 使用NVIDIA FLARE开发更具通用性的AI模型
使用NVIDIA FLARE开发更具通用性的AI模型
联邦学习( FL )已成为许多实际应用的现实。它使全球范围内的跨国合作能够构建更健壮、更通用的机器学习和人工智能模型。
NVIDIA FLARE v2.0 是一款开源的 FL SDK ,通过共享模型权重而非私有数据,数据科学家可以更轻松地协作开发更具通用性的健壮人工智能模型。
对于医疗保健应用程序,这在数据受患者保护、某些患者类型和疾病的数据可能稀少,或者数据在仪器类型、性别和地理位置上缺乏多样性的情况下尤其有益。
查看标志
NVIDIA FLARE 代表 联合学习应用程序运行时环境 。它是引擎的基础NVIDIA Clara Train FL 软件,它已经被用于医学成像、遗传分析、肿瘤学和 COVID-19 研究中的人工智能应用。 SDK 使研究人员和数据科学家能够将其现有的机器学习和深度学习工作流调整为分布式范例,并使平台开发人员能够为分布式多方协作构建安全、隐私保护的产品。
NVIDIA FLARE 是一个轻量级、灵活且可扩展的分布式学习框架,在 Python 中实现,与您的基础培训库无关。您可以在 PyTorch , TensorFlow ,甚至只是 NumPy 中实现自己的数据科学工作流,并在联邦设置中应用它们。
也许您希望实现流行的 联邦平均( FedAvg )算法 。从初始全局模型开始,每个 FL 客户机在其本地数据上训练模型一段时间,并将模型更新发送到服务器进行聚合。然后,服务器使用聚合更新来更新下一轮培训的全局模型。此过程将反复多次,直到模型收敛。
NVIDIA FLARE 提供可定制的控制器工作流,以帮助您实施 FedAvg 和其他 FL 算法,例如, 循环重量转移 。它安排不同的任务,例如深度学习培训,在参与的 FL 客户机上执行。工作流使您能够从每个客户端收集结果(例如模型更新),并将其聚合以更新全局模型,并将更新的全局模型发回以供继续培训。图 1 显示了原理。
每个 FL 客户机充当工人,请求执行下一个任务,例如模型培训。控制器提供任务后,工作人员执行任务并将结果返回给控制器。在每次通信中,可以有可选的过滤器来处理任务数据或结果,例如, homomorphic encryption 和解密或差异隐私。
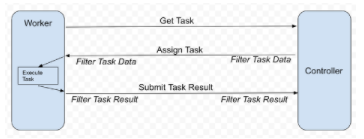
图 1 。 NVIDIA FLARE 工作流
实现 FedAvg 的任务可以是一个简单的 PyTorch 程序,它为 CIFAR-10 训练一个分类模型。您当地的培训师可能看起来像下面的代码示例。为了简单起见,我跳过了整个培训循环。
import torch import torch.nn as nn import torch.nn.functional as F from nvflare.apis.dxo import DXO, DataKind, MetaKey, from_shareable from nvflare.apis.executor import Executor from nvflare.apis.fl_constant import ReturnCode from nvflare.apis.fl_context import FLContext from nvflare.apis.shareable import Shareable, make_reply from nvflare.apis.signal import Signal from nvflare.app_common.app_constant import AppConstants class SimpleNetwork(nn.Module): def __init__(self): super(SimpleNetwork, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = torch.flatten(x, 1) # flatten all dimensions except batch x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x class SimpleTrainer(Executor): def __init__(self, train_task_name: str = AppConstants.TASK_TRAIN): super().__init__() self._train_task_name = train_task_name self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") self.model = SimpleNetwork() self.model.to(self.device) self.optimizer = torch.optim.SGD(self.model.parameters(), lr=0.001, momentum=0.9) self.criterion = nn.CrossEntropyLoss() def execute(self, task_name: str, shareable: Shareable, fl_ctx: FLContext, abort_signal: Signal) -> Shareable: """ This function is an extended function from the superclass. As a supervised learning-based trainer, the train function will run training based on model weights from `shareable`. After finishing training, a new `Shareable` object will be submitted to server for aggregation.""" if task_name == self._train_task_name: epoch_len = 1 # Get current global model weights dxo = from_shareable(shareable) # Ensure data kind is weights. if not dxo.data_kind == DataKind.WEIGHTS: self.log_exception(fl_ctx, f"data_kind expected WEIGHTS but got {dxo.data_kind} instead.") return make_reply(ReturnCode.EXECUTION_EXCEPTION) # creates an empty Shareable with the return code # Convert weights to tensor and run training torch_weights = {k: torch.as_tensor(v) for k, v in dxo.data.items()} self.local_train(fl_ctx, torch_weights, epoch_len, abort_signal) # compute the differences between torch_weights and the now locally trained model model_diff = ... # build the shareable using a Data Exchange Object (DXO) dxo = DXO(data_kind=DataKind.WEIGHT_DIFF, data=model_diff) dxo.set_meta_prop(MetaKey.NUM_STEPS_CURRENT_ROUND, epoch_len) self.log_info(fl_ctx, "Local training finished. Returning shareable") return dxo.to_shareable() else: return make_reply(ReturnCode.TASK_UNKNOWN) def local_train(self, fl_ctx, weights, epoch_len, abort_signal): # Your training routine should respect the abort_signal. ... # Your local training loop ... for e in range(epoch_len): ... if abort_signal.triggered: self._abort_execution() ... def _abort_execution(self, return_code=ReturnCode.ERROR) -> Shareable: return make_reply(return_code)
您可以看到您的任务实现可以执行许多不同的任务。您可以计算每个客户机上的摘要统计信息,并与服务器共享(记住隐私限制),执行本地数据的预处理,或者评估已经训练过的模型。
在 FL 培训期间,您可以在每轮培训开始时绘制全局模型的性能。对于本例,我们在 CIFAR-10 的异构数据拆分上运行了八个客户端。在下图(图 2 )中,我显示了默认情况下 NVIDIA FLARE 2.0 中可用的不同配置:
FedAvg
FedProx
FedOpt
使用同态加密进行安全聚合的 FedAvg ( FedAvg HE )
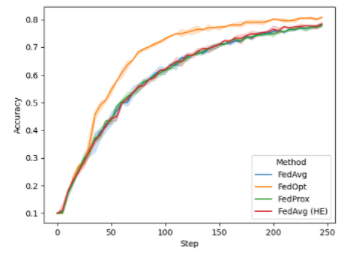
图 2 。训练期间不同 FL 算法全局模型的验证精度
虽然 FedAvg 、 FedAvg HE 和 FedProx 在这项任务中的性能相当,但您可以使用 FedOpt 设置观察到改进的收敛性,该设置使用 SGD with momentum 来更新服务器上的全局模型。
整个 FL 系统可以使用管理 API 进行控制,以自动启动和操作不同配置的任务和工作流。 NVIDIA 还提供了一个全面的资源调配系统,可在现实世界中轻松安全地部署 FL 应用程序,同时还提供了运行本地 FL 模拟的概念验证研究。
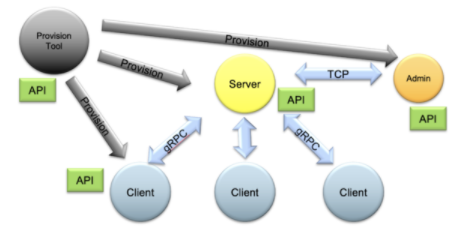
图 3 。 NVIDIA FLARE 供应、启动、操作( PSO )组件及其 API
开始
NVIDIA FLARE 使 FL 可用于更广泛的应用。潜在使用案例包括帮助能源公司分析地震和井筒数据、制造商优化工厂运营以及金融公司改进欺诈检测模型。
关于作者
Holger Roth 是 NVIDIA 的高级应用研究科学家,专注于医学成像的深度学习。在过去几年中,他一直与临床医生和学者密切合作,为放射应用开发基于深度学习的医学图像计算和计算机辅助检测模型。他拥有博士学位。来自英国伦敦大学学院。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
4985浏览量
103037 -
计算机
+关注
关注
19文章
7494浏览量
87935 -
深度学习
+关注
关注
73文章
5503浏览量
121154
发布评论请先 登录
相关推荐
AI大语言模型开发步骤
NVIDIA推出全新生成式AI模型Fugatto
全新NVIDIA NIM微服务实现突破性进展
使用全新NVIDIA AI Blueprint开发视觉AI智能体
NVIDIA助力提供多样、灵活的模型选择
NVIDIA Nemotron-4 340B模型帮助开发者生成合成训练数据

NVIDIA RTX AI套件简化AI驱动的应用开发
Mistral AI与NVIDIA推出全新语言模型Mistral NeMo 12B
NVIDIA AI Foundry 为全球企业打造自定义 Llama 3.1 生成式 AI 模型

揭秘NVIDIA AI Workbench 如何助力应用开发
Al大模型机器人
NVIDIA NIM 革命性地改变模型部署,将全球数百万开发者转变为生成式 AI 开发者






 工商网监
工商网监
评论