 使用NVIDIA Triton推理服务器简化边缘AI模型部署
使用NVIDIA Triton推理服务器简化边缘AI模型部署
人工智能机器学习( ML )和深度学习( DL )正在成为解决机器人、零售、医疗保健、工业等领域各种计算问题的有效工具。对低延迟、实时响应和隐私的需求使运行 AI 应用程序处于边缘。
然而,在边缘的应用程序和服务中部署 AI 模型对基础设施和运营团队来说可能是一项挑战。不同的框架、端到端延迟要求以及缺乏标准化实施等因素可能会使 AI 部署具有挑战性。在这篇文章中,我们将探讨如何应对这些挑战,并在边缘生产中部署 AI 模型。
以下是部署推理模型的最常见挑战:
多模型框架:数据科学家和研究人员使用不同的人工智能和深度学习框架,如 TensorFlow 、 PyTorch 、 TensorRT 、 ONNX 运行时或纯 Python 来构建模型。这些框架中的每一个都需要一个执行后端来在生产环境中运行模型。同时管理多个框架后端可能成本高昂,并导致可伸缩性和维护问题。
不同的推理查询类型:边缘推理服务需要处理多个同时查询、不同类型的查询,如实时在线预测、流式数据和多个模型的复杂管道。每一项都需要特殊的推理处理。
不断发展的模型:在这个不断变化的世界中,人工智能模型不断地根据新数据和新算法进行重新训练和更新。生产中的型号必须在不重新启动设备的情况下持续更新。典型的 AI 应用程序使用许多不同的模型。它使问题的规模进一步扩大,以更新现场的模型。
NVIDIA Triton 推理服务器是一款开源推理服务软件,通过解决这些复杂性简化了推理服务。 NVIDIA Triton 提供了一个单一的标准化推理平台,可支持在多框架模型和不同部署环境(如数据中心、云、嵌入式设备、,以及虚拟化环境。它通过高级批处理和调度算法支持不同类型的推理查询,并支持实时模型更新。 NVIDIA Triton 还旨在通过并发模型执行和动态批处理最大限度地提高硬件利用率,从而提高推理性能。
我们用 2021 年 8 月发布的 Jetson JetPack 4.6 将 Triton 推理服务器引入 Jetson 。有了 NVIDIA Triton , AI 部署现在可以跨云、数据中心和边缘标准化。
主要特征
以下是 NVIDIA Triton 的一些关键功能,它们可以帮助您简化 Jetson 中的模型部署。
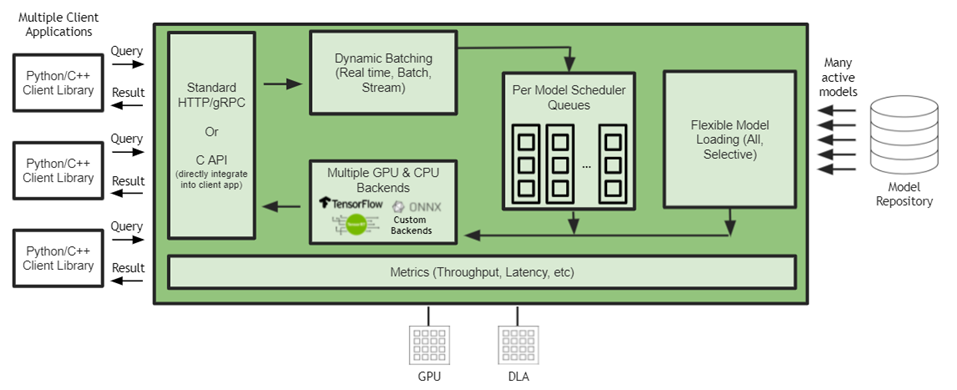
图 1 Jetson Jetson 上的 Triton 推理服务器架构
嵌入式应用集成
客户机应用程序和 Triton 推理服务器之间的通信支持直接 C-API 集成,但也支持 gRPC 和 HTTP / REST 。在 Jetson 上,当客户端应用程序和推理服务都在同一设备上运行时,客户端应用程序可以直接调用 Triton 推理服务器 API ,而通信开销为零。 NVIDIA Triton 是一个带有 C API 的共享库,可使完整功能直接包含在应用程序中。这最适合基于 Jetson 的嵌入式应用程序。
多框架支持
NVIDIA Triton 在本机集成了流行的框架后端,如 TensorFlow 1 。 x / 2 。 x 、 ONNX 运行时 TensorRT ,甚至自定义后端。这允许开发人员直接在 Jetson 上运行他们的模型,而无需经过转换过程。 NVIDIA Triton 还支持添加自定义后端的灵活性。开发人员有自己的选择,基础设施团队使用单个推理引擎优化部署。
DLA 支持
Jetson 上的 Triton 推理服务器可以在 GPU 和 DLA 上运行模型。 DLA 是 Jetson Xavier NX 和 Jetson AGX Xavier 上提供的深度学习加速器。
并发模型执行
Triton 推理服务器通过在 Jetson 上同时运行多个模型,最大限度地提高性能并减少端到端延迟。这些模型可以是所有相同的模型,也可以是来自不同框架的不同模型。 GPU 内存大小是对可同时运行的型号数量的唯一限制。
动态配料
批处理是一种提高推理吞吐量的技术。批处理推理请求有两种方法:客户端批处理和服务器批处理。 NVIDIA Triton 通过将单个推理请求组合在一起来实现服务器批处理,以提高推理吞吐量。它是动态的,因为它构建一个批处理,直到达到一个可配置的延迟阈值。当达到阈值时, NVIDIA Triton 安排当前批执行。调度和批处理决策对请求推断的客户机是透明的,并且根据模型进行配置。通过动态批处理, NVIDIA Triton 在满足严格延迟要求的同时最大限度地提高吞吐量。
动态批处理的一个例子是,应用程序同时运行检测和分类模型,其中分类模型的输入是从检测模型检测到的对象。在这种情况下,由于可以对任意数量的检测进行分类,因此动态批处理可以确保可以动态创建检测对象的批,并且可以将分类作为批处理请求运行,从而减少总体延迟并提高应用程序的性能。
模型组合
模型集成功能用于创建不同模型和预处理或后处理操作的管道,以处理各种工作负载。 NVIDIA Triton 集成允许用户将多个模型和预处理或后处理操作缝合到一个具有连接输入和输出的管道中。 NVIDIA Triton 只需从客户端应用程序向集成发出一个推断请求,即可轻松管理整个管道的执行。例如,尝试对车辆进行分类的应用程序可以使用 NVIDIA Triton 模型集成来运行车辆检测模型,然后在检测到的车辆上运行车辆分类模型。
定制后端
除了流行的 AI 后端, NVIDIA Triton 还支持执行定制的 C ++后端。这些工具对于创建特殊的逻辑非常有用,比如预处理和后处理,甚至是常规模型。
动态模型加载
NVIDIA Triton 有一个模型控制 API ,可用于动态加载和卸载模型。这使设备能够在应用程序需要时使用这些型号。此外,当模型使用新数据重新训练时,它可以无缝地重新部署在 NVIDIA Triton 上,而不会重新启动任何应用程序或中断服务,从而允许实时模型更新。
结论
Triton 推理服务器作为 Jetson 的共享库发布。 NVIDIA Triton 每月发布一次,增加了新功能并支持最新的框架后端。有关更多信息,请参阅 Triton 推理服务器对 Jetson 和 JetPack 的支持。
NVIDIA Triton 有助于在每个数据中心、云和嵌入式设备中实现标准化的可扩展生产 AI 。它支持多个框架,在 GPU 和 DLA 等多个计算引擎上运行模型,处理不同类型的推理查询。通过与 NVIDIA JetPack 的集成, NVIDIA Triton 可用于嵌入式应用。
关于作者
Shankar Chandrasekaran 是 NVIDIA 数据中心 GPU 团队的高级产品营销经理。他负责 GPU 软件基础架构营销,以帮助 IT 和 DevOps 轻松采用 GPU 并将其无缝集成到其基础架构中。在 NVIDIA 之前,他曾在小型和大型科技公司担任工程、运营和营销职位。他拥有商业和工程学位。
Suhas Sheshadri 是 NVIDIA 的产品经理,专注于 Jetson 软件。此前,他曾在 NVIDIA 与自主驾驶团队合作,为 NVIDIA 驱动平台优化系统软件。Mahan Salehi 是 NVIDIA 的深度学习软件产品经理,专注于 Triton 推理服务器。在 NVIDIA 之前,他是一家人工智能初创公司的联合创始人兼首席执行官,此前也曾在医疗器械行业工作。他拥有多伦多大学的工程学学位。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
5026浏览量
103292 -
数据中心
+关注
关注
16文章
4816浏览量
72230 -
深度学习
+关注
关注
73文章
5508浏览量
121308
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论