驾驶车辆并不能与周围环境始终保持正确的位置关系,在无人驾驶车辆行驶过程中,利用高精地图元素匹配可精确定位车辆在车道上的具体位置,从而提高无人驾驶车辆的定位精度。
相比更多的依赖于GNSS(Global Navigation Satellite System,全球导航卫星系统)提供定位信息的普通导航地图,高精地图更多依靠其准确且丰富的先验信息(如车道形状、曲率、路面导向箭头、交通标志牌等),通过结合高维度数据与高效率的匹配算法,能够实现符合自动驾驶车辆所需的高精度定位功能。
辅助路径规划决策 普通导航地图仅能给出道路级的路径规划,而高精地图的路径规划导航能力则提高到了车道级,例如高精地图可以确定车道的中心线,可以保证无人驾驶车辆尽可能地靠近车道中心行驶。在人行横道、低速限制或减速带等区域,高精地图可使无人驾驶车辆能够提前查看并预先减速。对于汽车行驶附近的障碍物,高精地图可以帮助自动驾驶汽车缩小路径选择范围,以便选择最佳避障方案。
辅助控制 高精地图是对物理环境道路信息的精准还原,可为无人驾驶车辆加减速、并道和转弯等驾驶决策控制提供关键道路信息。而且,高精地图能给无人驾驶车辆提供超视距的信息,并与其他传感器形成互补,辅助系统对无人驾驶车辆进行控制。
高精地图为无人驾驶车辆提供了精准的预判信息,具有提前辅助其控制系统选择合适的行驶策略功能,有利于减少车载计算平台的压力以及对计算性能瓶颈的突破,使控制系统更多关注突发状况,为自动驾驶提供辅助控制能力。因此,高精地图在提升汽车安全性的同时,有效降低了车载传感器和控制系统的成本。
1.3 高精地图生产的路线
精度与成本的平衡
与传统的标精地图生产相比,卫星影像已经无法满足高精地图的精度需求,地图制作需要在地面进行实际道路采集。为了满足高精地图的精度需求,业界的各家公司分别给出了不同的数据采集方案。主要可以分为以激光雷达(LiDAR)+ 组合惯导 + RTK的高精度自采方案,以及有RTK+视觉的众包采集方案。
简单的讲,这两种方案主要是在精度与成本两个因素中进行取舍的结果。两者都经历了长期的演进,孰优孰劣无法一概而论。或者说,方案的选择更多的要看具体的业务需求与场景条件。接下来本文对两种采集方案进行简要的介绍。
“高富帅”的高精自采方案:LiDAR+惯导+RTK
很多自动驾驶厂商目前上线使用的高精地图的原始数据都采集自高规格的多传感器(LiDAR+惯导+RTK)采集设备。这种数据可重建出具备厘米级精度的道路地图,但其采用的各种“顶配传感器”动辄几十万元。业界常见的装备齐全的高精地图采集车通常都需要几百万元一辆。加上其背后的巨大的数据处理及运维成本,真可谓是“高富帅”的建图方案。
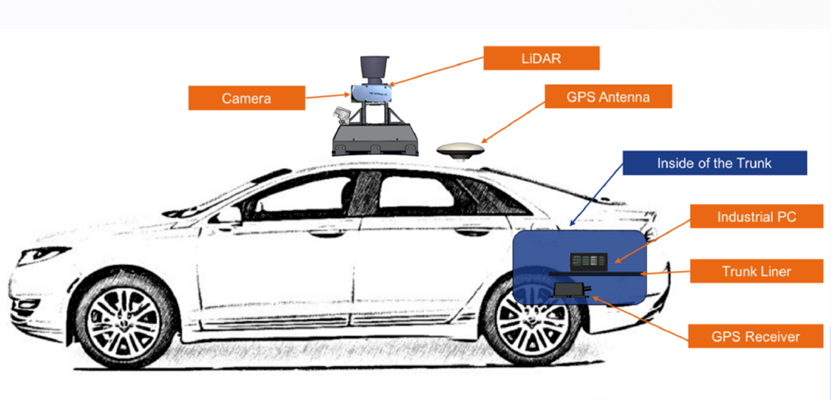
“LiDAR+惯导+RTK” 采集方案的采集车¹²
在这种方案下,建图主要过程是以惯导+RTK融合的位姿作为先验,之后基于LiDAR点云进行三维场景的高精重建。得到精确的位姿和点云后,再通过LiDAR在地面上的反射率图恢复出路面标识,并进一步进行矢量化,最终完成高精地图的生产。通常而言,这种以LiDAR+惯导为主的建图方法所获得的高精地图可以达到厘米级别的地图精度,以满足自动驾驶中实时精准定位的需求。
经济实惠的视觉众包方案:GNSS+视觉
对于高精地图生产而言,最大的成本不在于完成一次全路网的地图构建,而在于如何解决高精地图的随时更新。如何用较低的成本维持一个城市级别乃至国家级别路网的鲜度,才是各大地图厂商面临的最大挑战。
随着传感器芯片的不断发展,集成了GNSS、IMU(Inertial measurementunit,惯性测量单元)模块与摄像头的模块的一体式设备成本已经到达百元级别。事实上,这一传感器组合采集的数据在很多路况下已经可以胜任高精地图重建任务。目前道路上有大量乘用车已经安装了带有GNSS功能的行车记录仪。一方面,行车记录仪可以保证日常的行车安全需要。另一方面,记录仪采集的原始数据可以通过网络回传到服务器,经过数据清洗工作后形成建图数据集,并进一步通过地图重建算法形成高精地图。
由于传感器成本较低,这样的采集数据较之上文的“高富帅”方案精度较低,同时受路况和天气的影响较大。因此在这种方案下,需要有很好的算法能力以及数据清洗能力,才能完成相应的高精地图生产与更新。
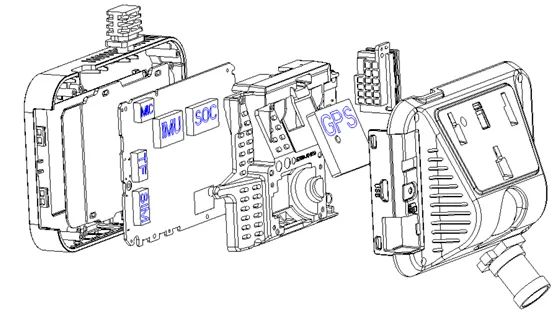
GNSS+视觉解决方案¹³ 对于这种性价比极高的众包方案,技术上有很多难关要攻克。例如如何高效合理的对原始采集数据进行回传与筛选,如何指定特定的区域进行更新,如何克服低价传感器带来的各种误差,如何解决设备多样性带来的误差等等。同时,如果真的将这种方式投入到规模化的高精地图生产,还需要解决好法律上的测绘合规的问题。 本文要介绍的视觉重建算法,正是这种高性价比重建方案中的核心技术。接下来,将基于这种GNSS+视觉的采集方式,介绍一下几类可行的视觉重建系统设计方案。
视觉重建的系统设计
基于不同业务场景,数据特点,研发人员可以为视觉重建设计不同的算法流程。这里简单介绍三类:基于Structure-from-Motion的重建、基于深度网络的视觉重建、基于语义的矢量化视觉重建。下面将一一进行介绍。 2.1 基于Structure-from-Motion的重建 在视觉高精地图重建方面,Structure-form-Motion (SfM) 方案是非常常见的选择。从业务需求上讲,建图大多无实时性要求,而对精度的要求较为严格。相比之下,各种VO或SLAM方案要追求实时性,同时其最终的目的更倾向于定位,而非建图。SfM方案更强调建图的精度,方案中并无时序性要求。这为地图的长期维护提供了便利。典型的SfM重建流程大致可以分为特征提取、稀疏重建,稠密重建三个步骤。

Colmap中的SfM重建流程¹⁴ 特征与匹配 在SfM中,首先要进行的就是特征点的提取与匹配工作。这一部分中,最经典的莫过于SIFT特征子¹。如果不限制具体的应用场景(室内 vs. 室外,自然景观 vs. 人造物体等等),那么SIFT特征子可以在各类场景中均有比较稳定的特征提取与匹配结果。 随着近些年深度学习网络的发展,很多研究者提出了基于深度学习的特征提取与匹配方案。其中最著名的当属MagicLeap团队提出的SuperPoint(CVPR2018)²+ SuperGlue(CVPR2020)³方案。 SuperPoint作为一种特征点提取算法,采用了自监督的方式进行训练,并采用了Homographic Adaptation技术大大加强了提取特征点的场景适应性。相比于传统的SIFT,提取的特征点可信度更强。 SuperGlue作为一种特征匹配算法,引入了注意力机制来强化网络对特征的表达能力,从而使得在视差较大的两幅图像之间仍然可以很好的找到特征点间的匹配关系。在CVPR2020/ECCV2020的indoor/outdoor localization challenges中,使用了SuperPoint以及SuperGlue的方案名列前茅,充分展现了这两种方法在特征提取与匹配方面的优势。

基于SuperPoint+SuperGlue的特征提取与匹配效果¹⁵ 在今年的CVPR2021上,商汤团队发表了LofTR⁴。该工作基于Transformer构建了一个端到端的特征匹配模型,对于弱纹理区域可以给出较为准确的匹配结果。由于Transformer提供了较大的感受野,使之可以更好的利用全局信息去对局部特征进行描述。相较SuperPoint+SuperGlue,该方法在室内的弱纹理场景有着更为稳定可信的匹配结果。

LofTR的特征匹配结果¹⁶稀疏重建 完成了特征点的提取与匹配后,便可以开始增量式的稀疏重建。算法会基于一定的筛选条件,选择两帧作为初始帧,利用双视几何(two-view-geometry)的方法计算两帧的相对位姿,并基于其中的一帧构建本次重建的坐标系。当位姿确认后,就可以基于特征点的匹配关系,三角化出空间中的3D地图点。初始化完成后,便可以继续选择尚未注册的新图像注册到模型中。注册时可以用双视几何计算其与已有帧的相对位姿,也可以用3D-2D的方法(例如PnP, pespective-n-point)计算位姿,甚至可以使用精度较高的先验位姿直接注册。注册后要再次进行三角化,计算出更多的3D地图点。同时,在注册一定数量的新帧后,需要进行BA(bundle adjustment)优化,进一步优化位姿与地图点的精度。上述注册新帧,三角化,BA优化的过程将循环进行,直到完成所有图像的重建。最终,就获得了所有图像的位姿以及一个由稀疏地图点构成的稀疏重建结果。

长距离稀疏重建结果
稠密重建
完成稀疏重建后,需要进行稠密化建图。这个过程中,首先要解决深度估计问题。得到了深度图之后,结合深度图与相机位姿,就可以进行物体表面纹理的稠密重建。
以Colmap⁵中的稠密重建过程为例。首先要进行深度估计。这个模块大致可分为匹配代价构造,代价累积,深度估计,深度图优化这四个部分。Colmap中使用了NCC来构造匹配代价,之后使用Patch Match作为信息传递的策略。通过这个过程,深度估计问题转化为针对每个特征,寻找其最优的深度和法向量。整个过程利用GEM算法进行优化。Colmap中的方案对于弱纹理的区域无法很好的给出较好的深度估计。
在得到深度估计结果(深度图)后,各帧的深度图会进行融合。在融合后RGB图像上的像素就可以投影到三维空间中,得到稠密点云,完成最终的稠密重建。
对于道路场景而言,由于路面的特征点非常稀少(典型的弱纹理),所以使用经典的算法恢复路面纹理具有较大的挑战。于是,很多研究者开始尝试利用深度神经网络去解决这一难题。
2.2 基于深度网络的视觉重建 在SfM中,当在稀疏重建中获得了相机的位姿之后,还需要稠密的深度图来准确的恢复出路面的DOM(Digital Orthophoto Map,数字正射影像图)以及各种交通标识。而基于特征点的SfM仅能提供一些稀疏的路面点,这对于恢复路面平面是远远不够的。因此需要借助其他方法来进行稠密的深度恢复。 近些年,随着深度学习的迅猛发展,越来越多的工作实现了基于RGB图像的深度预测。按照工作发表的前后顺序,大致可以将这一研究方向分为四类,分别是:基于单帧图像的深度估计,基于多帧图像的深度估计,同时估计相机运动与深度,基于自监督训练的运动与深度估计。 基于单帧的深度估计 对于神经网络深度估计,最简单的方式要算基于单帧的深度估计。这一领域比较经典的工作有MonoDepth⁶及MonoDepth2⁷这两个工作基于双目的约束进行无监督训练,获得的模型可以基于单帧RGB图像输出深度图。 此种方法虽然可以很好的预测出稠密的深度图,但由于在预测过程中缺乏几何约束,因此模型存在泛化性的问题。一旦相机参数或者场景类型发生了变化,模型很难保证可以给出正确的深度预测。同时,帧间的深度连续性也是这种方法难以解决的问题。因此,单帧的深度预测很难应用到高精地图的重建过程中。

单目深度预测:MonoDepth2¹⁷
基于多帧图像的深度估计
考虑到实际场景中我们的输入是一个图像序列,因此利用多视几何(Multiview Video Stereo, MVS)进行多帧的深度估计可以很好的解决单帧深度估计中多帧之间的深度连续性问题,同时由于可以利用帧间的几何约束,模型能预测更准确的深度值。
近些年很多工作围绕这个问题展开。一个比较经典的工作是MVSNet⁸,作者利用多帧构建cost volume,对深度进行估计。获得初步的深度估计结果后,再通过一个优化网络,对深度图做进一步的优化,最终可以得到比较理想的深度信息。对于视觉高精重建任务而言,由于位姿存在着一定的误差。因此一旦某一帧的位姿计算错误,将会直接影响相邻帧的深度预测。因此这种方案在道路重建任务中存在着一定的局限性。
同时估计相机运动与深度
解决多帧图像深度估计问题时,可以借鉴经典SfM算法中“预测新帧的位姿-三角化获得地图点”这样迭代的思路,让网络交替预测位姿与深度,并进行多轮迭代。这样能保证深度与位姿之间可以有很好的几何匹配,同时也可以获得较高的预测精度。
在这一方面,DeepV2D⁹是一个比较有代表性的工作。DeepV2D中引入了深度估计和运动估计两个子网络。网络会选取一个长度为5-8帧的滑窗,滑窗内的图像会输入到两个子网络中,推理得到的深度和位姿会相互更新。经过几轮更新之后,最终就可以得到连续性好,精度高的深度预测结果。这种网络设计充分的利用了图像的运动特性与几何约束,可以很好的利用相邻的多帧信息的对深度进行预测。在两个子网迭代结果的过程中,预测精度会逐渐收敛,得到的深度也会有比较好的连续性。
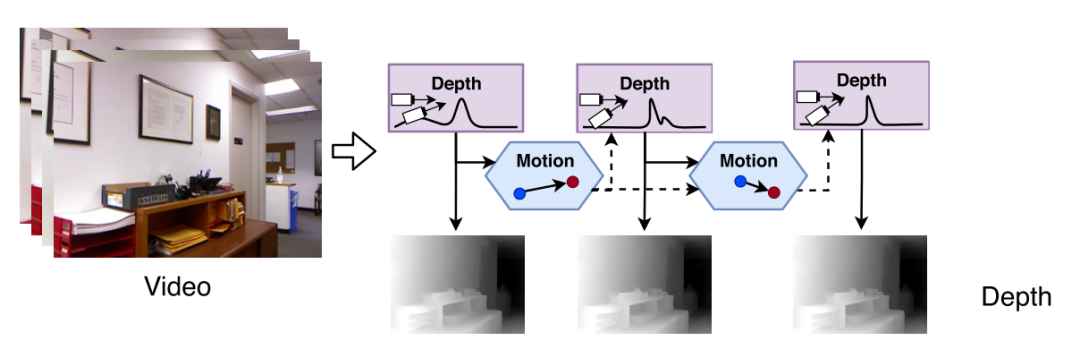
同时预测深度与相机运动的网络:DeepV2D¹⁸
下图展示了使用LiDAR数据训练而得的深度估计网络模型,在实际道路上预测深度的结果。可见在这种典型的弱纹理场景下,网络一方面可以较好的预测出平整的路面,同时也可以对物体边缘(路沿,树木)有较好的描述。

输入RGB图像(上)深度预测结果(下)
基于自监督训练的运动与深度估计
在上一类工作中,为了训练运动估计网络与深度估计网络,需要大量高精度的深度图作为训练数据。为了解决一些业务上缺乏训练数据的问题,有一些研究者提出了无监督的训练方法去进行单目深度估计训练。例如最近在CVPR2021上发表的ManyDepth¹⁰。类似于Monodepth,此方法利用了cost volume进行深度估计。对于相邻帧,其预测了帧间的相对位置,以便于多帧之前构建cost volume。同时也使用提取局部特征的方法,将特征图输入到最终的深度预测中,提高深度预测的稳定性。对于道路场景深度预测中最难解决的动态物体问题,该工作也给出了基于置信度预测的解决方案。
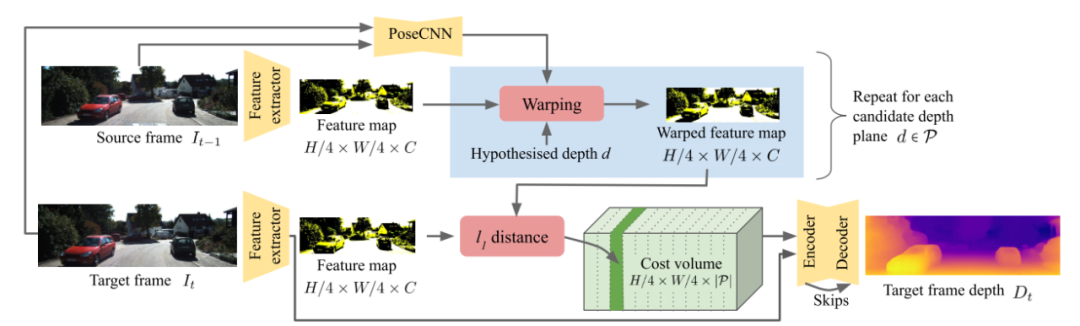
自监督的单目深度估计网络:ManyDepth¹⁹
2.3 基于语义的矢量化视觉重建
端侧实时重建
在业界一些厂商的实践中,有些公司提出了“通过语义分割检测+语义重建来创建矢量地图”(地平线NavNet方案¹¹)。该方案仅需一颗前视摄像头,运用深度学习和SLAM技术实现了道路场景的语义三维重建,将建图与定位的过程全部在车端实时进行。车辆通过前视摄像头捕捉即时交通信息,然后抽象出道路场景的特征(即实现场景语义三维重建),并直接在车端完成地图“绘制”与定位。 在数据采集过程中,路况信息的采集通过几项相关的传感器来实现——摄像头,GNSS和IMU。在这之后,输入的图像数据会进行基于神经网络的语义分析,以获得主要的道路要素信息。 在建图过程中,方案通过语义SLAM的方式来实现高精度地图的创建。具体来说,方案使用语义分割检测+语义重建来创建矢量地图,将后端优化、语义识别和参数化等方面和链路,融合成为一条优化模块——联合优化模块,既简化了工作的流程,节约时间和运算能耗,又可以实现同样的功能。 如果在同一路段有多次采集的数据,在云端可以将大量车辆采集的地图片段数据进行关联匹配,以矢量地图要素的属性参数为变量,根据属性的相似度约束建立统一的目标函数,优化求解以获得融合地图结果。这一融合优化过程既可以定时全量执行,也可以根据地图更新的结论,经过事件触发进行高效融合之后,提供更新、更精准的地图信息,即可快速地发布到车端供车辆定位导航使用。
离线重建
由于实时性的要求,端侧实时重建方案需要偏定制化的硬件方案来提供足够的算力支撑。另一方面,如果不需要实时的建图,也可以使用前文提到的SfM方式先进行稀疏重建并使用神经网络预测深度图,之后结合语义分割结果进行后续的要素跟踪与矢量化。
具体而言,在获得相机位姿和深度信息后,可以将路面像素投影到世界坐标系中。之后,使用了语义跟踪的技术来对反投影出的路面进行融合。也就是利用帧间特征点的匹配关系,将每一帧投影的路面切片进行对齐与融合,就可以得到相对平整清晰的路面DOM。同时在图像上进行路面标识的检测,基于检测结果提取矢量关键点,并把这些关键点投到路面,就获得了矢量化的路面标识。在长距离的重建过程中,在多次经过或者掉头的场景,会出现已经矢量化的车道线或路面标识重影。可以对已经恢复出的矢量标识进行回环检测,并对其进行与融合,进一步消弭位姿与深度误差带来的影响。

基于语义分割及检测进行路面标识矢量化(上)车道线矢量化的结果(下)
业务实践中的探索
上文介绍了业界常见的几种视觉建图方案路线。在实际应用的过程中,可以基于业务场景、数据特点、成本限制、硬件条件等实际因素,对其中的一些步骤进行改造或组合。在这种改造中,只有对每种建图路线的优劣、限制条件有着比较深入的理解,才能真正设计出贴合业务需求的好算法方案。在无人车的地图生产过程中,我们结合实际运营的业务需求与场景条件,也进行了一些积极的探索。
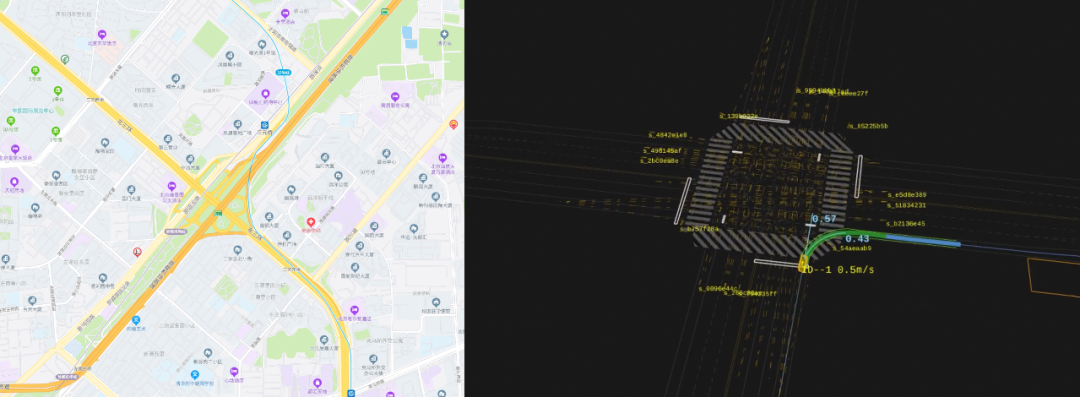
在SfM重建过程中,目前稀疏重建算法只能处理短距离场景(2公里左右),而这距离实际业务需求有着指数级的差距。我们设计了分段重建、多段拼接以及联合优化的策略,把稀疏重建算法真正的应用于实际业务,不仅保证了重建精度,绝对误差控制在0.5米以内,而且极大的缩短了重建耗时。
在特征点提取以及深度估计的网络训练过程中,目前的公开数据集和实际业务场景之间存在较大的domain gap。因此我们采用了transfer learning的算法进行了初步的探索,取得了不错的成果,最终重建的精度和稳定性都获得了显著的提升。
总结与展望
在高精建图重建任务中,相比于激光建图路线,视觉建图路线具备精度略低,成本极低,算力消耗较低等特点。因此,视觉建图更适合进行大范围实时的更新。 在业务实践中,激光建图和视觉建图的优势被很好的融合在了一起。在视觉重建方案中,利用了激光建图生成的点云数据进行训练数据集的构建,得到了贴合实际场景的深度预测模型。通过视觉重建获得的DOM和道路元素矢量结果可以对激光建图结果形成很好的补充,提高了建图生产的鲁棒性。 在后续的迭代过程中,我们会持续的基于业务的需要和运营场景的特点进行技术优化。除了提升既有的方案性能,还将对一些新的方向进行探索,包括:
全路况全天候的更新发现技术
全国范围内全等级道路的更新维护能力
端云结合的建图计算架构
希望通过我们的努力,为无人车配送业务提供新鲜而高质量的高精地图,保证业务的健康发展,把生活的便利带给每一位消费者。
审核编辑 :李倩
-
自动驾驶
+关注
关注
784文章
13779浏览量
166350 -
无人车
+关注
关注
1文章
301浏览量
36469
原文标题:无人车业务中的视觉三维重建
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
三维激光扫描仪与无人机结合的应用
商汤科技运用AI大模型实现实景三维重建
CASAIM与迈普医学达成合作,三维扫描技术助力医疗辅具实现高精度三维建模和偏差比对
建筑物边缘感知和边缘融合的多视图立体三维重建方法

三维可视化技术的应用现状和发展前景
留形科技借助NVIDIA平台提供高效精确的三维重建解决方案
基于大模型的仿真系统研究一——三维重建大模型
泰来三维|三维激光扫描技术在古建筑保护中的应用

三维可视:展现未来的视觉盛宴
泰来三维|数字化工厂_煤矿三维扫描数字化解决方案

三维扫描与3D打印在法医头骨重建中的突破性应用
泰来三维|文物三维扫描,文物三维模型怎样制作

工业上常见的高精度主动式重建算法
基于光学计算超表面的全光学目标识别和三维重建技术





 工商网监
工商网监
评论