 NVIDIA Jetson TK1轻松集成传感器和支持高带宽流媒体
NVIDIA Jetson TK1轻松集成传感器和支持高带宽流媒体
NVIDIA 的 Tegra K1 (TK1) 是首款集成 CUDA 的 Arm 片上系统 (SoC)。TK1 拥有 192 个 Kepler GPU 内核和 4 个 Arm Cortex-A15 内核,提供总计 327 GFLOPS 的计算性能,能够使用 CUDA 处理大量数据,同时通常消耗不到 6W 的功率(包括 SoC 和 DRAM)。这为低于 10W 域中的低 SWaP(尺寸、重量和功率)和小型 (SFF) 应用程序带来了改变游戏规则的性能,同时支持开发人员友好的 Ubuntu Linux 软件环境,提供更像这样的体验台式机而不是嵌入式 SoC。
Tegra K1 即插即用,可通过内置 USB 3.0 和 PCIe gen2 x4/x1 端口传输高带宽外围设备、传感器和网络接口。TK1 适用于传感器处理,并提供与 CUDA 异步的附加硬件加速功能,例如 H.264 编码和解码引擎以及双 MIPI CSI-2 摄像头接口和图像服务处理器 (ISP)。TK1 有许多令人兴奋的嵌入式应用程序,它们利用其作为媒体处理器和低功耗平台的自然能力来快速集成设备和传感器。
由于 GPU 加速特别适合成像、信号处理、自治和机器学习等数据并行任务,Tegra K1 将这些功能扩展到 10W 以下的领域。现在,从 NVIDIA 的高端Tesla HPC 加速器以及GeForce和Quadro独立 GPU 一直到低功耗 TK1,代码可移植性得以保持。可用于 TK1的 CUDA 6工具包的完整版本,包括示例、数学库,例如cuFFT、cuBLAS和NPP,以及 NVIDIA 的 NVCC 编译器。开发人员可以在 TK1 上本地编译 CUDA 代码,也可以从 Linux 开发机器进行交叉编译。CUDA 库和开发工具的可用性确保了在离散 GPU 和 Tegra 上部署 CUDA 应用程序之间的无缝且轻松的可扩展性。还有可用的OpenCV4Tegra以及 NVIDIA 的VisionWorks 工具包.此外,Ubuntu 14.04 存储库包含丰富的用于 Arm 架构的预构建包,可最大限度地减少跟踪和构建依赖项所花费的时间。在许多情况下,只要源代码可用并且没有显式调用 x86 特定指令(如 SSE、AVX 或 x86-ASM),只需稍加修改即可为 Arm 重新编译应用程序。NEON 是 Arm 针对 Cortex-A 系列 CPU 的 SIMD 扩展版本。
借助 NVIDIA 的Jetson TK1 devkit,每个人都可以使用 TK1。Jetson TK1 支持相同的桌面式用户环境,被用作部署坚固、扩展温度 SFF 模块的嵌入式应用程序的有效开发平台。通过 PCIe x4 gen2,模块可以与各种 I/O 夹层集成,为 Tegra 提供许多可能的接口。此外,还有用于流式联网传感器或互连多个 Tegra 的本机板载千兆以太网。让我们考虑一个案例研究,该案例研究突出了 TK1 轻松集成传感器和支持高带宽流媒体的能力。
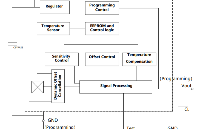
嵌入式应用程序通常需要视频处理、数字信号处理 (DSP)、命令和控制等元素。在这个带有 Tegra K1 的示例架构中,我们使用 CUDA 处理来自高清 GigEVision 千兆位相机的图像,并同时在 180° 光探测和测距 (LIDAR) 扫描测距仪上执行世界地图绘制和障碍物探测操作。此外,我们还集成了 GPS 接收器、惯性测量单元 (IMU)、电机控制器和其他传感器等设备,以演示如何使用 TK1 对移动平台(如机器人或无人机)进行自主导航和运动控制。通过将 Tegra 的硬件加速 H.264 压缩应用于视频和通过 WiFi、3G/4G、或卫星下行链路到远程地面站或其他联网机器人。该架构使用 TK1 作为系统的中央处理器和传感器接口,为感知建模和无人驾驶提供了一个示例框架。
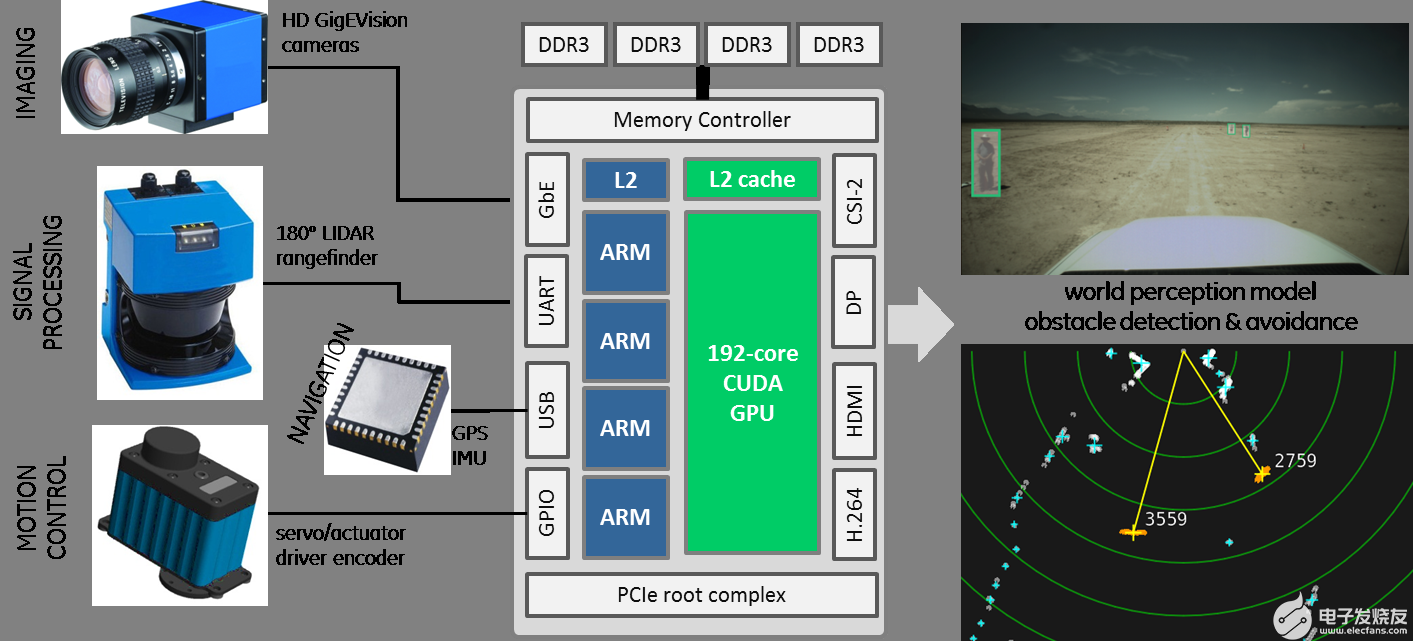
图 2:使用 Tegra K1 实现的用于自主导航的传感器处理管道。
我们使用的扫描激光雷达在 180 度范围内每 0.5° 产生一次距离样本,这些样本被分组为集群检测到运动时使用均值偏移和跟踪。CUDA 用于同时处理所有范围样本,并与从以前的地理参考 LIDAR 扫描构建的八叉树分区 3D 点云进行变化检测,生成静态和移动障碍物列表,实时刷新以进行碰撞检测和避免。然后在 OpenGL 端渲染类似雷达的平面位置指示器 (PPI)。这个特殊的激光雷达通过 RS232 连接到 Jetson TK1 的串行端口;其他激光雷达也支持千兆以太网。我们使用开源 SICK Toolbox 库连接到传感器,该库在 TK1 上编译并开箱即用。轻松访问 LIDAR 传感器为 TK1 提供了亚毫米级精确读数,可利用 CUDA 进行实时 3D 环境映射和并行路径规划。
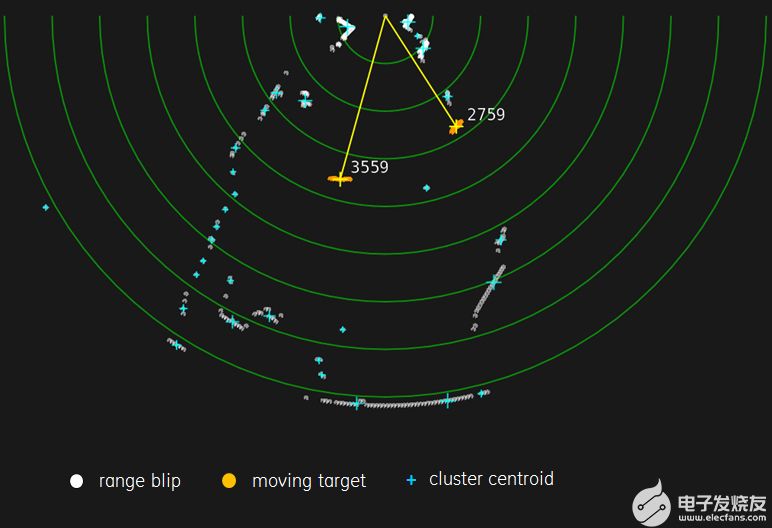
图 3:LIDAR 驱动的 PPI 显示器可视化平台环境中的静态和移动障碍物。
在成像方面,Tegra K1 拥有多个接口用于流式传输高清视频,例如 CSI-2、USB 3.0 和千兆以太网。适用于 HD-SDI、CameraLink、LVDS 等其他媒体的图像采集卡可以通过其 PCIe gen2 x4 端口与 TK1 集成。在本案例研究中,我们使用来自 GigEVision 兼容供应商的多台千兆以太网摄像机进行了测试,分辨率从 1920×1080 到 2448×2048 不等,发现每个千兆以太网端口都有一个单独的 Arm CPU 内核,足以处理网络协议和数据包使用套接字 API。使用 cudaMallocManaged()统一内存CUDA 6 的新功能,视频流由 CPU 解包到与 GPU 共享的缓冲区中,需要零副本才能将视频“放入 GPU 内存”(在 TK1 的情况下,它在物理上都是相同的内存)。
使用 OpenCV、NVIDIA NPP 和 VisionWorks 等免费提供的库,用户可以在旅途中运行无数 CUDA 加速的视频过滤器,包括光流、SLAM、立体视差、稳健的特征提取和匹配、镶嵌、和多个移动目标指示器(MMTI)。
可训练的行人和车辆检测器可以使用可用的方向梯度直方图(HoG) 实现在 TK1 上实时运行。有许多现有的 CUDA 代码可用,它们以前在离散 GPU 上运行,现在可以部署在 Tegra 上。
除了激光雷达设备和摄像头,TK1 还支持 GPS 和 IMU 等导航传感器,以提高自主性。这些通常以 USB 或串行设备的形式提供,并且可以轻松地与 TK1 集成。制作支持 GPS 的应用程序的一种快速方法是使用 libgps/gpsd,它为各种 NMEA 兼容设备提供通用软件接口和 GPS 数据报。同时集成了 IMU 传感器,以提供高达 100Hz 或更高刷新率的加速度计、陀螺仪和磁力计读数。TK1 使用高质量卡尔曼滤波融合快速 IMU 和 GPS 数据,以提供 3 空间中的实时插值平台位置,然后使用这些插值从光流中进一步细化视觉里程计。虽然比遵守 NMEA 的 GPS 单元标准化程度低,IMU 设备通常附带供应商提供的 C/C++ 代码,旨在与 libusb 链接,这是一个标准用户空间驱动程序接口,用于在 Linux 上访问 USB 设备。此类利用 libusb 的用户空间驱动程序无需付出任何努力即可从 x86 迁移到 Arm,并使开发人员能够快速将各种设备与 TK1 集成,例如用于驱动伺服器和执行器的 MOSFET 或 PWM 电机控制器、用于监控电池寿命的电压和电流传感器、气体/大气传感器、 ADC / DAC 等等,具体取决于手头的应用。Tegra K1 还具有六个用于驱动离散信号的 GPIO 端口,可用于连接开关、按钮、继电器和 LED。此类利用 libusb 的用户空间驱动程序无需付出任何努力即可从 x86 迁移到 Arm,并使开发人员能够快速将各种设备与 TK1 集成,例如用于驱动伺服器和执行器的 MOSFET 或 PWM 电机控制器、用于监控电池寿命的电压和电流传感器、气体/大气传感器、 ADC / DAC 等等,具体取决于手头的应用。Tegra K1 还具有六个用于驱动离散信号的 GPIO 端口,可用于连接开关、按钮、继电器和 LED。此类利用 libusb 的用户空间驱动程序无需付出任何努力即可从 x86 迁移到 Arm,并使开发人员能够快速将各种设备与 TK1 集成,例如用于驱动伺服器和执行器的 MOSFET 或 PWM 电机控制器、用于监控电池寿命的电压和电流传感器、气体/大气传感器、 ADC / DAC 等等,具体取决于手头的应用。Tegra K1 还具有六个用于驱动离散信号的 GPIO 端口,可用于连接开关、按钮、继电器和 LED。
本案例研究说明了机器人、机器视觉、遥感等常见的感官和计算方面。TK1 提供了一个对开发人员友好的环境,它消除了集成的繁琐工作,使嵌入式 CUDA 应用程序的部署变得容易,同时提供了卓越的性能。
案例研究 #2:平铺 Tegra
某些应用程序可能需要多个 Tegras 协同工作才能满足其要求。Tegra K1 SoC 集群可以平铺并与 PCIe 或以太网互连。从实施这种平铺架构中获得的尺寸、重量和功率优势是巨大的,并将 TK1 的适用性扩展到数据中心和高性能计算 (HPC)。每块板上平铺 4、6、8 或更多 K1 SoC 的密集分布式拓扑是可能的,并提供有利于嵌入式应用程序和 HPC 等的可扩展性。考虑这个基于现有嵌入式系统的示例,采用六个 Tegra K1:
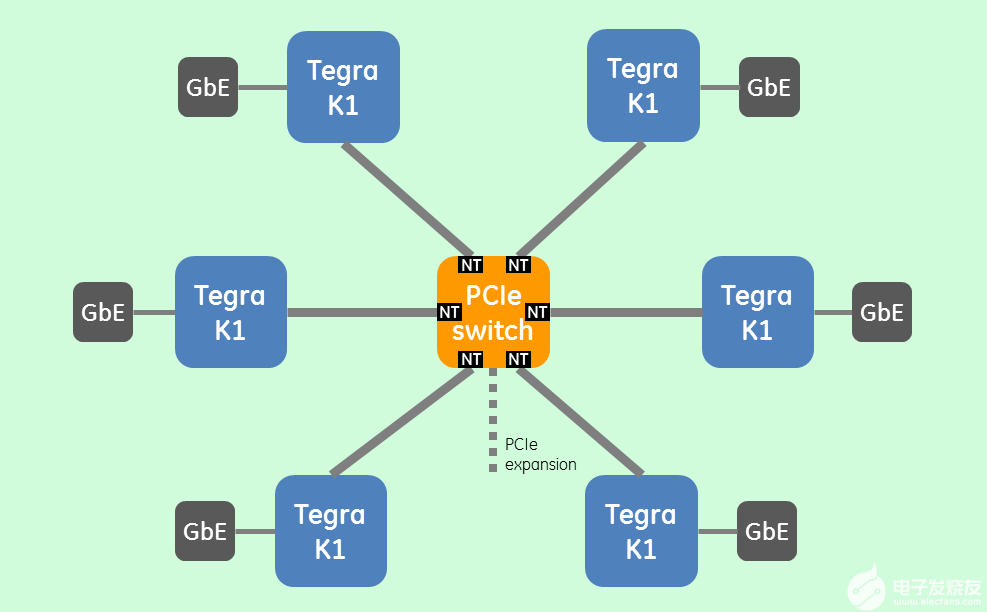
图 5:SWaP 优化的平铺架构,六个 Tegra K1 与非透明 PCIe 交换和 RDMA 互连。
六个 TK1 通过 PCIe gen2 x4 和一个具有非透明 (NT) 桥接和 DMA 卸载引擎的 32 通道 PCIe 交换机互连。这与轻量级用户空间 RDMA 库一起提供了 TK1 之间的低开销处理器间通信。同时,传感器接口由连接到每个 Tegra 的 PCIe gen2 x1 端口的千兆以太网 NIC/PHY 提供。PCIe 交换机还提供了一个备用 PCIe x8 扩展,用于与用户确定的 I/O 接口的高达 4GB/s 的板外连接。
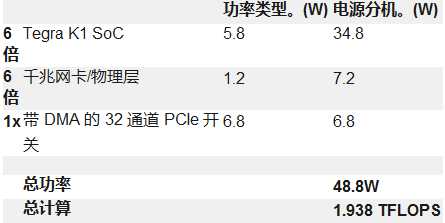
像这样的平铺解决方案能够在消耗不到 50W 的同时实现近 2 TFLOPS 的计算性能,并且与使用更高功率分立元件的架构相比,低功耗集群 SoC 的效率有了很大提高。功率的降低使我们能够在板上放置和布线所有组件,从而实现无连接器的相互通信并提高信号完整性和坚固性。对于大数据分析、多通道视频和信号处理以及机器学习,具有 TK1 的分布式架构为那些需要计算密度同时最小化 SWAP 的真正资源密集型应用程序提供了显着的性能提升。
不可能的高级
Tegra K1 突破性的计算性能由 NVIDIA 的低功耗优化和集成 CUDA 的引入推动,引领新一代嵌入式设备和平台利用 TK1 的 SWaP 密度来提供高级特性和功能。NVIDIA 和 GE 合作将由 TK1 驱动的坚固 SFF 模块和系统带入嵌入式领域。机器人、医疗和可穿戴设备、软件无线电、安全、监控等领域的应用是使用 Tegra K1 进行加速的主要候选者。更重要的是,TK1 的易用性促进了可扩展、可移植的嵌入式系统,缩短了开发周期,而现在在 Tegra 上运行的大量现有 CUDA 库和软件进一步促进了这一点。您今天将使用 TK1 构建什么?
关于作者
Dustin 是 NVIDIA Jetson 团队的一名开发人员推广员。Dustin 拥有机器人技术和嵌入式系统方面的背景,喜欢在社区中提供帮助并与 Jetson 合作开展项目。您可以在NVIDIA 开发者论坛或GitHub 上找到他。
审核编辑:郭婷
-
嵌入式
+关注
关注
5083文章
19129浏览量
305436 -
机器人
+关注
关注
211文章
28438浏览量
207194 -
NVIDIA
+关注
关注
14文章
4990浏览量
103099
发布评论请先 登录
相关推荐
u-blox深化与NVIDIA Jetson和NVIDIA DRIVE Hyperion平台合作
集成式电流传感器NSM211x:从工业到汽车,应用广泛,性能卓越

使用NVIDIA Jetson打造机器人导盲犬
高带宽云服务器有什么用处?这几种用处要知道
ElfBoard技术贴|如何在ELF 1开发板上搭建流媒体服务器

在NVIDIA Holoscan SDK中使用OpenCV构建零拷贝AI传感器处理管线

Nvidia Jetson Nano + CYW55573/AWXB327MA-PUR M.2无法使用操作系统内置的网络管理器管理Wi-Fi如何解决?
纳芯微发布车规级高带宽集成式电流传感器NSM211x系列
纳芯微推出车规级高带宽集成式电流传感器NSM211x系列
纳芯微推出全新的车规级高带宽集成式电流传感器NSM211x系列

纳芯微宣布推出全新的车规级高带宽集成式电流传感器NSM211x系列






 工商网监
工商网监
评论