 NVIDIA GPUs上命令缓冲区的应用实践
NVIDIA GPUs上命令缓冲区的应用实践
这篇文章介绍了 NVIDIA GPUs 上命令缓冲区的最佳实践。要在应用程序中获得高且一致的帧速率,请参阅所有高级 API 性能提示。
命令缓冲区是从 CPU 发送要在 GPU 上执行的命令的主要机制。通过遵循本文列出的最佳实践,您可以通过最大化并行性、避免瓶颈和减少 GPU 上的空闲时间,在 CPU 和 GPU 上实现性能提升。
接受您负责实现和控制 GPU / CPU 并行性的事实。
向命令列表提交工作不会启动 GPU 上的任何工作。
对ExecuteCommandList的调用最终在 GPU 上开始工作。
在多个线程和内核上并行并均匀地将工作记录到多个命令列表中。
录制命令是一项 CPU 密集型操作,没有驱动程序线程来拯救。
命令列表不是自由线程,因此并行工作提交意味着提交多个命令列表。
请注意,设置和重置命令列表会带来成本。
为了高效地提交并行工作,您仍然需要合理数量的命令列表。
围栏出于各种原因(多个命令队列、拾取查询结果等)强制拆分命令列表。
尝试将目标设定为每帧 5-10 次ExecuteCommandList调用,并进行足够的 GPU 工作,以隐藏每次ExecuteCommandList调用的操作系统调度开销。
在上一次ExecuteCommandList调用之后,操作系统需要 50-80 微秒来安排命令列表。如果调用中的命令列表执行速度快于此,则硬件队列中存在气泡。
使用GPUView检查气泡。
您可以将 3D 队列上的图形或计算工作与专用异步计算队列上的计算工作重叠。
请记住,即使对于理论上可以与其他图形或计算任务并行运行的计算任务, GPU 上并行工作的实际调度细节也可能不会产生期望的结果。
注意哪些异步计算和图形工作负载可以一起调度。使用围栏将正确的工作负载配对。
使用ExecuteIndirect灵活性最大限度地将 CPU 工作卸载到 GPU 并减少 CPU – GPU 同步点。
请使用ExecuteIndirect将场景消隐系统移植到 GPU 。
使用ExecuteIndirect计数缓冲区来控制命令的数量,而不是发出最大数量的命令并单独预测未使用的命令。
NVIDIA 在ExecuteIndirect的Vulkan下为ExecuteIndirect提供附加功能
不推荐
帧描述符堆中的 CBV / SRV / UAV 描述符或 2K 采样器不要超过 100 万个。
不要阻止ExecuteCommandList呼叫。
ExecuteCommandList打电话可能会很贵。同时,可以在其他线程上记录新命令。
每个命令队列都可以使用自己的线程来提交ExecuteCommandList。
不要只在几个命令列表中记录所有内容或大型场景部分。这限制了您充分使用所有 CPU 内核的能力。
此外,构建几个大的命令列表意味着您可能会发现很难让 GPU 保持空闲状态。
不要只在录制完所有内容后才提交。您可能会浪费使 GPU 与其他命令列表的录制并行工作的机会。
不要期望大量的列表重用。
在对象可见性等方面,每帧通常有许多更改。
后处理可能是一个例外。
不要经常混合使用绘图、分派和复制命令。
尝试将所有绘制命令组合在一起,并将命令分派到一起,依此类推。
在同一队列上频繁混合不同类型的工作可能会导致管道排水。
不要创建太多线程或太多命令列表。
太多的线程超额订阅 CPU 资源,而太多的命令列表可能会积累太多的开销。
关于作者
Wessam Bahnassi 在 3D 引擎设计和优化方面有 20 年的经验。他最新发布的游戏包括《蝙蝠侠:阿卡姆骑士》和他自己的 120-FPS PSVR 太空射击游戏超空。他是 ShaderX / GPU Pro / GPU Zen 系列书籍的撰稿人和章节编辑。他目前在 NVIDIA 的工作包括进行优化,并为该公司的几个很酷的研究项目做出贡献。
审核编辑:郭婷
-
cpu
+关注
关注
68文章
10863浏览量
211782 -
NVIDIA
+关注
关注
14文章
4986浏览量
103066
发布评论请先 登录
相关推荐
AMD Zen 4处理器悄然禁用循环缓冲区
分享一个嵌入式通用FIFO环形缓冲区实现库

单片机中的几种环形缓冲区的分析和实现

ESP8266是否可以添加AT命令并使接收缓冲区大小可调?
ESP8266有双缓冲区吗?
创建DMA通道时,能否将DMA缓冲区的大小指定为8字节,并将DMA缓冲区的编号指定为1?
stm32野火开发板上做USB通信,PC端USB的缓冲区和串口缓冲区的大小是多少?

实现稳健的微控制器到FPGA SPI接口: 双缓冲区!
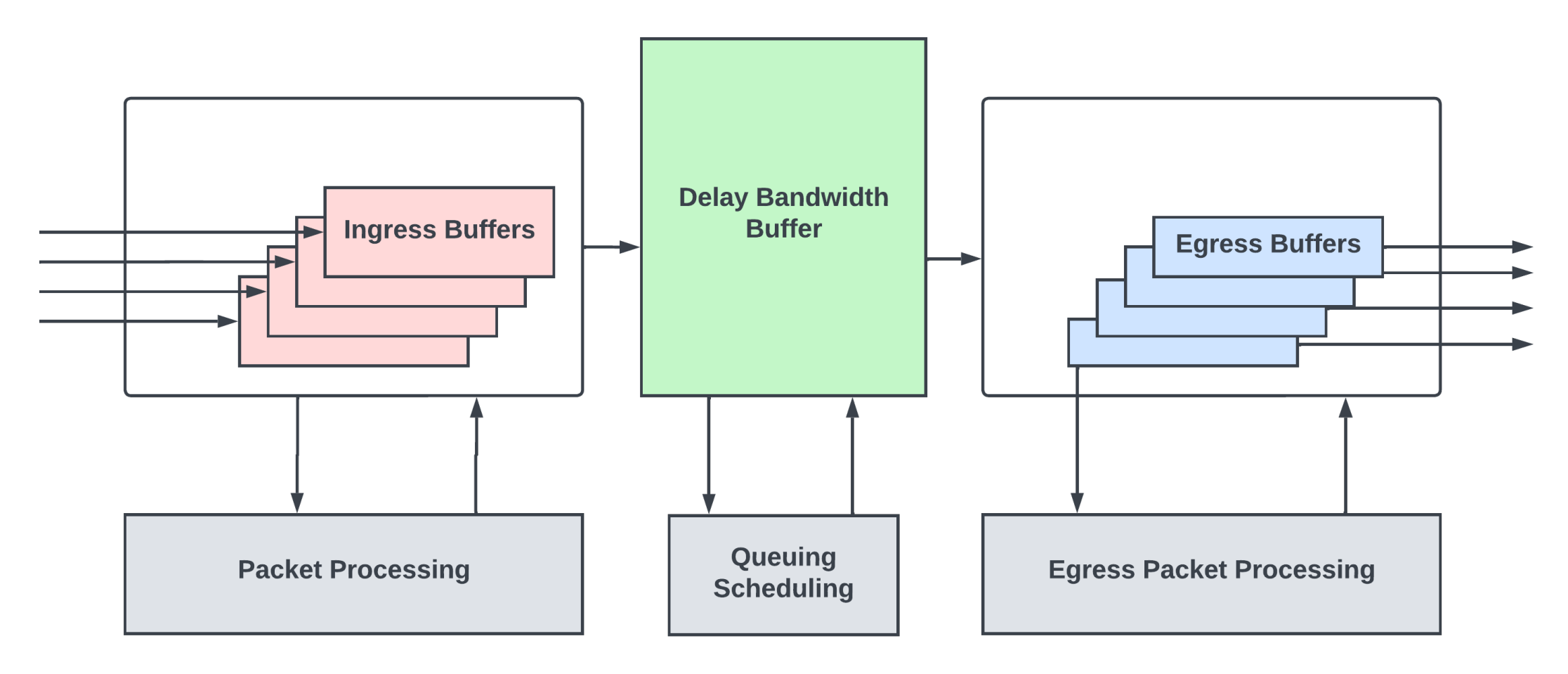
交换机与路由器缓冲区:寻找完美大小





 工商网监
工商网监
评论