 使用NVIDIA Clara Holoscan加速多器官渲染
使用NVIDIA Clara Holoscan加速多器官渲染
NVIDIA Clara Holoscan 是医疗设备的人工智能计算平台,它结合了用于低延迟传感器和网络连接的硬件系统、用于数据处理和人工智能的优化库,以及用于运行从嵌入式到边缘到云的流媒体、成像和其他应用程序的核心微服务。
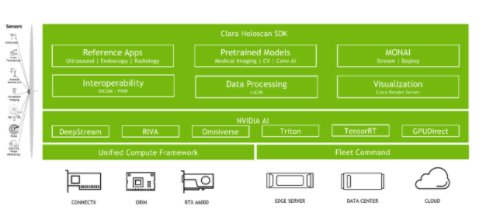
图 1 NVIDIA Clara 全息扫描
NVIDIA Clara Holoscan 将智能仪器与数据中心无缝连接,支持软件定义医疗设备的信号处理、 AI 推理和可视化工作流。用例涵盖放射学、微创手术、机器人手术、患者监控等领域。它是一个完全加速的框架,用于开发实时多模式应用程序,使用优化的微服务容器、无代码设计工具和示例应用程序。
NVIDIA Clara Holoscan 是一种可扩展的体系结构,在数据中心或云中从嵌入式设备和NVIDIA-Certified edge servers扩展到NVIDIA DGX systems。该平台使您能够根据需要在医疗设备中添加尽可能多或尽可能少的计算和输入/输出功能,并与延迟、成本、空间、电源和带宽的需求相平衡。
放射治疗
NVIDIA Clara 全息扫描的一个重要应用案例是放射治疗,在放射治疗中,需要进行图像处理来分割被治疗的器官和肿瘤。此外,单独分割相邻器官有助于识别肿瘤及其体积。它还使医生能够创建一个详细和准确的 3D 地图,可以绘制出辐射束通过其他器官的最佳轨迹,并且影响最小。
通过 3D 模型,放射治疗系统甚至可以实时调整患者解剖结构的变化。手动进行多器官分割非常耗时,但使用人工智能可以大大加快分割速度。图 2 显示了使用 NVIDIA Clara Holoscan 的 3D 多器官分割应用程序的部署架构。
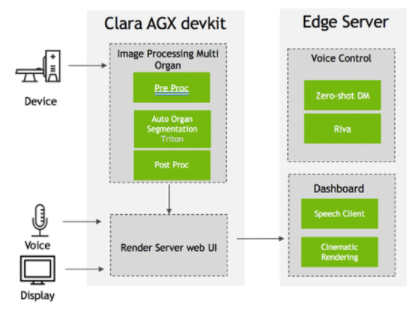
图 2 NVIDIA Clara Holoscan 三维多器官分割部署架构
以下部分介绍如何基于UNETR构建和部署一个基于 transformer 的三维分割模型的三维多器官分割应用程序。
MONAI 部署 UNETR 应用程序
UNEt transformer ( UNETR )模型体系结构的新颖之处在于基于 transformer 的编码器可以学习输入体积的序列表示,并有效地捕获全局多尺度信息。 transformer 编码器通过不同分辨率的跳过连接直接连接到解码器,以计算最终的语义分段输出。
在Multi-Atlas Labeling Beyond the Cranial Vault (BTCV) dataset上测试了 UNETR 模型的有效性,该模型由 30 名受试者组成,受试者进行腹部计算机断层扫描( CT ),其中 13 个器官在范德比尔特大学医学中心临床放射科医生的监督下由译员注释。将多器官分割问题描述为一个单通道输入的 13 类分割任务。
我们使用 MONAI Deploy App SDK 在NVIDIA Clara AGX developer kit上构建和部署 UNETR 模型,该模型结合了高效的 Jetson AGX Xavier 嵌入式 Arm SoC 、强大的 NVIDIA RTX 6000 GPU 和 ConnectX-6 SmartNIC 的 100 GbE 连接。
开发者工具包提供了一个易于使用的平台,用于开发软件定义、支持人工智能的实时医疗设备。 MONAI Deploy App SDK 提供了一个框架和相关工具,用于设计、验证和分析用于医疗保健应用程序的 AI 推理管道的性能。
以下重点介绍了构建和部署 UNETR 应用程序的步骤:
设置您的环境并安装MONAI Deploy App SDK package。
创建UNETR model specific segmentation operator。
通过添加 MONAI App Deploy SDK DICOM 域特定运算符创建应用程序类,并将其与 UNETR 运算符连接。
Package the UNETR app
为了可视化 MONAI 部署应用程序的分割输出,我们使用英伟达 Clara 渲染服务器应用程序容器,可以从 NGC 下载。
渲染服务由三个容器组成:渲染服务器、数据集服务和仪表板。
渲染服务器容器
渲染服务器容器处理数据集的实时流和渲染。
使用以下命令拉动渲染服务器容器:
docker pull nvcr.io/nvidia/clara/renderserver_ng:0.8.1-2108.1
使用以下命令运行渲染服务器容器:
nvidia-docker run -it --rm -d \--name renderserver \--network claranet \-p 2050:2050 \-v `pwd`/input:/app/datasets \nvcr.io/nvidia/clara-renderserver:linux-x86-0.8.1
数据集服务容器
数据集服务容器处理数据集。它目前只支持 MHD 、 RAW 、 JSON 和元文件。
使用以下命令拉入数据集服务容器:
docker pull nvcr.io/nvidia/clara/clara-datasetservice:0.8.1-2108.1
每个数据集所需的文件位于文件夹/datasets下,由 UNETR 应用程序生成。以下是生成的文件列表:
config.meta config_render.json img0066.nii.gz img0066.output.mhd img0066.output.raw
- config . meta– 定义数据集应使用的基本信息和配置。
- config _ render . json– 定义加载时数据集与渲染服务器一起使用的默认渲染设置(灯光、摄影机、传递函数等)。
- img0066 . gz– 从 DICOM 转换的原始图像。
- img0066 . output . mhd-MHD 格式的遮罩图像。这个未经加工的文件包含实际像素。
使用以下命令启动数据集服务容器:
export ARGS_SERVICE_RSDS_PORT=50055 # Port number of Dataset Service export ARGS_SERVICE_RSNG_IP=xxx.xxx.xxx.xxx # IP address of Render Service export ARGS_SERVICE_RSNG_PORT=2050 # Port number of Render Service export ARGS_SERVICE_RSUI_IP=xxx.xxx.xxx.xxx # IP address of Dashboard export ARGS_SERVICE_RSUI_PORT=8080 # Port number of Dashboard docker run -it --rm -d \-v `pwd`:/app/datasets \-p ${ARGS_SERVICE_RSDS_PORT:-50055}:50055 \-e SERVICE_RSNG_IP=${ARGS_SERVICE_RSNG_IP:-renderserver} \-e SERVICE_RSNG_PORT=${ARGS_SERVICE_RSNG_PORT:-2050} \-e SERVICE_RSUI_IP=${ARGS_SERVICE_RSUI_IP:-dashboard} \-e SERVICE_RSUI_PORT=${ARGS_SERVICE_RSUI_PORT:-8080} \--name clara-datasetservice \nvcr.io/clara/clara-datasetservice:0.8.1 _RSNG_IP=xxx.xxx.xxx.xxx # IP address of Render Service
仪表板容器
仪表板容器是一个 web 应用程序和 API 服务器。这些组件是用 JavaScript 编写的,使用 React 和 Node 。 js ,并支持用 Angular 编写的遗留 WebUI 的向后兼容性。
使用以下命令拉动仪表板容器:
docker pull nvcr.io/nvidia/clara/clara-dashboard:0.8.1-2108.1
使用以下命令启动仪表板容器:
docker run -it --rm -d
-p ${ARGS_SERVICE_RSUI_PORT:-8080}:8080
-e SERVICE_RSDS_IP=${ARGS_SERVICE_RSDS_IP:-datasetservice}
-e SERVICE_RSDS_PORT=${ARGS_SERVICE_RSDS_PORT:-50055}
-e SERVICE_RSNG_IP=${ARGS_SERVICE_RSNG_IP:-renderserver}
-e SERVICE_RSNG_PORT=${ARGS_SERVICE_RSNG_PORT:-2050}
-e NODE_ENV=${ARGS_NODE_ENV:-standalone}
--name clara-dashboard
nvcr.io/clara/clara-dashboard:
要启动实时交互流,请从 Render Service 应用程序菜单中的 dataset 列表中选择一项
要上载渲染设置中的更改,请选择数据集名称旁边的更新图标。首次加载数据集时,该图标处于非活动状态,但在对渲染设置进行任何后续更改(例如,更改视图位置、摄影机设置或传递函数设置)后,该图标将启用。更新时,数据集渲染设置将上载到数据集服务数据库。
向 NVIDIA Clara 渲染服务器添加语音命令
您可以使用语音命令和文本查询与英伟达 Clara 渲染服务器进行交互。通过集成 Riva 语音服务器和零快照对话管理器服务器来实现这一点,该服务器可以通过 HTTP 上的 REST API 调用为客户端提供服务。有关更多信息,请参阅NVIDIA Riva Speech Skills。
安装三个容器(仪表板、渲染服务器和数据集服务)后,必须在启用自动语音识别( ASR )和文本到语音( TTS )服务的情况下访问 Riva 服务器。 Zero shot Dialog Manager 服务器应该在边缘服务器上运行(图 2 )。
您可以为实时流交互添加不同的语音命令,如“放大/缩小”和“向左/向右平移”或更复杂的语音命令,如“移除肋骨”
将 Zero-shot Dialog Manager 服务器与 NVIDIA Clara 仪表板集成
要将零炮对话管理器与 NVIDIA Clara 集成,请执行以下步骤:
添加用户界面字段以从用户处获取文本命令。
在仪表板中添加代码,以使用用户文本向 Zero shot Dialog Manager 服务器发送 HTTP GET 请求。 Zero shot GET 请求必须采用以下格式:http://《Zero Shot Server IP》:《PORT》/《Project Name》/process_query?query=《user entered text》
在仪表板中添加代码以处理来自 Zero shot 服务器的响应。
确定特定意图(例如:“放大/缩小”)后,仪表板必须实现请求仪表板后端执行相应操作的方法。仪表板通过调用适当的 gRPC API 到达渲染服务器和数据集服务。
Riva ASR 和 TTS 服务与英伟达 Clara 仪表板的集成
要通过 Riva 添加可用的 ASR 服务,请执行以下步骤:
向仪表板用户界面添加代码以请求麦克风访问。
参考 Riva ASR 示例,实现用户音频输入到仪表板后端的流媒体功能。您可以使用Web Audio API和 Socket 。 IO 。
修改仪表板后端,以便当您从用户界面收到请求时,对 Riva 服务器进行适当的调用并返回响应。这主要涉及导入 Riva proto 文件。
仪表板用户界面从仪表板后端接收到转录的响应后,将其转发到 Zero-shot Dialog Manager 服务器,该服务器返回相应的响应。仪表板执行适当的步骤,并使用 Zero shot Dialog manager 响应调用 Riva TTS ,以便用户界面获得可作为响应播放的音频。
类似地,将 Riva TTS 服务与英伟达 Clara 仪表板集成如下步骤:
在用户界面中实现一种方式,以播放从 Riva TTS 接收到的音频。
向仪表板用户界面添加代码,以将零炮响应文本发送到仪表板后端。
将所有 gRPC 客户端逻辑添加到仪表板后端,以便它可以连接到 Riva TTS 服务器。成功后,将语音响应发送回仪表板用户界面进行播放。
图 5 依次显示了 NVIDIA Clara 仪表板和 Riva 以及 Zero-shot 对话框管理器之间的 API 调用。
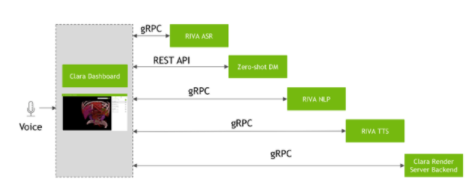
图 5 NVIDIA Clara 仪表板 Riva 和零炮对话框管理器之间的交互
使用 NVIDIA 舰队命令进行部署
NVIDIA 舰队司令部为任何规模的企业带来安全边缘 AI 。通过云,您可以部署和管理 NGC 目录或 NGC P Riva te 注册表中的应用程序,通过无线方式更新系统软件,并通过浏览器和互联网连接远程管理系统。有关更多信息,请参阅Developing Your Application for Fleet Command。
要使用英伟达命令部署 NVIDIA Clara HORSOCAN 应用程序,可以为应用程序创建一个头盔图。 Helm 是一个包管理器,用于在 Kubernetes 中部署容器化应用程序,这与 Debian / RPM 用于 Linux 或 Jar / War 用于基于 Java 的应用程序非常相似。
舵手世界中的一个包称为图表,特定目录树中的文件集合,用于描述一组相关模板。目录名是没有版本控制信息的图表的名称。当图表打包为档案,这些图表目录被打包到一个 TGZ 文件中,其文件名包含其版本,使用 SemVer2 版本控制格式。以下是 NVIDIA Clara 存档名称的示例格式:
clara-renderserver {semVer2}.tgz
可以使用以下命令创建新的舵图:
helm create clara-renderserver
此命令创建 Clara -renderserver 图表目录以及图表中使用的常用文件和目录。具体来说,这是图表目录的树形结构:
|-- Chart.yaml # A YAML file containing information about the chart |-- templates # A directory of templates that, when combined with values ,will generate valid Kubernetes manifest files. | |-- _helpers.tpl | |-- cache-volume-claim.yaml | |-- cache-volume.yaml | |-- deployment.yaml | |-- svc.yaml | |-- volume-claim.yaml | `-- volume.yaml `-- values.yaml # The default configuration values for this chart # A YAML file containing information about the chart
deployment . yaml 文件位于/ templates 目录中,用于定义 Kubernetes 中部署对象的结构:
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ include "clara-renderer.fullname" . }}
labels:
{{ include "clara-renderer.labels" . | indent 4 }}
spec:
replicas: {{ .Values.replicaCount }}
selector:
matchLabels:
app.kubernetes.io/name: {{ include "clara-renderer.name" . }}
app.kubernetes.io/instance: {{ .Release.Name }}
template:
metadata:
[metadata info]
spec:
{{- with .Values.images.pullSecrets }}
imagePullSecrets:
{{- toYaml . | nindent 8 }}
{{- end }}
containers:
- name: ui-{{ .Chart.Name }}
image: "{{ .Values.images.namespace }}/{{ .Values.images.renderui }}:{{ .Values.images.tag }}"
imagePullPolicy: {{ .Values.images.pullPolicy }}
env:
- name: SERVICE_RSDS_IP
value: "0.0.0.0"
- [more env variable assignment]
ports:
- name: "{{ .Values.ui.portName }}"
containerPort: {{ .Values.ui.port }}
hostPort: {{ .Values.ui.hostPort }}
protocol: TCP
- name: renderer-{{ .Chart.Name }}
image: "{{ .Values.images.namespace }}/{{ .Values.images.renderserver }}:{{ .Values.images.tag }}"
imagePullPolicy: {{ .Values.images.pullPolicy }}
ports:
- name: "{{ .Values.rsng.portName }}"
containerPort: {{ .Values.rsng.port }}
protocol: TCP
env:
- name: CUDA_CACHE_PATH
value: "/cache/CudaCache"
- name: OPTIX_CACHE_PATH
value: "/cache/OptixCache"
volumeMounts:
[volume mount information]
- name: dataset-service-{{ .Chart.Name }}
image: "{{ .Values.images.namespace }}/{{ .Values.images.datasetservice }}:{{ .Values.images.tag }}"
imagePullPolicy: {{ .Values.images.pullPolicy }}
env:
- name: DATASET_REPO_PATH
value: "/datasets"
-[dataset env variable assignment]
要验证舵图,请运行以下命令:
helm lint clara-renderserver
接下来,打包舵图:
helm package clara-renderserver
要使用 NVIDIA Fleet 命令部署,请根据您创建的头盔图表创建应用程序:

图 6 在 Fleet 命令中添加应用程序
下一步是为应用程序添加部署:
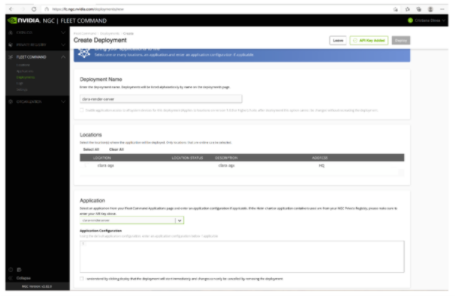
图 7 在舰队司令部中创建部署
创建部署时,应用程序将部署在 Fleet 命令中的配对边缘站点上。要更改应用程序的配置,请使用 Helm upgrade 命令。
某些系统更新可能需要重新启动。如果需要重新启动, Fleet 命令堆栈会在系统运行后自动重新启动应用程序。您的 NVIDIA Clara Holoscan 应用程序应该能够通过系统更新或系统重新启动进行正常恢复和持久化。
关于作者
Cristiana Dinea 是 NVIDIA 的应用工程师,她专注于基于 NVIDIA Clara Guardian 为智能医院开发应用程序。
Yaniv Lazmy 是 NVIDIA 医疗团队的技术产品经理,专注于医疗设备的加速计算和连接解决方案。在加入 NVIDIA 之前, Yaniv 是 NeuWave Medical 和 Johnson and Johnson 的嵌入式系统工程师。
Raghav Mani 是 NVIDIA 医疗 AI 的产品经理,专注于为医疗和生命科学领域的医疗成像和 NLP 研究人员以及智能医院应用程序的开发人员构建工具。Ming Qin 是 NVIDIA 医疗团队的独立贡献者,专注于开发 AI 推理应用框架和平台,将 AI 引入医疗成像工作流程。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
5013浏览量
103243 -
服务器
+关注
关注
12文章
9231浏览量
85621 -
应用程序
+关注
关注
37文章
3283浏览量
57749
发布评论请先 登录
相关推荐
《CST Studio Suite 2024 GPU加速计算指南》
NVIDIA加速计算如何推动医疗健康
NVIDIA AI正加速推进药物研发
NVIDIA加速AI在日本各行各业的应用
日本企业借助NVIDIA产品加速AI创新
在NVIDIA Holoscan SDK中使用OpenCV构建零拷贝AI传感器处理管线

HPE 携手 NVIDIA 推出 NVIDIA AI Computing by HPE,加速生成式 AI 变革
NVIDIA 通过 Holoscan 为 NVIDIA IGX 提供企业软件支持
NVIDIA 通过 Holoscan 为 NVIDIA IGX 提供企业软件支持,实现边缘实时医疗、工业和科学 AI 应用

MathWorks 与 NVIDIA 联手加速医疗技术领域中软件定义工作流的开发
MathWorks与NVIDIA携手革新医疗技术工作流
MathWorks联手NVIDIA加速医疗技术领域中软件定义工作流的开发






 工商网监
工商网监
评论