 NVIDIA Jetson AGX Xavier应用在AI和
NVIDIA Jetson AGX Xavier应用在AI和
面向 AI 开发人员的全球终极嵌入式解决方案JetsonAGXXavier现已作为 NVIDIA 的独立生产模块发货。英伟达 AGX 系统的成员对于自主机器,Jetson AGX Xavier 非常适合将先进的 AI 和计算机视觉部署到边缘,使现场机器人平台具有工作站级性能,并能够在不依赖人工干预和云连接的情况下完全自主运行。由 Jetson AGX Xavier 提供支持的智能机器可以自由地在其环境中进行交互和安全导航,不受复杂地形和动态障碍物的阻碍,完全自主地完成现实世界的任务。这包括需要高级实时感知和推理才能执行的包裹递送和工业检查。作为世界上第一台专为机器人和边缘计算设计的计算机,Jetson AGX Xavier 的高性能可以处理视觉里程计、传感器融合、定位和映射,障碍物检测和对下一代机器人至关重要的路径规划算法。图 1 显示了现在全球可用的生产计算模块。开发人员现在可以开始批量部署新的自主机器。
最新一代 NVIDIA 业界领先的Jetson AGX系列嵌入式 Linux 高性能计算机,Jetson AGX Xavier 提供 GPU 工作站级性能,具有无与伦比的 32 TeraOPS (TOPS) 峰值计算和 750Gbps 的高速 I/O,体积小巧100x87mm 外形尺寸。用户可以根据应用需要配置 10W、15W 和 30W 的工作模式。Jetson AGX Xavier 为可部署到边缘的计算密度、能源效率和 AI 推理功能树立了新的标杆,使具有端到端自主能力的下一级智能机器成为可能。
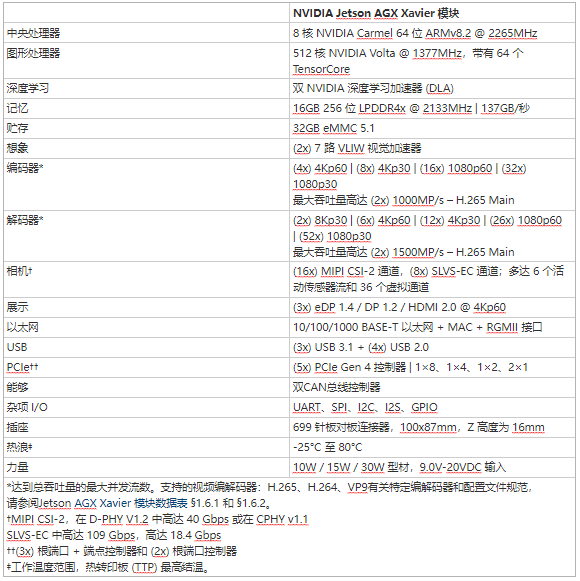
Jetson 使用深度学习和计算机视觉为世界上许多最先进的机器人和自主机器背后的 AI 提供动力,同时专注于性能、效率和可编程性。Jetson AGX Xavier,如图 2 所示,由超过 90 亿个晶体管组成,基于有史以来最复杂的片上系统 (SoC)。该平台包含一个集成的 512 核 NVIDIA Volta GPU,包括 64 个张量核心、8 核 NVIDIA Carmel ARMv8.2 64 位 CPU、16GB 256 位 LPDDR4x、双 NVIDIA深度学习加速器(DLA) 引擎、NVIDIA Vision Accelerator 引擎、高清视频编解码器、128Gbps 的专用摄像头摄取和 16 通道 PCIe Gen 4 扩展。256 位接口上的内存带宽为 137GB/s,而 DLA 引擎卸载了深度神经网络 (DNN) 的推理。NVIDIA 用于 Jetson AGX Xavier 的 JetPack SDK 4.1.1 包括 CUDA 10.0、cuDNN 7.3 和 TensorRT 5.0,提供完整的 AI 软件堆栈。
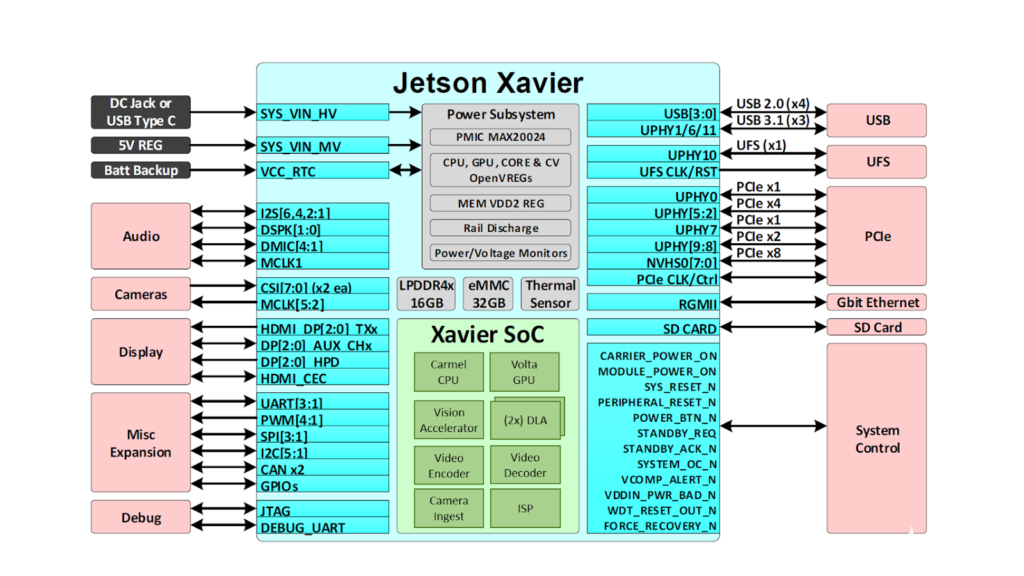
图 2. Jetson AGX Xavier 提供一组丰富的高速 I/O
这使开发人员能够在机器人、智能视频分析、医疗仪器、嵌入式物联网边缘设备等应用中部署加速 AI。与其前身 Jetson TX1 和 TX2 一样,Jetson AGX Xavier 使用系统级模块 (SoM) 范例。所有处理都包含在计算模块上,高速 I/O 位于通过高密度板对板连接器提供的分线载体或外壳上。以这种方式在模块上封装功能使开发人员可以轻松地将 Jetson Xavier 集成到他们自己的设计中。NVIDIA 发布了全面的文档和参考设计文件,可供嵌入式设计人员下载,以使用 Jetson AGX Xavier 创建自己的设备和平台。请务必咨询JetsonAGXXavier 模块数据表和JetsonAGXXavier OEM 产品设计指南,了解表 1 中列出的全部产品功能,以及机电规格、模块引脚排列、电源排序和信号路由指南。
Jetson AGX Xavier 包括超过 750Gbps 的高速 I/O,为流式传感器和高速外围设备提供了非凡的带宽。它是首批支持 PCIe Gen 4 的嵌入式设备之一,在五个 PCIe Gen 4 控制器上提供 16 个通道,其中三个可以在根端口或端点模式下运行。16 个 MIPI CSI-2 通道可连接到四个 4 通道摄像头、六个 2 通道摄像头、六个 1 通道摄像头或这些配置的组合,最多六个摄像头,36 个虚拟通道允许同时连接更多摄像头使用流聚合。其他高速 I/O 包括三个 USB 3.1 端口、SLVS-EC、UFS 和用于千兆以太网的 RGMII。开发者现在可以访问 NVIDIA 的JetPack 4.1.1 开发者预览版Jetson AGX Xavier 的软件,列于表 2。开发者预览版包括 Linux For Tegra (L4T) R31.1 板级支持包 (BSP),支持 Linux 内核 4.9 和目标上的 Ubuntu 18.04。在主机 PC 端,JetPack 4.1.1 支持 Ubuntu 16.04 和 Ubuntu 18.04。
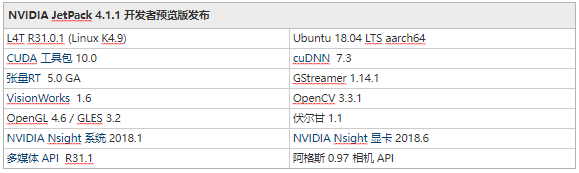
JetPack 4.1.1 开发人员预览版允许开发人员立即开始使用 Jetson AGX Xavier 对产品和应用程序进行原型设计,为生产部署做准备。NVIDIA 将继续通过额外的功能增强和性能优化来改进 JetPack。请阅读发行说明以了解此版本的亮点和软件状态。
伏特显卡
Jetson AGX Xavier 集成 Volta GPU,如图 3 所示,提供 512 个 CUDA 内核和 64 个 Tensor 内核,可实现高达 11 TFLOPS FP16 或 22 TOPS 的 INT8 计算,最大时钟频率为 1.37GHz。它支持计算能力为 sm_72 的 CUDA 10。GPU 包括 8 个 Volta 流式多处理器 (SM),每个 Volta SM 有 64 个 CUDA 核心和 8 个张量核心。每个 Volta SM 都包含一个 128KB L1 缓存,比前几代产品大 8 倍。SM 共享一个 512KB L2 缓存,提供比前几代快 4 倍的访问速度。
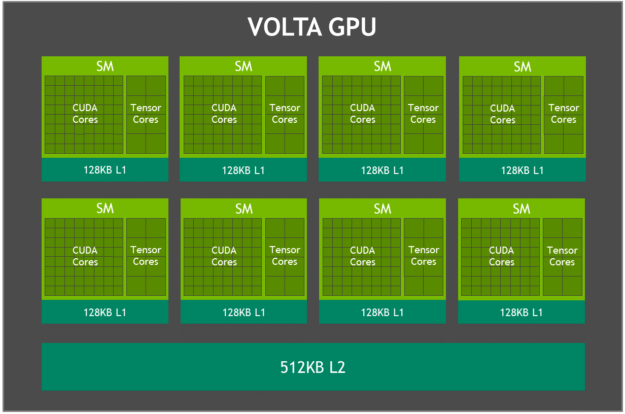
图 3. Jetson AGX Xavier Volta GPU 框图
每个 SM 由 4 个独立的处理块组成,称为 SMP(流式多处理器分区),每个处理块都包括自己的 L0 指令缓存、warp 调度程序、调度单元和寄存器文件,以及 CUDA 核心和张量核心。每个 SM 的 SMP 数量是 Pascal 的两倍,Volta SM 具有改进的并发性,并支持更多的线程、warp 和运行中的线程块。
张量核心
NVIDIA 张量核心是可编程的融合矩阵乘法和累加单元,可与 CUDA 核心同时执行。张量核心实现了新的浮点 HMMA(半精度矩阵乘法和累加)和 IMMA(整数矩阵乘法和累加)指令,用于加速密集线性代数计算、信号处理和深度学习推理。
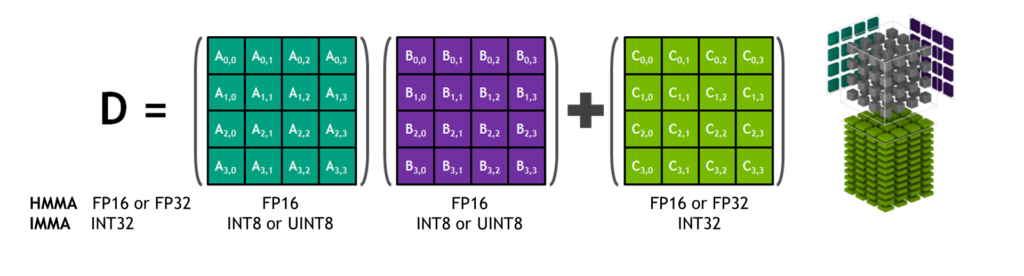
图 4. Tensor Core HMMA/IMMA 4x4x4 矩阵乘法和累加
矩阵乘法输入A和B是 HMMA 指令的 FP16 矩阵,而累加矩阵C和D可以是 FP16 或 FP32 矩阵。对于 IMMA,矩阵乘法输入A是有符号或无符号 INT8 或 INT16 矩阵,B是有符号或无符号 INT8 矩阵,C和D累加器矩阵都是有符号 INT32。因此,精度和计算范围足以避免内部累加期间的上溢和下溢情况。
包括 cuBLAS、cuDNN 和 TensorRT 在内的 NVIDIA 库已更新为在内部使用 HMMA 和 IMMA,使程序员能够轻松利用 Tensor Core 固有的性能提升。用户还可以通过 CUDA 10 中包含的 wmma 命名空间和 mma.h 标头中公开的新 API 直接在 warp 级别访问 Tensor Core 操作。warp 级接口映射 16×16、32×8 和 8×32 大小每个扭曲的所有 32 个线程的矩阵。
深度学习加速器
Jetson AGX Xavier 具有两个 NVIDIA深度学习加速器(DLA) 引擎,如图 5 所示,可卸载固定功能卷积神经网络 (CNN) 的推理。这些引擎提高了能源效率并释放了 GPU 来运行用户实现的更复杂的网络和动态任务。NVIDIA DLA 硬件架构是开源的,可从NVDLA.org 获得。每个 DLA 具有高达 5 TOPS INT8 或 2.5 TFLOPS FP16 的性能,功耗仅为 0.5-1.5W。DLA 支持加速 CNN 层,例如卷积、反卷积、激活函数、最小/最大/均值池、局部响应归一化和全连接层。
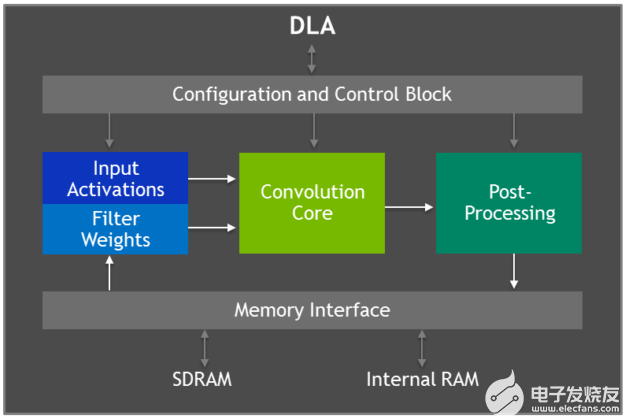
图 5. 深度学习加速器 (DLA) 架构框图
DLA 硬件由以下组件组成:
Convolution Core – 优化的高性能卷积引擎。
单数据处理器——用于激活功能的单点查找引擎。
平面数据处理器——用于池化的平面平均引擎。
通道数据处理器——用于高级标准化功能的多通道平均引擎。
专用内存和数据重塑引擎——用于张量重塑和复制操作的内存到内存转换加速。
开发人员使用 TensorRT 5.0 对 DLA 引擎进行编程,以在网络上执行推理,包括对 AlexNet、GoogleNet 和 ResNet-50 的支持。对于使用 DLA 不支持的层配置的网络,TensorRT 为无法在 DLA 上运行的层提供 GPU 回退。JetPack 4.0 开发者预览版最初将 DLA 精度限制为 FP16 模式,未来 JetPack 版本中将提供 INT8 精度和更高的 DLA 性能。
TensorRT 5.0 将以下 API 添加到其 IBuilder 接口以启用 DLA:
setDeviceType()以及setDefaultDeviceType()默认选择 GPU、DLA_0 或 DLA_1 来执行特定层或网络中的所有层。
canRunOnDLA()检查层是否可以按照配置在 DLA 上运行。
getMaxDLABatchSize()用于检索 DLA 可以支持的最大批量大小。
allowGPUFallback()使 GPU 能够执行 DLA 不支持的层。
请参阅TensorRT 5.0 开发人员指南的第 6 章,了解支持的层配置的完整列表以及在 TensorRT 中使用 DLA 的代码示例。
深度学习推理基准
我们已经发布了 Jetson AGX Xavier 在常见 DNN(例如 ResNet、GoogleNet 和 VGG 的变体)上的深度学习推理基准测试结果。我们在 Jetson AGX Xavier 的 GPU 和 DLA 引擎上使用带有 TensorRT 5.0 的 JetPack 4.1.1 开发者预览版为 Jetson AGX Xavier 运行这些基准测试。GPU 和两个 DLA 分别以 INT8 和 FP16 精度同时运行相同的网络架构,并报告每种配置的总体性能。GPU 和 DLA 可以在实际用例中同时运行不同的网络或网络模型,并行或在处理管道中提供独特的功能。在 TensorRT 中使用 INT8 与完整的 FP32 精度会导致精度损失 1% 或更少。
首先,让我们考虑 ResNet-18 FCN (Fully Convolutional Network) 的结果,这是一个用于语义分割的 2048×1024 分辨率的全高清模型。分割为自由空间检测和占用映射等任务提供每像素分类,并代表由自主机器计算的用于感知、路径规划和导航的深度学习工作负载。图 6 显示了在 Jetson AGX Xavier 与 Jetson TX2 上运行 ResNet-18 FCN 的测量吞吐量。
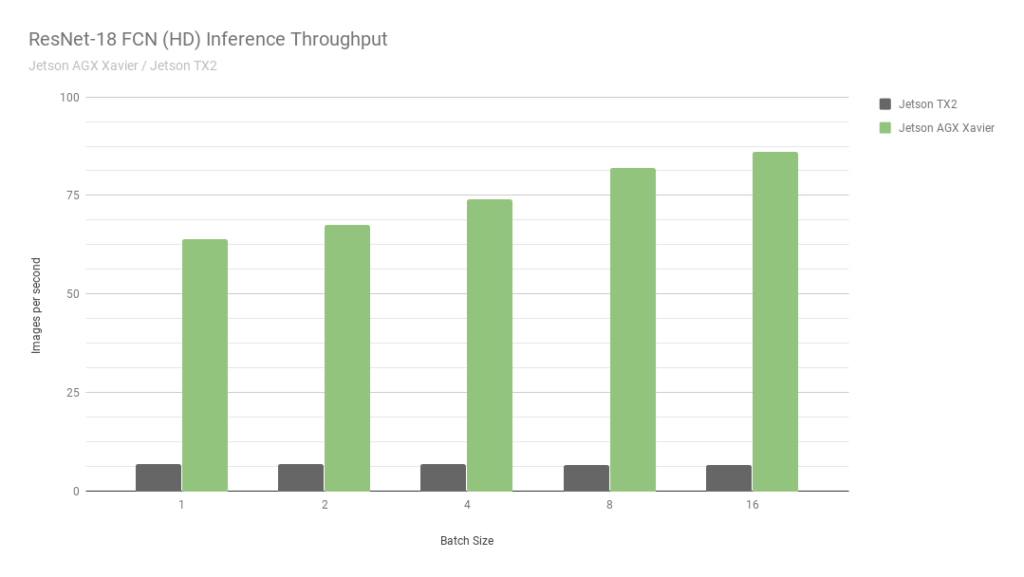
图 6. Jetson AGX Xavier 和 Jetson TX2 的 ResNet-18 FCN 推理吞吐量
与 Jetson TX2 相比,Jetson AGX Xavier 目前在 ResNet-18 FCN 推理中的性能高达 13 倍。NVIDIA 将继续在 JetPack 中发布软件优化和功能增强,随着时间的推移将进一步提高性能和功率特性。请注意,基准结果的完整列表报告了 Jetson AGX Xavier 的 ResNet-18 FCN 的性能,批次大小为 32,但是在图 7 中,我们仅绘制了 16 的批次大小,因为 Jetson TX2 能够运行 ResNet -18 FCN,最大批量为 16。
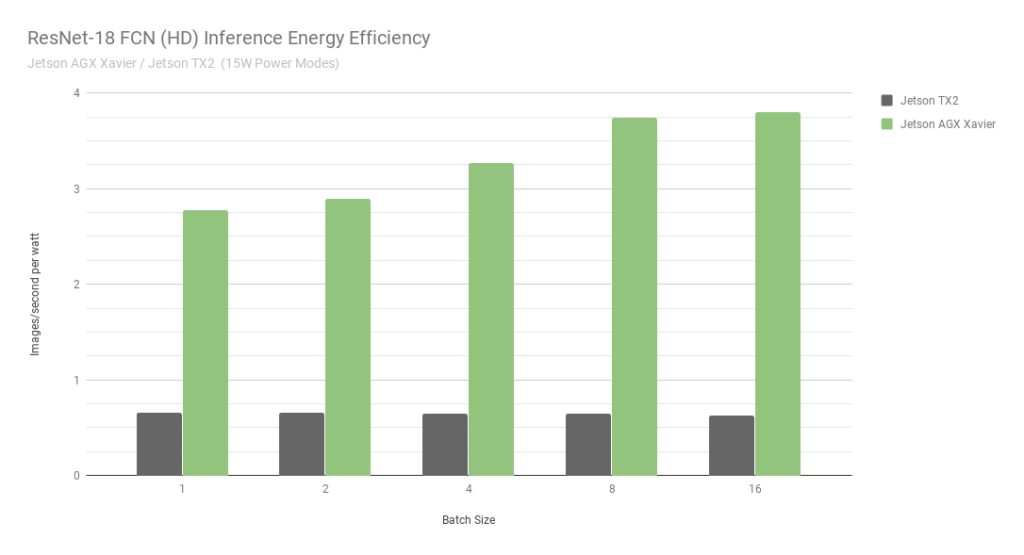
图 7. ResNet-18 FCN 推理 Jetson AGX Xavier 和 Jetson TX2 的能效
在考虑使用每秒每瓦特处理图像的能效时,Jetson AGX Xavier 目前在 ResNet-18 FCN 上的能效比 Jetson TX2 高 6 倍。我们通过使用板载 INA 电压和电流监视器测量总模块功耗来计算效率,包括 CPU、GPU、DLA、内存、其他 SoC 电源、I/O 和所有轨上的稳压器效率损失。两台 Jetson 均在 15W 功率模式下运行。Jetson AGX Xavier 和 JetPack 附带 10W、15W 和 30W 的可配置预设功率配置文件,可在运行时使用 nvpmodel 电源管理工具进行切换。用户还可以使用不同的时钟和 DVFS(动态电压和频率缩放)调节器设置来定义自己的自定义配置文件,这些配置文件已经过定制,以实现单个应用程序的最佳性能。
接下来,让我们比较 Jetson AGX Xavier 基准在图像识别网络 ResNet-50 和 VGG19 上的批量大小 1 到 128 与 Jetson TX2。这些模型对分辨率为 224×224 的图像块进行分类,并经常用作各种对象检测网络中的编码器主干。在较低分辨率下使用 8 或更高的批大小可用于近似在更高分辨率下批大小为 1 的性能和延迟。机器人平台和自主机器通常包含多个相机和传感器,这些相机和传感器可以进行批处理以提高性能,此外还可以执行感兴趣区域 (ROI) 的检测,然后分批对 ROI 进行进一步分类。图 8 还包括对 Jetson AGX Xavier 未来性能的估计,
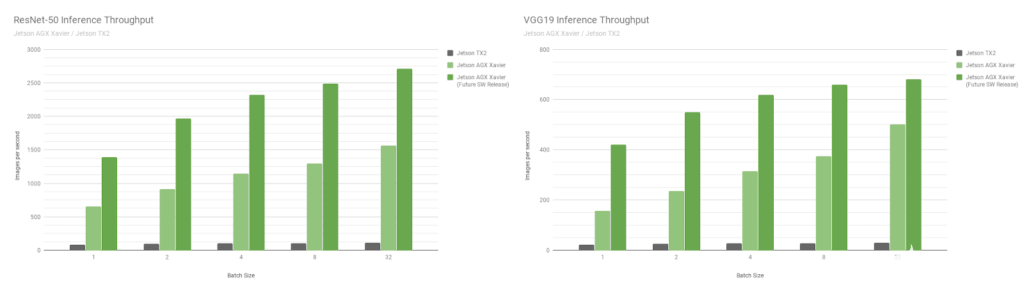
图 8. INT8 支持 DLA 和其他 GPU 优化后的估计性能
Jetson AGX Xavier 目前在 VGG19 上的吞吐量是 Jetson TX2 的 18 倍,在 ResNet-50 上的吞吐量是在 JetPack 4.1.1 上测量的 14 倍,如图 9 所示。ResNet-50 的延迟低至 1.5 毫秒或更高650FPS,批量大小为 1。随着未来的软件改进,Jetson AGX Xavier 估计比 Jetson TX2 快 24 倍。请注意,对于旧版比较,我们还在完整的性能列表中提供了 GoogleNet 和 AlexNet 的数据。
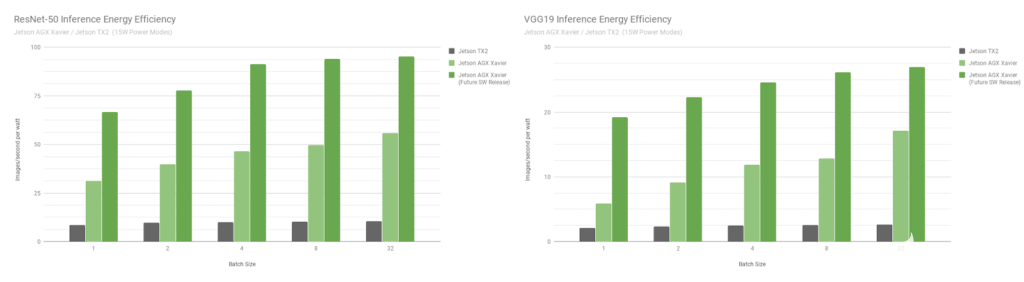
图 9. Jetson Xavier 和 Jetson TX2 的 ResNet-50 和 VGG19 能效
Jetson AGX Xavier 目前在 VGG19 推理方面的效率是 Jetson TX2 的 7 倍以上,在 ResNet-50 方面的效率提高了 5 倍,在考虑未来的软件优化和增强时效率提高了 10 倍。有关推理基准的更多数据和详细信息,请参阅完整的性能结果。我们还将在下一节中对 CPU 性能进行基准测试。
卡梅尔 CPU 复合体
Jetson AGX Xavier 的 CPU 复合体如图 10 所示,由四个基于 ARMv8.2 的异构双核 NVIDIA Carmel CPU 集群组成,最大时钟频率为 2.26GHz。每个内核包括 128KB 指令和 64KB 数据 L1 缓存以及两个内核之间共享的 2MB L2 缓存。CPU 集群共享一个 4MB L3 缓存。

图 10. 带有 NVIDIA Carmel 集群的 Jetson Xavier CPU 复合体的框图
Carmel CPU 内核具有 NVIDIA 的动态代码优化、10 路超标量架构以及 ARMv8.2 的完整实现,包括完整的高级 SIMD、VFP(矢量浮点)和 ARMv8.2-FP16。
SPECint_rate 基准测量多核系统的 CPU 吞吐量。总体性能得分平均了几个密集的子测试,包括压缩、向量和图形操作、代码编译以及为国际象棋和围棋等游戏执行 AI。图 11 显示了几代 CPU 性能提升超过 2.5 倍的基准测试结果。
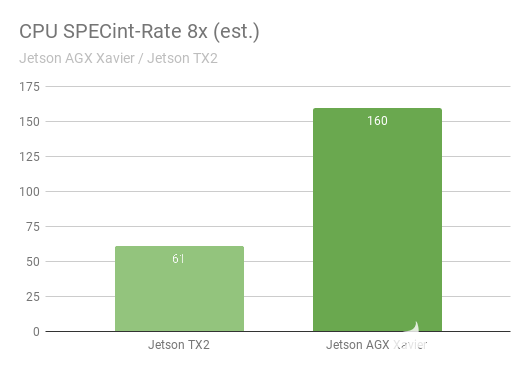
图 11. SPECInt2K_rate 8x* 基准测试中 Jetson AGX Xavier 与 Jetson TX2 的 CPU 性能 *Jetson AGX Xavier / Jetson TX2 SPECint 基准测试尚未正式提交给 SPEC,在发布时被视为估计值。
同时运行了 8 个 SPECint_rate 测试副本,保持 CPU 满载。Jetson AGX Xavier 自然拥有八个 CPU 核心;Jetson TX2 的架构使用四个 Arm Cortex-A57 内核和两个 NVIDIA Denver D15 内核。每个 Denver 核心运行两个副本会产生更高的性能。
视觉加速器
Jetson AGX Xavier 具有两个视觉加速器引擎,如图 12 所示。每个引擎都包括一个双 7 路 VLIW(超长指令字)矢量处理器,用于卸载计算机视觉算法,例如特征检测和匹配、光流、立体视差块匹配、以及低延迟和低功耗的点云处理。卷积、形态算子、直方图、色彩空间转换和扭曲等成像过滤器也是加速的理想选择。
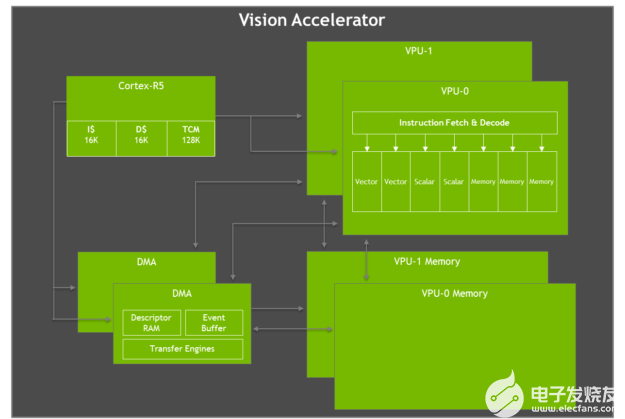
图 12. Jetson AGX Xavier VLIW 视觉加速器架构框图
每个视觉加速器包括一个用于命令和控制的 Cortex-R5 内核、两个矢量处理单元(每个都有 192KB 的片上矢量存储器)和两个用于数据移动的 DMA 单元。7 路向量处理单元包含用于每条指令的两个向量、两个标量和三个内存操作的插槽。Early Access 软件版本不支持 Vision Accelerator,但将在 JetPack 的未来版本中启用。
NVIDIA Jetson AGX Xavier 开发者套件
JetsonAGXXavier 开发套件包含开发人员快速启动和运行所需的一切该套件包括JetsonAGX Xavier 计算模块、参考开源载板、电源和 JetPack SDK,使用户能够快速开始开发应用程序。Jetson AGX Xavier 开发者套件只需 1,299 美元即可购买。
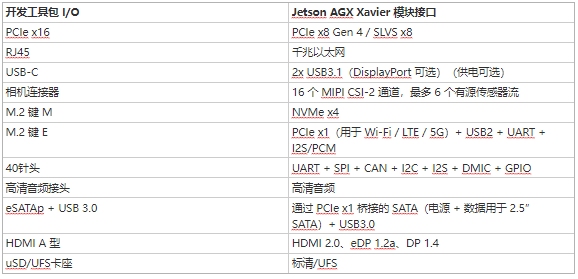
Jetson AGX Xavier 开发工具包的尺寸为 105mm2,明显小于 Jetson TX1 和 TX2 开发工具包,同时改进了可用的 I/O。I/O 功能包括两个 USB3.1 端口(支持 DisplayPort 和 Power Delivery)、一个混合 eSATAp + USB3.0 端口、一个 PCIe x16 插槽(x8 电气)、M.2 Key-M NVMe 和 M.2 Key 站点-E WLAN 夹层、千兆以太网、HDMI 2.0 和 8 摄像头 MIPI CSI 连接器。有关通过开发工具包参考载板提供的 I/O 的完整列表,请参见下面的表 3。
我们为 Jetson AGX Xavier 整理了一个开源的为期两天的深度学习演示教程,该教程指导开发人员通过训练和部署 DNN 推理来执行图像识别、对象检测和分割,使您能够快速开始创建自己的 AI应用程序。两天演示使用云端的 NVIDIA DIGITS 交互式训练系统或 GPU 加速的 PC,并使用 TensorRT 对 Jetson 上的图像或实时摄像头馈送执行加速推理。GitHub 上的为期两天的演示代码存储库已更新,包括对 Xavier DLA 和 GPU INT8 精度的支持。
智能视频分析 (IVA)
人工智能和深度学习能够有效利用大量数据,让城市更安全、更方便,包括交通管理、智能停车和零售店的简化结账体验等应用。NVIDIA Jetson 和 NVIDIADeepStream SDK使分布式智能摄像头能够在边缘实时执行智能视频分析,从而减少传输基础设施上的大量带宽负载,并提高安全性和匿名性。
在 Jetson AGX Xavier 上运行的 IVA 演示视频捕获,具有 30 个并发高清流
Jetson TX2 可以同时处理两个高清流以及对象检测和跟踪。如上面的视频所示,Jetson AGX Xavier 能够以 1080p30 同时处理 30 个独立的高清视频流——提高了 15 倍。Jetson AGX Xavier 提供超过 1850MP/s 的总吞吐量,使其能够解码、预处理、使用基于 ResNet 的检测执行推理,并在超过 1 毫秒的时间内可视化每一帧。Jetson AGX Xavier 的功能大大提高了边缘视频分析的性能和可扩展性。
自治的新时代
Jetson AGX Xavier 提供前所未有的机载机器人和智能机器性能水平。这些系统需要对人工智能驱动的感知、导航和操作具有苛刻的计算能力,以提供强大的自主操作。应用包括制造、工业检测、精准农业和家庭服务。向最终消费者递送包裹并支持仓库、商店和工厂物流的自主递送机器人代表了一类应用。
全自动交付和物流的典型处理流程需要多个阶段的视觉和感知任务,如图 14 所示。移动交付机器人通常具有多个外围高清摄像头,除了激光雷达和其他测距传感器之外,还提供 360° 态势感知。与惯性传感器一起融合在软件中。经常使用前向立体驱动摄像头,需要预处理和立体深度映射。NVIDIA 创建了Stereo DNN模型,其准确性高于传统的块匹配方法来支持这一点。
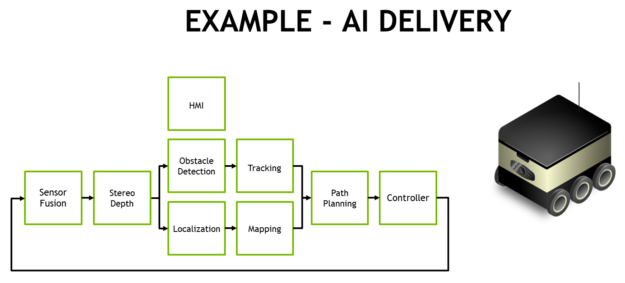
图 14. 自主配送和物流机器人的 AI 处理流程示例
SSD 或 Faster-RCNN 等对象检测模型和基于特征的跟踪通常会告知行人、车辆和地标的避障。对于仓库和店面机器人,这些对象检测模型可以定位感兴趣的物品,例如产品、货架和条形码。面部识别、姿势估计和自动语音识别 (ASR) 促进了人机交互 (HMI),使机器人能够与人类进行有效协调和交流。
高帧率同步定位和映射 (SLAM) 对于保持机器人在 3D 中准确定位至关重要。GPS 本身缺乏亚米级定位的精度,并且在室内无法使用。SLAM 将最新的传感器数据与系统在其点云中积累的先前数据进行配准和对齐。经常有噪声的传感器数据需要大量过滤才能正确定位,尤其是来自移动平台的数据。
路径规划阶段通常使用 ResNet-18 FCN、SegNet 或 DeepLab 等语义分割网络来执行自由空间检测,告诉机器人在哪里行驶而不被遮挡。现实世界中经常存在太多需要单独检测和跟踪的通用障碍物类型,因此基于分割的方法用其分类标记每个像素或体素。与管道的前几个阶段一起,这会通知规划者和控制回路它可以采取的安全路线。
Jetson AGX Xavier 的性能和效率使得这些机器人能够实时处理所有需要的组件,以实现完全自主的安全运行,包括用于实时感知、导航和操作的高性能视觉算法。随着独立的 Jetson AGX Xavier 模块现已投入生产,开发人员可以将这些 AI 解决方案部署到下一代自主机器。
立即开始构建下一波自主机器
Jetson AGX Xavier 为机器人和边缘设备带来了改变游戏规则的计算水平,为针对尺寸、重量和功率进行了优化的嵌入式平台带来了高端工作站性能。
关于作者
Dustin 是 NVIDIA Jetson 团队的一名开发人员推广员。Dustin 拥有机器人技术和嵌入式系统方面的背景,喜欢在社区中提供帮助并与 Jetson 合作开展项目。
审核编辑:郭婷
-
机器人
+关注
关注
212文章
28869浏览量
209455 -
NVIDIA
+关注
关注
14文章
5099浏览量
104289
发布评论请先 登录
相关推荐
探索NVIDIA Jetson与DeepSeek融合的无限可能
研华发布全系列车载AI控制器,引领智能轨道交通新时代
交通运输领先企业率先采用NVIDIA Cosmos平台
NVIDIA发布小巧高性价比的Jetson Orin Nano Super开发者套件
NVIDIA 推出高性价比的生成式 AI 超级计算机

u-blox深化与NVIDIA Jetson和NVIDIA DRIVE Hyperion平台合作
使用NVIDIA AI平台确保医疗数据安全
初创公司借助NVIDIA Metropolis和Jetson提高生产线效率
使用NVIDIA Jetson打造机器人导盲犬
使用机器学习和NVIDIA Jetson边缘AI和机器人平台打造机器人导盲犬
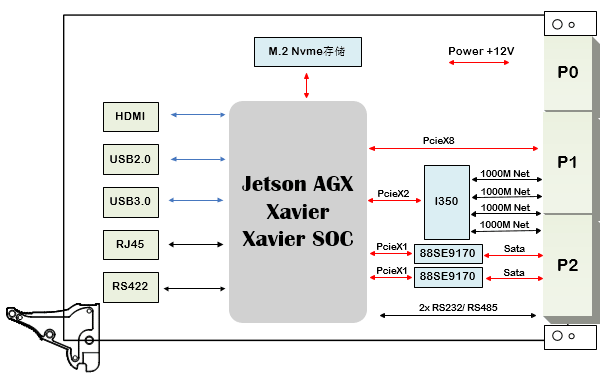
GPU计算主板学习资料第735篇:基于3U VPX的AGX Xavier GPU计算主板 信号计算主板 视频处理 相机信号
fx3系列的硬件主要由什么组成
NVIDIA JetPack 6.0版本的关键功能






 工商网监
工商网监
评论