 NVIDIA Isaac Initiative应用在领域训练和部署高级AI中
NVIDIA Isaac Initiative应用在领域训练和部署高级AI中
NVIDIA 发布了JetPack 3.1,这是用于 Jetson TX1 和 TX2 的生产 Linux 软件版本。随着对 TensorRT 2.1 和 cuDNN 6.0 的升级,JetPack 3.1 为视觉引导导航和运动控制等实时应用提供了高达 2 倍的深度学习推理性能提升,这些应用受益于加速的批量大小 1。改进的功能使 Jetson 能够部署比以往任何时候都更强大的智能,实现一代自主机器,包括送货机器人、远程呈现和视频分析。为了进一步推动机器人技术的发展,NVIDIA 最近推出的 Isaac Initiative 是一个端到端平台,用于在该领域训练和部署高级 AI。
边缘的人工智能
今年春天早些时候,当 NVIDIA 推出Jetson TX2时,事实上的边缘计算平台在功能上得到了显着提升。如图 1 中的 Wave Glider 平台所示,位于网络边缘的远程物联网 (IoT) 设备经常会遇到网络覆盖、延迟和带宽下降的情况。虽然物联网设备通常用作将数据中继到云的网关,但边缘计算通过访问安全的板载计算资源重新构建了物联网的可能性。NVIDIA 的 Jetson 嵌入式模块在 Jetson TX1 上以 1 TFLOP/s 的速度提供服务器级性能,并在 10W 的功率下将 Jetson TX2 上的 AI 性能提高一倍。
喷气背包 3.1
JetPack 3.1 with Linux For Tegra (L4T) R28.1 是 Jetson TX1 和 TX2 的生产软件版本,具有长期支持 (LTS)。TX1 和 TX2 的 L4T 板级支持包 (BSP) 适用于客户产品化,其共享的 Linux 内核 4.4 代码库提供了两者之间的兼容性和无缝移植。从 JetPack 3.1 开始,开发人员可以在 TX1 和 TX2 上访问相同的库、API 和工具版本。

除了从 cuDNN 5.1 升级到 6.0 以及对 CUDA 8 的维护更新之外,JetPack 3.1 还包括用于构建流应用程序的最新视觉和多媒体 API。您可以将 JetPack 3.1 下载到您的主机 PC,以使用最新的 BSP 和工具刷新 Jetson。
使用 TensorRT 2.1 进行低延迟推理
JetPack 3.1 中包含最新版本的 TensorRT,因此您可以在 Jetson 上部署优化的运行时深度学习推理。TensorRT 通过网络图优化、内核融合和半精度 FP16 支持提高了推理性能。TensorRT 2.1 包括关键功能和增强功能,例如多权重批处理,可进一步提高 Jetson TX1 和 TX2 的深度学习性能和效率并减少延迟。
批量大小 1 的性能已显着提高,从而将 GoogLeNet 的延迟降低到 5 毫秒。对于延迟敏感的应用程序,批量大小 1 提供最低延迟,因为每个帧一到达系统就会被处理(而不是等待批量处理多个帧)。如图 2 所示,在 Jetson TX2 上,使用 TensorRT 2.1 在 GoogLeNet 和 ResNet 图像识别推理方面的吞吐量是 TensorRT 1.0 的两倍。
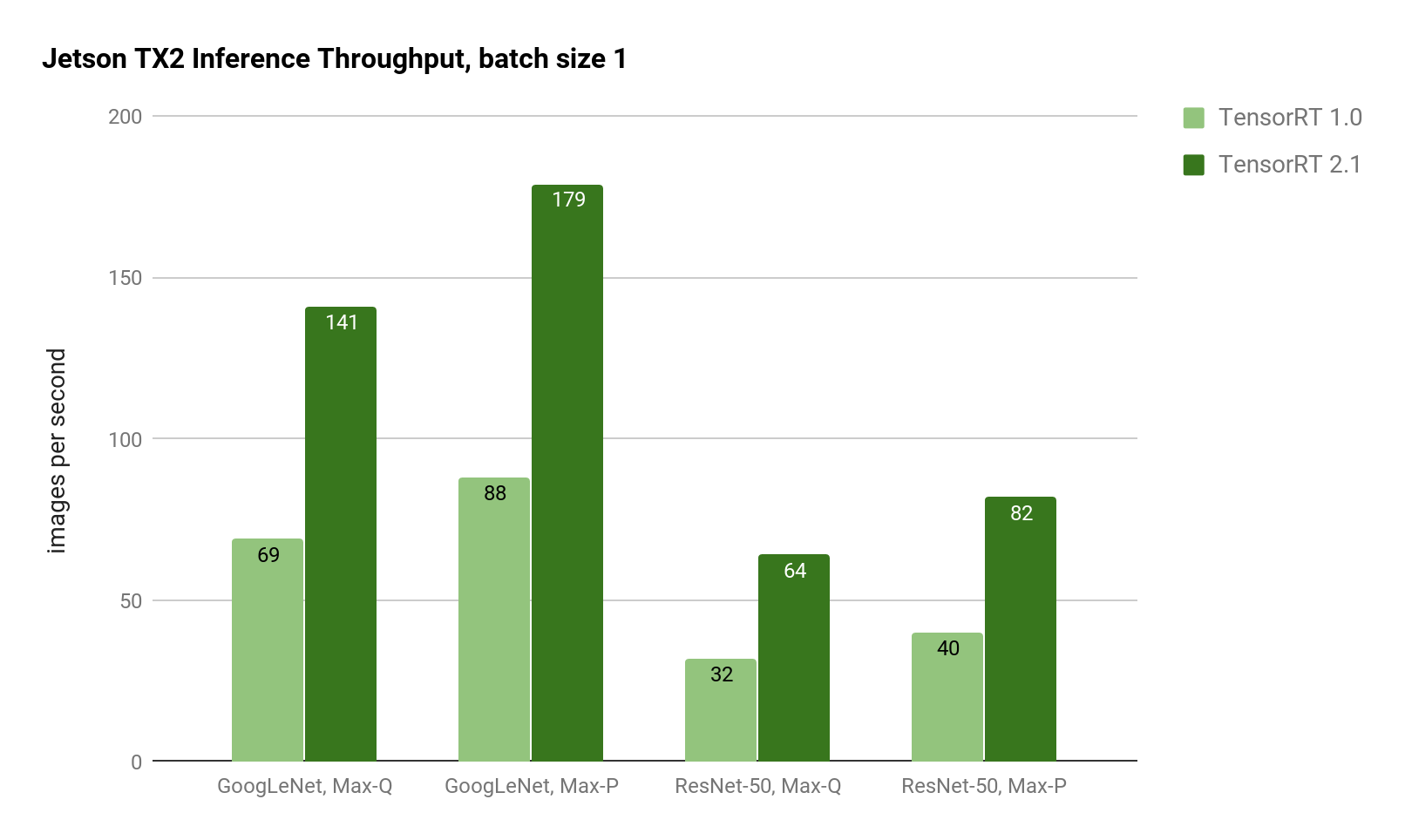
图 2:使用 Jetson TX2 Max-Q 和 Max-P 功率曲线的 GoogLeNet 和 ResNet-50 的推理吞吐量。TensorRT 2.1 在 GoogleLeNet 和 ResNet 上提供两倍的推理吞吐量。
表 2 中的延迟显示随着批量大小 1 的成比例减少。使用 TensorRT 2,Jetson TX2 在 Max-P 性能配置文件中实现了 5ms 的 GoogLeNet 延迟,在 Max-Q 效率配置文件中实现了 7ms 的延迟。ResNet-50 在 Max-P 中具有 12.2ms 的延迟,在 Max-Q 中具有 15.6ms 的延迟。ResNet 通常用于提高图像分类的准确性,超越 GoogLeNet,使用 TensorRT 2.1 可将运行时性能提高 2 倍以上。借助 Jetson TX2 的 8GB 内存容量,即使在 ResNet 等复杂网络上也可以实现高达 128 的大批量。
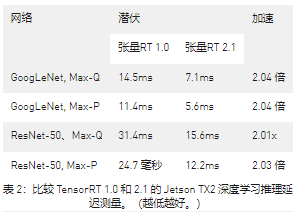
减少的延迟允许深度学习推理方法用于需要近实时响应的应用程序,例如高速无人机和水面车辆的防撞和自主导航。
自定义图层
通过用户插件 API 支持自定义网络层,TensorRT 2.1 能够运行最新的网络和扩展支持的功能,包括残差网络 (ResNet)、循环神经网络 (RNN)、你只看一次 (YOLO) 和更快-RCNN(区域卷积神经网络)。自定义层在用户定义的 C++ 插件中实现,这些插件实现IPlugin了如下代码中的接口。
#include "NvInfer.h" 使用 , *缓冲区);
IPlugin您可以使用与上述代码类似的自定义来构建自己的共享对象。在用户enqueue()函数内部,您可以使用 CUDA 内核实现自定义处理。TensorRT 2.1 使用这种技术来实现Faster-RCNN插件以增强对象检测。此外,TensorRT 为长短期记忆 (LSTM)单元和门控循环单元 (GRU)提供了新的 RNN 层,以改进基于记忆的时序序列识别。开箱即用地提供这些强大的新层类型可加速您在嵌入式边缘应用程序中部署高级深度学习应用程序。
NVIDIA 艾萨克计划
随着边缘 AI 功能的快速增长,NVIDIA 推出了 Isaac Initiative 以推进机器人技术和 AI 的最新发展。Isaac是一个端到端机器人平台,用于开发和部署智能系统到现场,包括模拟、自主导航堆栈和用于部署的嵌入式 Jetson。为了开始开发自主 AI,Isaac 支持图 3 所示的机器人参考平台。这些由 Jetson 提供动力的平台包括无人机、无人地面车辆 (UGV)、无人水面车辆 (USV) 和人类支持机器人 (HSR)。参考平台提供了一个由 Jetson 驱动的基础,可以在现场进行实验,并且该计划将随着时间的推移而扩展,以包括新的平台和机器人。
开始部署 AI
JetPack 3.1 包括 cuDNN 6 和 TensorRT 2.1。它现在可用于 Jetson TX1 和 TX2。凭借将单批次推理的低延迟性能提高一倍,并支持具有自定义层的新网络,Jetson 平台比以往任何时候都更有能力进行边缘计算。
关于作者
Dustin 是 NVIDIA Jetson 团队的一名开发人员推广员。Dustin 拥有机器人技术和嵌入式系统方面的背景,喜欢在社区中提供帮助并与 Jetson 合作开展项目。
审核编辑:郭婷
-
机器人
+关注
关注
211文章
28414浏览量
207048 -
NVIDIA
+关注
关注
14文章
4985浏览量
103033
发布评论请先 登录
相关推荐
NVIDIA通过加速AWS上的机器人仿真推进物理AI的发展
NVIDIA Isaac Sim满足模型的多样化训练需求
日本企业借助NVIDIA产品加速AI创新
利用NVIDIA Isaac平台构建、设计并部署机器人应用

NVIDIA助力Figure发布新一代对话式人形机器人
Foxconn利用NVIDIA AI和Omniverse训练机器人
NVIDIA Isaac 机器人平台利用最新的生成式 AI 和先进的仿真技术,加速 AI 机器人技术的发展
电子制造商采用NVIDIA AI和 Omniverse助力工厂提高运营效率并降低成本
NVIDIA Isaac Manipulator助力让下一代机器人技术触手可及
NVIDIA将数字孪生与实时AI结合实现工业自动化

NVIDIA融合数字孪生与实时AI,革新工业自动化
NVIDIA Isaac机器人平台升级,加速AI机器人技术革新
NVIDIA入局人形机器人!Isaac平台迎来重要更新
NVIDIA将数字孪生与实时AI结合以用于工业自动化

NVIDIA Isaac将生成式AI应用于制造业和物流业





 工商网监
工商网监
评论