 使用NVIDIA Jetson AGX Xavier部署新的自主机器
使用NVIDIA Jetson AGX Xavier部署新的自主机器
世界上为人工智能开发者开发的终极嵌入式解决方案, Jetson AGX Xavier ,现在作为独立的生产模块从 NVIDIA 发货。作为自主机器 NVIDIA 的 AGX 系统 的一员, Jetson AGX Xavier 是将先进的人工智能和计算机视觉部署到边缘的理想选择,使机器人平台具有工作站级的性能,并且能够在不依赖人工干预和云连接的情况下完全自主地运行。由 Jetson AGX Xavier 提供动力的智能机器可以自由地在其环境中进行交互和安全导航,不受复杂地形和动态障碍物的阻碍,完全自主地完成现实世界的任务。这包括包装交付和工业检验,需要先进的实时感知和推理能力。作为世界上第一台专门为机器人和边缘计算而设计的计算机, Jetson AGX Xavier 的高性能可以处理视觉里程测量、传感器融合、定位和映射、障碍物检测,以及对下一代机器人至关重要的路径规划算法。开发人员现在可以开始批量部署新的自主机器。

图 1 。 Jetson AGX Xavier 带热传递板( TTP )的嵌入式计算模块, 100x87mm
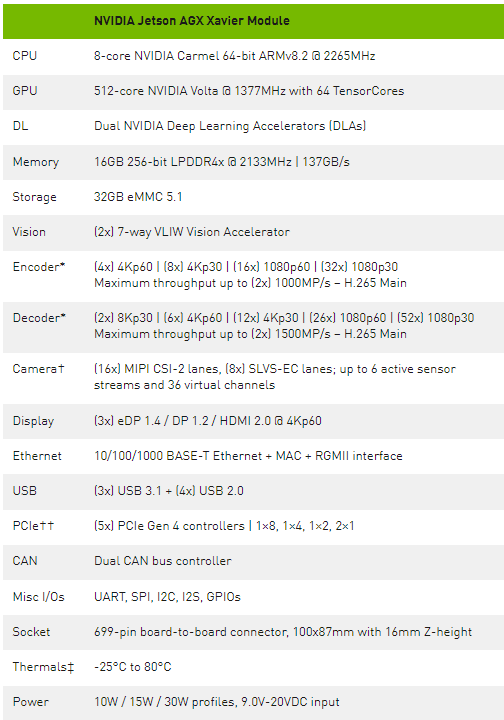
最新一代 NVIDIA 业界领先的嵌入式 Linux 高性能计算机 Jetson AGX 系列, Jetson AGX Xavier 以 100x87mm 的紧凑型外形,提供了 GPU 工作站级的性能和无与伦比的 32 兆兆( TOPS )峰值计算和 750Gbps 的高速 I / O 。用户可以根据应用需要配置 10W 、 15W 和 30W 的工作模式。 Jetson AGX Xavier 为可部署到边缘的计算密度、能源效率和人工智能推断能力设置了新的标准,使具有端到端自主能力的下一级智能机器成为可能。
Jetson 通过深度学习和计算机视觉,为许多世界上最先进的机器人和自动机器提供人工智能,同时专注于性能、效率和可编程性。 Jetson AGX Xavier ,如图 2 所示,由超过 90 亿个晶体管组成,基于有史以来最复杂的片上系统( SoC )。该平台包括集成的 512 核 NVIDIA Volta GPU ,包括 64 张量核 、 8 核 NVIDIA Carmel ARMv8 。 2 64 位 CPU 、 16GB 256 位 LPDDR4x 、双 NVIDIA 深度学习加速器 ( DLA )引擎、 NVIDIA 视觉加速器引擎、高清视频编解码器、 128Gbps 专用摄像头摄取和 16 通道 PCIe Gen 4 扩展。 256 位接口上的内存带宽为 137GB / s ,而 DLA 引擎减轻了深度神经网络( DNNs )的推理任务。 NVIDIA 的 jetpacksdk4 。 1 。 1 适用于 Jetson AGX Xavier 的 jetpacksdk4 。 1 。 1 包括 CUDA 10 。 0 、 cuDNN 7 。 3 和 TensorRT 5 。 0 ,提供了完整的 AI 软件栈。
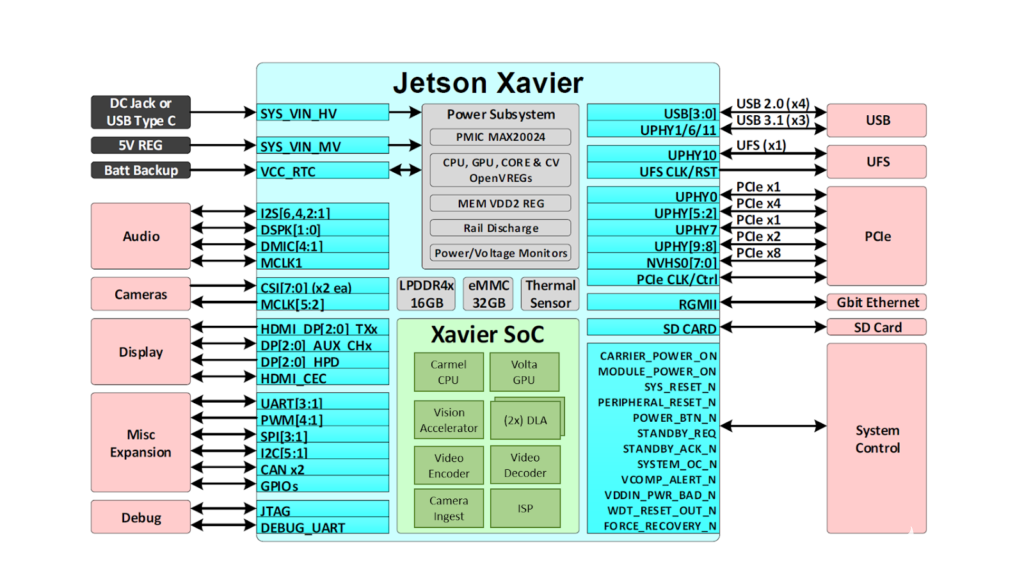
图 2 。 Jetson AGX Xavier 提供了丰富的高速 I / O
这使得开发者能够在机器人、智能视频分析、医疗仪器、嵌入式物联网边缘设备等应用中部署加速人工智能。和它的前辈 Jetson TX1 和 TX2 一样, Jetson AGX Xavier 使用的是模块上系统( SoM )范式。所有的处理都包含在计算模块上,高速 I / O 通过高密度板对板连接器提供的分接载体或外壳上。以这种方式将功能封装在模块上,使开发人员能够轻松地将 Jetson Xavier 集成到他们自己的设计中。 NVIDIA 发布了全面的 文档 和参考设计文件,可供嵌入式设计师使用 Jetson AGX Xavier 创建自己的设备和平台。请务必参考 Jetson AGX Xavier 模块数据表 和 Jetson AGX Xavier OEM 产品设计指南 了解表 1 中列出的全部产品功能,此外还有 eleCTR 机械规范、模块引脚输出、电源顺序和信号布线指南。
Jetson AGX Xavier 包括超过 750Gbps 的高速 I / O ,为流式传感器和高速外围设备提供了超常的带宽。它是最早支持 PCIe Gen 4 的嵌入式设备之一,在五个 PCIe Gen 4 控制器上提供 16 个通道,其中三个控制器可以在根端口或端点模式下运行。 16 个 MIPI CSI-2 通道可连接到 4 个 4 通道摄像头、 6 个 2 通道摄像头、 6 个 1 通道摄像头,或这些配置的组合(最多 6 个摄像头), 36 个虚拟通道允许使用流聚合同时连接更多摄像头。其他高速 I / O 包括三个 USB 3 。 1 端口、 SLVS-EC 、 UFS 和用于千兆以太网的 RGMII 。开发者现在可以访问 NVIDIA 的 JetPack 4 。 1 。 1 开发者预览 软件,用于 Jetson AGX Xavier ,如表 2 所示。开发者预览版包括 Linux For Tegra ( L4T ) R31 。 1 Board Support Package ( BSP ),目标系统支持 Linux 内核 4 。 9 和 Ubuntu18 。 04 。在主机端, Jetpack4 。 1 。 1 支持 Ubuntu16 。 04 和 Ubuntu18 。 04 。
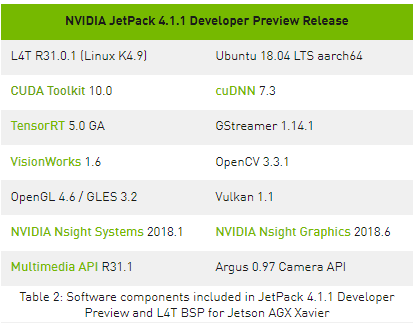
Jetpack4 。 1 。 1 开发者预览版允许开发者立即使用 Jetson AGX Xavier 开始产品和应用程序的原型制作,为生产部署做准备。 NVIDIA 将继续对 JetPack 进行改进,并提供额外的功能增强和性能优化。请阅读 发行说明 了解本版本的亮点和软件状态。
Volta GPU
如图 3 所示, Jetson AGX Xavier 集成 Volta GPU 提供 512 个 CUDA 核和 64 个张量核心,可用于高达 11 TFLOPS FP16 或 22 个 INT8 compute 顶部,最大时钟频率为 1 。 37GHz 。它支持计算能力为 sm _的 CUDA 10 , GPU 包括 8 个 Volta 流式多处理器( sm ),每个 Volta sm 有 64 个 CUDA 核和 8 个张量核。每个 Volta SM 都包括一个 128KB 的 L1 缓存,比前几代大 8 倍。 SMs 共享一个 512KB 的二级缓存,访问速度比前几代快 4 倍。

图 3 。 Jetson AGX Xavier 电压 GPU 方框图
每个 SM 由 4 个独立的处理块组成,称为 SMPs (流式多处理器分区),每个处理块包括自己的 L0 指令缓存、 warp 调度器、调度单元和寄存器文件,以及 CUDA 内核和 Tensor 内核。每个 SM 的 smp 数量是 Pascal 的两倍, Volta SM 的特点是改进了并发性,并且支持更多的线程、扭曲和线程块。
张量核
NVIDIA 张量核心是可编程的融合矩阵乘法和累加单元,它们与 CUDA 核心并行执行。张量核实现了新的浮点 HMMA (半精度矩阵乘法和累加)和 IMMA (整数矩阵乘法和累加)指令,用于加速密集线性代数计算、信号处理和深度学习推理。
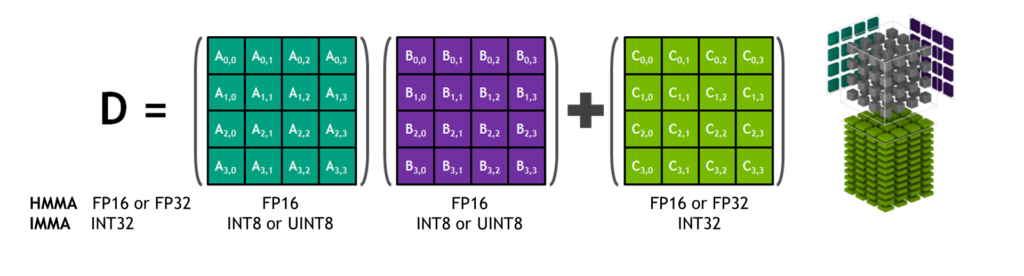
图 4 。张量核 HMMA / IMMA 4x4x4 矩阵乘法和累加
矩阵乘法输入 A 和 B 是 HMMA 指令的 FP16 矩阵,而累加矩阵 C 和 D 可以是 FP16 或 FP32 矩阵。对于 IMMA ,矩阵乘法输入 A 是有符号或无符号的 INT8 或 INT16 矩阵, B 是有符号或无符号的 INT8 矩阵, C 和 D 累加器矩阵都是有符号 INT32 。因此,精度和计算范围足以避免内部积累期间的溢出和下溢情况。
NVIDIA 库包括 cuBLAS 、 cuDNN 和 TensorRT 已被更新,以在内部利用 HMMA 和 IMMA ,使程序员能够轻松地利用张量核固有的性能增益。用户还可以通过在 wmma 名称空间和 CUDA 10 中包含的 mma 。 h 头文件中公开的新 API ,直接访问 warp 级别的 Tensor 核心操作。 warp 级别的接口在每个 warp 的所有 32 个线程上映射 16 × 16 、 32 × 8 和 8 × 32 大小的矩阵。
深度学习加速器
Jetson AGX Xavier 具有两个 NVIDIA 深度学习加速器 ( DLA )引擎,如图 5 所示,它们减轻了固定函数卷积神经网络( CNN )的推理。这些引擎提高了能源效率,并释放了 GPU 来运行更复杂的网络和用户执行的动态任务。 NVIDIA DLA 硬件体系结构是开源的,可从 NVDLA 。 org 网站 获得。每个 DLA 具有高达 5 个 TOP INT8 或 2 。 5 TFLOPS FP16 性能,功耗仅为 0 。 5-1 。 5W 。 DLA 支持加速 CNN 层,如卷积、反褶积、激活函数、最小/最大/平均池、本地响应规范化和完全连接层。
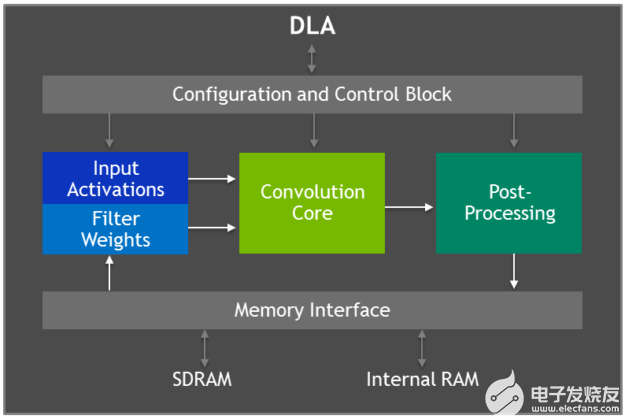
图 5 。深度学习加速器( DLA )架构框图
DLA 硬件由以下组件组成:
卷积核心 – 优化的高性能卷积引擎。
单数据处理器 – 激活功能的单点查找引擎。
平面数据处理器 – 用于池的平面平均引擎。
通道数据处理器–用于高级标准化功能的多通道平均引擎。
专用内存和数据整形引擎 – 用于张量整形和复制操作的内存到内存转换加速。
开发人员使用 TensorRT 5 。 0 编程 DLA 引擎,在网络上执行推断,包括对 AlexNet 、 GoogleNet 和 ResNet-50 的支持。对于使用 DLA 不支持的层配置的网络, TensorRT 为无法在 DLA 上运行的层提供 GPU 回退。 Jetpack4 。 0 开发者预览版最初将 DLA 的精度限制在 FP16 模式,在未来的 JetPack 版本中, DLA 的 INT8 精度和更高的性能将会出现。
TensorRT 5 。 0 在其 IBuilder 接口中添加了以下 API 以启用 DLA :
setDeviceType() 和 setDefaultDeviceType() 用于选择 GPU 、 DLA ® 0 或 DLA ® 1 以执行特定层,或默认情况下用于网络中的所有层。
canRunOnDLA() 检查层是否可以按配置在 DLA 上运行。
getMaxDLABatchSize() 用于检索 DLA 可以支持的最大批处理大小。
allowGPUFallback() 使 GPU 能够执行 DLA 不支持的层。
请参考 TensorRT 5 。 0 开发人员指南 的第 6 章,了解 TensorRT 中支持的层配置和使用 DLA 的代码示例的完整列表。
深度学习推断基准
我们已经为 GPU AGX Xavier 发布了 深度学习推断基准结果 ,这些 dnn 包括 ResNet 、 GoogleNet 和 VGG 的变体。我们在 Jetson AGX Xavier 的 Jetson 和 DLA 引擎上使用 jetpack4 。 1 。 1 开发者预览版 TensorRT 5 。 0 为 Jetson AGX Xavier 运行这些基准测试。 GPU 和两个 dla 分别以 INT8 和 FP16 精度并行运行相同的网络体系结构,并报告每个配置的总体性能。 GPU 和 dla 可以在现实世界的用例中同时运行不同的网络或网络模型,以并行方式或在处理管道中彼此并行地提供独特的功能。在 TensorRT 中使用 INT8 与全 FP32 精度相比,会导致精度损失 1% 或更少。
首先,让我们考虑一下 ResNet-18fcn ( Fully-compolutional Network )的结果,它是一个用于语义分割的 2048 × 1024 分辨率的全高清模型。分段为自由空间检测和占用率映射等任务提供了每像素分类,并代表了由自主机器计算的用于感知、路径规划和导航的深度学习工作负载。图 6 显示了在 Jetson AGX Xavier 和 Jetson TX2 上运行 ResNet-18 FCN 的测量吞吐量。
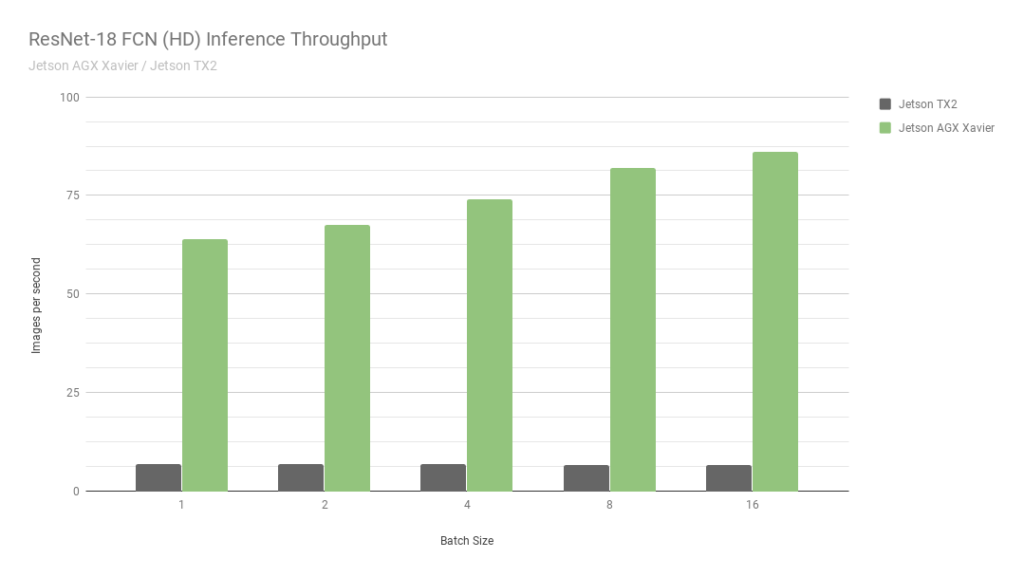
图 6 。 ResNet-18 FCN 推断 Jetson AGX Xavier 和 Jetson TX2 的吞吐量
Jetson AGX Xavier 目前在 ResNet-18 FCN 推理中的性能是 Jetson TX2 的 13 倍。 NVIDIA 将继续在 JetPack 中发布软件优化和功能增强,随着时间的推移,将进一步提高性能和功率特性。请注意, 基准结果 的完整列表报告了 Jetson AGX Xavier 的 ResNet-18 FCN 的性能,但在图 7 中,我们只绘制了批量大小为 16 的 ResNet-18 FCN ,因为 Jetson TX2 能够运行 ResNet-18 FCN ,最大批量为 16 。
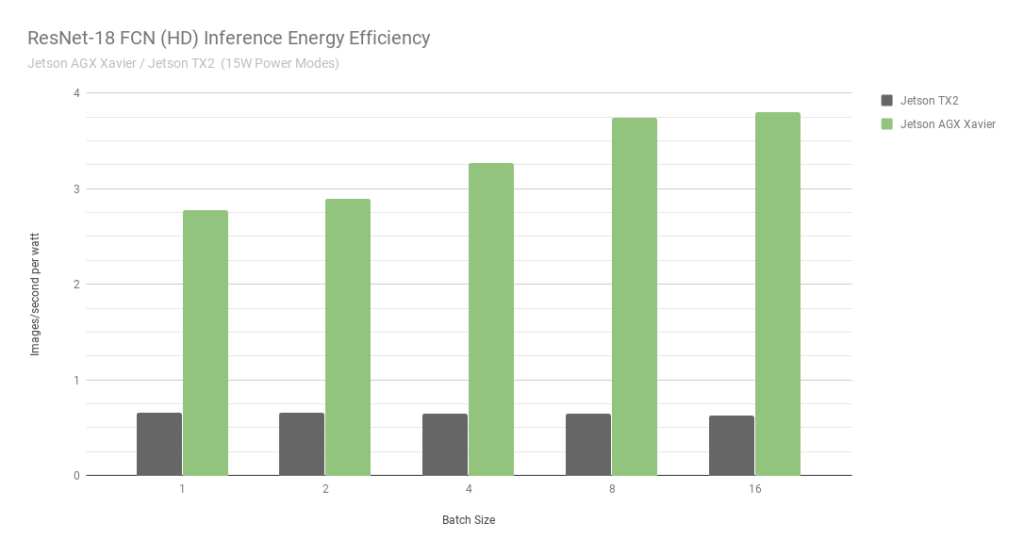
图 7 。 ResNet-18 FCN 推断 Jetson AGX Xavier 和 Jetson TX2 的能量效率
当考虑使用每秒处理的每瓦特图像的能效时, Jetson AGX Xavier 目前比 ResNet-18 FCN 的 Jetson TX2 高 6 倍。我们通过使用板载 INA 电压和电流监测器测量总模块功耗来计算效率,包括 CPU 、 GPU 、 DLA 、内存、其他 SoC 功率、 I / O 和所有轨道上的调节器效率损失。两台 Jetson 都在 15W 电源模式下运行。 Jetson AGX Xavier 和 JetPack 飞船,具有 10W 、 15W 和 30W 的可配置预设功率配置文件,可在运行时使用 nvpmodel 电源管理工具进行切换。用户还可以使用不同的时钟和 DVFS (动态电压和频率缩放)调速器设置来定义自己的自定义配置文件,这些设置已经过定制,以实现单个应用的最佳性能。
接下来,让我们比较一下图像识别网络 ResNet-50 和 VGG19 上的 Jetson AGX Xavier 基准测试,这些基准测试的批量大小从 1 到 128 与 Jetson TX2 。这些模型对分辨率为 224 × 224 的图像块进行分类,常用作各种目标检测网络中的编码器主干。在较低分辨率下使用 8 或更高的批处理大小可用于近似处理较高分辨率下批大小为 1 的性能和延迟。机器人平台和自主机器通常包含多个摄像机和传感器,除了执行感兴趣区域( ROI )的检测,然后分批对 ROI 进行进一步分类,这些摄像头和传感器可以批量处理以提高性能。图 8 还包括对 Jetson AGX Xavier 未来性能的估计,包括软件增强功能,如 INT8 对 DLA 的支持和 GPU 的其他优化。
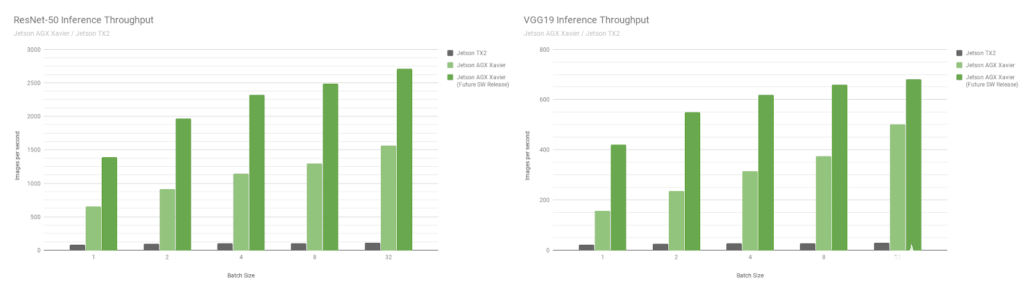
图 8 。 INT8 支持 DLA 和其他 GPU 优化后的估计性能
Jetson AGX Xavier 目前在 VGG19 上的 Jetson TX2 和 ResNet-50 上的吞吐量分别达到 18 倍和 14 倍,如图 9 所示。延迟为 65 。 5 秒,或净大小为 65 。 5 秒/秒。随着未来软件的改进, Jetson AGX Xavier 预计将比 Jetson TX2 快 24 倍。请注意,对于遗留比较,我们还提供了完整的 性能列表 中的 GoogleNet 和 AlexNet 的数据。
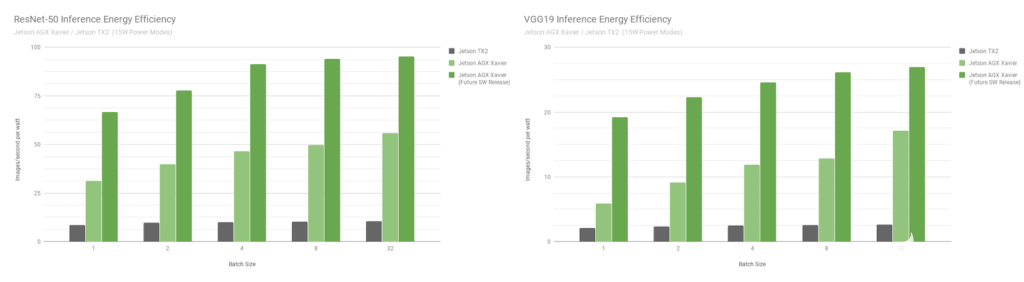
图 9 。 Jetson Xavier 和 Jetson TX2 的 ResNet-50 和 VGG19 能效
Jetson AGX Xavier 目前在 VGG19 推理方面的效率比 Jetson TX2 高 7 倍多,使用 ResNet-50 的效率高 5 倍,考虑到未来的软件优化和增强,效率提高了 10 倍。参考完整的 绩效结果 来获取更多的数据和关于推断基准的细节。我们还将在下一节中对 CPU 的性能进行基准测试。
卡梅尔 CPU 复合体
图 10 所示的 Jetson AGX Xavier 的 CPU 复合体由四个基于 ARMv8 。 2 的异构双核 NVIDIA CarmelCPU 簇组成,最大时钟频率为 2 。 26GHz 。每个核心包括 128KB 指令和 64KB 数据一级缓存,以及两个内核之间共享的 2MB 二级缓存。 CPU 集群共享一个 4MB 的 L3 缓存。
关于作者
Dustin Franklin 是 NVIDIA 的 Jetson 团队的开发人员布道者。 Dustin 拥有机器人和嵌入式系统方面的背景,他乐于在社区中提供帮助,并与 Jetson 一起参与项目。你可以在 NVIDIA Developer Forums 或 Github 上找到他。
审核编辑:郭婷
-
机器人
+关注
关注
212文章
28869浏览量
209455 -
cpu
+关注
关注
68文章
10940浏览量
213739 -
NVIDIA
+关注
关注
14文章
5099浏览量
104289
发布评论请先 登录
相关推荐
探索NVIDIA Jetson与DeepSeek融合的无限可能
云骥智行借助NVIDIA Jetson打造“域脑”通用计算平台
【「具身智能机器人系统」阅读体验】2.具身智能机器人的基础模块
u-blox深化与NVIDIA Jetson和NVIDIA DRIVE Hyperion平台合作
初创公司借助NVIDIA Metropolis和Jetson提高生产线效率
使用NVIDIA Jetson打造机器人导盲犬
使用机器学习和NVIDIA Jetson边缘AI和机器人平台打造机器人导盲犬
GPU计算主板学习资料第735篇:基于3U VPX的AGX Xavier GPU计算主板 信号计算主板 视频处理 相机信号
fx3系列的硬件主要由什么组成
NVIDIA Jetson Orin系列边缘计算主机

如何在tx2部署模型
全球机器人开发领域采用NVIDIA 机器人开发和生产
Nvidia Jetson Nano + CYW55573/AWXB327MA-PUR M.2无法使用操作系统内置的网络管理器管理Wi-Fi如何解决?
借助NVIDIA OSMO扩展AI机器人开发工作负载





 工商网监
工商网监
评论