 世界最小嵌入式AI超级计算机Jetson Xavier NX
世界最小嵌入式AI超级计算机Jetson Xavier NX
NVIDIA 发布了Jetson Xavier NX,这是世界上最小、最先进的嵌入式 AI 超级计算机,用于自主机器人和边缘计算设备。Jetson Xavier NX 能够在紧凑的 70x45mm 外形尺寸中部署服务器级性能,在 15W 功率下提供高达 21 TOPS 的计算,或在 10W 下提供高达 14 TOPS 的计算。Jetson Xavier NX 模块(图 1)与 Jetson Nano 引脚兼容,并基于 NVIDIA 的 Xavier SoC 的低功耗版本,该版本在边缘 SoC 中领先于最近的MLPerf Inference 0.5结果,为部署要求苛刻的基于 AI 的边缘的工作负载可能会受到尺寸、重量、功率和成本等因素的限制。
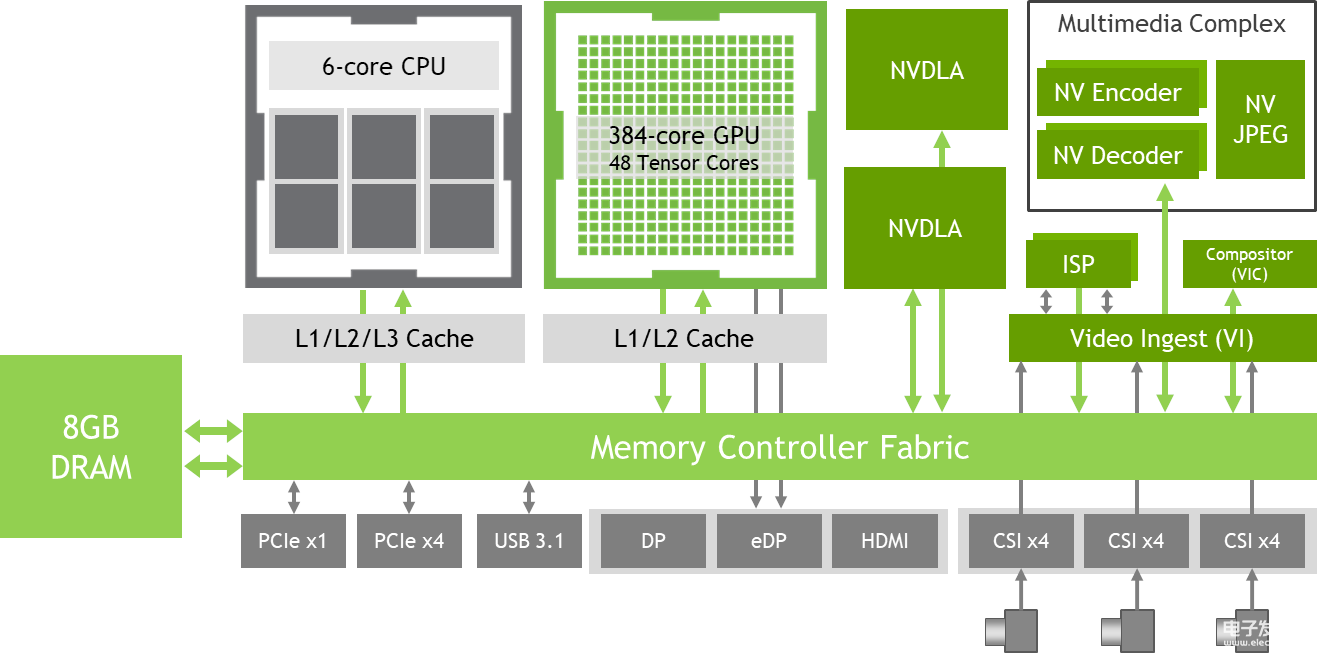
图 2:Jetson Xavier NX 处理器引擎的框图,包括高速 I/O 和内存结构。
如图 2 所示,Jetson Xavier NX 包括一个集成的 384 核 NVIDIA Volta GPU,具有 48 个 Tensor 核心、6 核 NVIDIA Carmel ARMv8.2 64 位 CPU、8GB 128 位 LPDDR4x、双 NVIDIA 深度学习加速器 (NVDLA)引擎、4K 视频编码器和解码器、用于多达 6 个同步高分辨率传感器流的专用摄像头摄取、PCIe Gen 3 扩展、双 DisplayPort/HDMI 4K 显示器、USB 3.1 和 GPIO,包括 SPI、I2C、I2S、CAN 总线和UART。请参阅下表 1,了解功能列表和Jetson Xavier NX 模块数据表,了解完整规格。共享内存结构允许处理器自由共享内存,而不会产生额外的内存副本(称为 ZeroCopy),从而有效地提高了系统的带宽利用率和吞吐量。

表 1:Jetson Xavier NX 计算模块特性和功能
* CPU 最大工作频率在 4/6 核模式下为 1400MHz,或在双核模式下为 1900MHz
† 最大并发流数达到总吞吐量。支持的视频编解码器:H.265、H.264、VP9有关特定编解码器和配置文件规范,
请参阅Jetson Xavier NX 模块数据表。
†† MIPI CSI-2,D-PHY V1.2(每通道 2.5Gb/s,总计高达 30Gbps)。
‡ PCIe 1×1 仅支持根端口,1×1/2/4 支持根端口或端点模式
^ 工作温度范围,Xavier SoC 结温 (Tj)
Jetson Xavier NX 得到 NVIDIA 完整的 CUDA-X 软件堆栈和用于 AI 开发的JetPack SDK的支持,除了实时计算机视觉、加速图形和丰富的多媒体应用程序之外,还能在多个高分辨率传感器流上同时运行流行的机器学习框架和复杂的 DNN在完整的桌面 Linux 环境中。Jetson 与 NVIDIA 的 AI 加速计算平台的兼容性使得开发和云与边缘之间的无缝迁移变得容易。
Jetson Xavier NX 模块将于 2020 年 3 月以 399 美元的批量供货,嵌入式设计人员可以参考可供下载的设计资料,包括Jetson Xavier NX 设计指南,为 Jetson Xavier NX 模块创建生产设备和系统。与 Jetson Nano 的引脚兼容性允许共享设计和对 Jetson Xavier NX 的直接技术插入升级。Jetson 生态系统的硬件设计合作伙伴除了提供现成的载体、传感器和配件外,还能够提供定制设计服务和系统集成。
软件开发人员现在可以开始为 Jetson Xavier NX 构建 AI 应用程序,方法是使用 Jetson AGX Xavier 开发工具包,并将设备配置补丁应用到 JetPack,使设备表现得像 Jetson Xavier NX。除了设置整个系统的核心时钟频率和电压外,它还将通过软件改变可用的 CPU 和 GPU 核心的数量。该补丁是完全可逆的,可用于在硬件可用之前估算 Jetson Xavier NX 的性能。
Jetson Xavier NX 定义了 10 和 15W 的默认功率模式,根据活动模式实现 14 到 21 TOPS 的峰值性能。用于管理电源配置文件的 nvpmodel 工具调整 CPU、GPU、内存控制器和其他 SoC 时钟的最大时钟频率,以及在线 CPU 集群的数量——这些设置显示在表 2 中,用于预定义的 10W 和Jetson Xavier NX 的 15W 模式。CPU 布置在三个集群中,每个集群有 2 个内核,在 4/6 核模式下的最高工作频率为 1400MHz,在双核模式下最高可达 1900MHz,适用于可能需要更多单线程与多线程的应用程序表现。
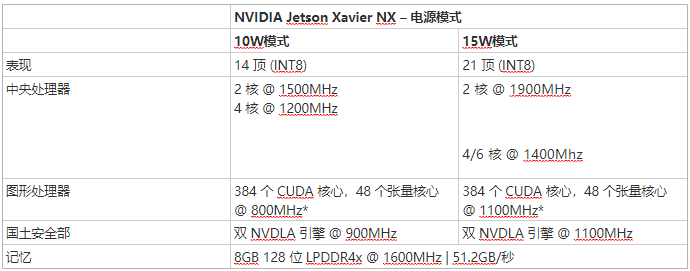
表 2:Jetson Xavier NX 在 10W 和 15W 功率模式下的最大工作频率和核心配置。
* 使用 NVDLA 时,GPU 最高工作频率为 600MHz(10W 模式)和 1000MHz(15W 模式)
根据工作负载,动态电压和频率缩放 (DVFS) 调节器在运行时将频率缩放到活动 nvpmodel 定义的最大限制,因此在空闲时降低功耗并取决于处理器利用率。nvpmodel 工具还可以根据应用要求和 TDP 轻松创建和自定义新的电源模式。可以编辑电源配置文件并将其添加到 /etc/nvpmodel.conf 配置文件中,并且在 Ubuntu 状态栏中添加了一个 GUI 小部件,以便在运行时轻松管理和切换电源模式。
深度学习推理基准
NVIDIA 还宣布,它在MLPerf Inference 0.5基准测试的 5 个类别中的 4 个类别中夺冠,其中 Jetson AGX Xavier 是边缘计算 SoC 的领导者,包括所有基于视觉的任务:使用 Mobilenet 进行图像分类和ResNet-50,以及使用 SSD-Mobilenet 和 SSD-ResNet 进行对象检测。在 MLPerf 定义的所有五项推理测试中,NVIDIA GPU 是十种竞争芯片架构中唯一提交结果的一种。
为了参考 Jetson 系列成员之间的可扩展性,我们还在流行的 DNN 模型上测量了 Jetson Nano、Jetson TX2、Jetson Xavier NX 和 Jetson AGX Xavier 的推理性能,用于图像分类、对象检测、姿势估计、分割等。这些结果(如下图 3 所示)是使用 JetPack 和 NVIDIA 的 TensorRT 推理加速器库运行的,该库可优化网络以实现实时性能,这些网络在 TensorFlow、PyTorch、Caffe、MXNet 等流行的机器学习框架中进行了训练。
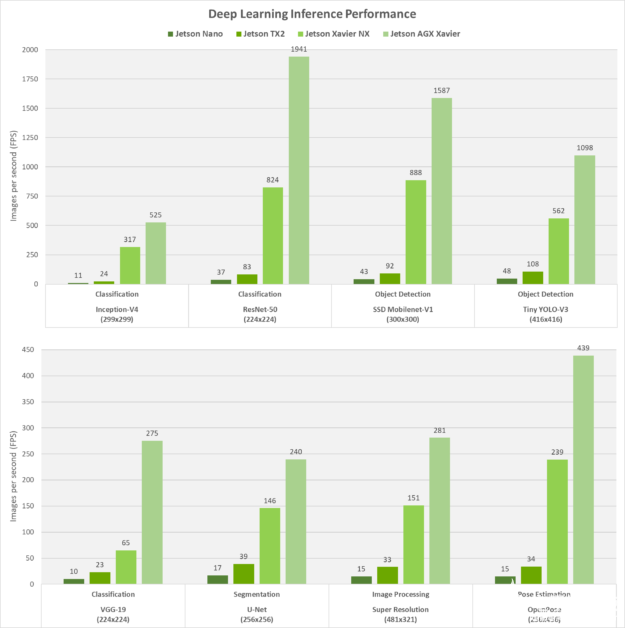
图 3. Jetson 系列中使用 TensorRT 的各种基于视觉的 DNN 模型的推理性能。
Jetson Xavier NX 的性能比 Jetson TX2 高出多达 10 倍,功率相同,占用空间减少 25%。在这些基准测试中,每个平台都以最高性能运行(Jetson AGX Xavier 为 MAX-N 模式,Xavier NX 和 TX2 为 15W,Nano 为 10W)。最大吞吐量是在批处理大小不超过 16 毫秒延迟阈值的情况下获得的,否则对于平台超过此延迟阈值的网络,批处理大小为 1。这种方法在实时应用程序的确定性低延迟要求和多流用例场景的最大性能之间提供了平衡。
在 Jetson Xavier NX 和 Jetson AGX Xavier 上,NVDLA 引擎和 GPU 以 INT8 精度同时运行,而在 Jetson Nano 和 Jetson TX2 上,GPU 以 FP16 精度运行。Jetson Xavier NX 中带有 Tensor Cores 的 Volta 架构 GPU 能够进行高达 12.3 TOPS 的计算,而该模块的 DLA 引擎每个可产生高达 4.5 TOPS。
除了使用 TensorRT 运行神经网络之外,ML 框架还可以通过 CUDA 和 cuDNN 本地安装在 Jetson 上,包括 TensorFlow、PyTorch、Caffe/Caffe2、MXNet、Keras 等。除了 AWS Greengrass 等物联网框架和 Docker 和 Kubernetes 等容器引擎之外, Jetson Zoo还包括预构建的安装程序和构建说明。
Jetson Xavier NX 为部署下一代自主系统和智能边缘设备开辟了新的机会,这些设备需要高性能 AI 和复杂的 DNN 在小尺寸、低功耗的足迹中——想想移动机器人、无人机、智能相机、便携式医疗设备、嵌入式物联网系统等等。支持 CUDA-X 的 NVIDIA JetPack SDK 提供了完整的工具来开发尖端的 AI 解决方案,并以世界领先的性能在云和边缘之间扩展您的应用程序。
关于作者
Dustin 是 NVIDIA Jetson 团队的一名开发人员推广员。Dustin 拥有机器人技术和嵌入式系统方面的背景,喜欢在社区中提供帮助并与 Jetson 合作开展项目。
审核编辑:郭婷
-
机器人
+关注
关注
211文章
28444浏览量
207197 -
AI
+关注
关注
87文章
30944浏览量
269185 -
无人机
+关注
关注
230文章
10448浏览量
180558 -
嵌入式AI
+关注
关注
0文章
34浏览量
834
发布评论请先 登录
相关推荐
NVIDIA发布高性价比生成式AI超级计算机
NVIDIA 推出高性价比的生成式 AI 超级计算机

丹麦推出首台AI超级计算机Gefion
NVIDIA助力丹麦发布首台AI超级计算机
ARMxy嵌入式计算机在机器视觉中的卓越表现

ARMxy ARM嵌入式计算机支持Ubuntu OS快速部署AIoT解决方案

ARMxy ARM嵌入式计算机搭载 1 TOPS NPU支持深度学习
如何选择嵌入式主板或单板计算机

富士通使用富岳超级计算机训练LLM
微软和OpenAI计划投资1000亿美元建造“星际之门”AI超级计算机
人形机器人主板:jetson orin nx核心模块与SOM-7583核心模块结合在一块主板上

诺和诺德基金会将联手英伟达打造丹麦AI超级计算机
NVIDIA Jetson为嵌入式计算领域探索AI可能







 工商网监
工商网监
评论