 如何通过组件配置为深度学习培训选择企业服务器
如何通过组件配置为深度学习培训选择企业服务器
深度学习已经成为执行许多人工智能任务的最常见的神经网络实现。数据科学家使用 TensorFlow 和 PyTorch 等软件框架来开发和运行 DL 算法。
到目前为止,已经有很多关于深度学习的文章,你可以从许多来源找到更详细的信息。有关良好的高层总结,请参见 人工智能、机器学习和深度学习之间有什么区别?
开始深度学习的一种流行方式是在云中运行这些框架。然而,随着企业开始增长和成熟其人工智能专业技能,他们会寻找在自己的数据中心运行这些框架的方法,以避免基于云的人工智能的成本和其他挑战。
在本文中,我将讨论如何为 深度学习培训选择企业服务器。我回顾了这个独特工作负载的具体计算需求,然后讨论了如何通过组件配置的最佳选择来满足这些需求。
DL 培训的系统要求
深度学习培训通常被设计为数据处理管道。必须首先根据数据格式、大小和其他因素准备原始输入数据。
数据通常也会经过预处理,以便相同的输入可以以不同的方式呈现给模型,这取决于数据科学家所确定的将提供更强大的训练集的内容。例如,图像可以随机旋转,以便模型学习识别对象,而不考虑方向。然后将准备好的数据输入 DL 算法。
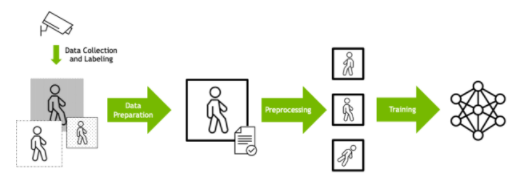
图 1 深度学习培训数据管道
了解了 DL 培训的工作原理后,以下是以最快、最有效的方式执行此任务的具体计算需求。
深度学习的核心是 GPU 。计算网络每一层的值的过程最终是一组庞大的矩阵乘法。每个层的数据通常可以并行处理,各层之间有协调步骤。
GPU 设计用于以大规模并行方式执行矩阵乘法,并已被证明是实现 深度学习的巨大速度 的理想选择。
对于训练,模型的大小是驱动因素,因此具有更大更快内存的 GPU ,比如 NVIDIA A100 GPU 核心张量 ,能够更快地处理成批的训练数据。
中央处理器
DL 训练所需的数据准备和预处理计算通常在 CPU 上执行,尽管 recent innovations 已经使越来越多的计算能够在 GPU 上执行。
使用高性能的 CPU 以足够快的速度维持这些操作是至关重要的,这样 GPU 就不会因为等待数据而感到饥饿。 CPU 应该是企业级的,例如来自英特尔至强可扩展处理器系列或 AMD EPYC 系列,而且 CPU 内核与 GPU 的比例应该足够大,以保持流水线运行。
系统存储器
特别是对于当今最大的机型, DL 训练只有在有大量输入数据可供训练时才有效。这些数据从存储器中批量检索,然后由 CPU 在系统内存中处理,然后再馈送到 GPU 。
为了保持该进程以持续的速度运行,系统内存应该足够大,以便 CPU 处理的速率可以与 GPU 处理数据的速率相匹配。这可以用系统内存与 GPU 内存的比率来表示(在服务器中的所有 GPU 中)。
不同的模型和算法需要不同的比率,但最好有更高的比率,这样 GPU 就永远不会等待数据。
网络适配器
随着 DL 模型变得越来越大,已经开发出了多种技术来执行训练,多个 GPU 一起工作。当一台服务器中安装了多个 GPU 时,它们可以通过 PCIe 总线相互通信,尽管可以使用 NVLink 和 NVSwitch 等更专业的技术来实现最高性能。
Multi- GPU 培训也可以扩展到跨多台服务器的工作。在这种情况下,网络适配器成为服务器设计的关键组件。在执行多节点 DL 训练时,需要高带宽 Ethernet 或 InfiniBand 适配器来最大限度地减少由于数据传输而产生的瓶颈。
DL 框架利用 NCCL 等库以最佳和性能的方式执行 GPU 之间的协调。 GPUDirect RDMA 等技术使数据能够从网络直接传输到 GPU ,而无需通过 CPU ,从而消除了延迟源。
理想情况下,系统中每一两个 GPU 就应该有一个网络适配器,以便在必须传输数据时最大限度地减少争用。
存储
DL 培训数据通常驻留在外部存储阵列上。服务器上的 NVMe 驱动器通过提供缓存数据的方法,可以大大加快培训过程。
DL I / O 模式通常由读取训练数据的多次迭代组成。训练的第一步(或 epoch )读取用于开始训练模型的数据。如果在节点上提供了足够的本地缓存,则后续的数据传递可以避免从远程存储中重新读取数据。
为了避免从远程存储中提取数据时发生争用,每个 CPU 应该有一个 NVMe 驱动器。
PCIe 拓扑
由于 CPU 、 GPU 和网络之间存在复杂的相互作用,因此应该清楚的是,具有减少 DL 培训管道中任何潜在瓶颈的连接设计对于实现最佳性能至关重要。
如今,大多数企业服务器使用 PCIe 作为组件之间的通信手段。 PCIe 总线上的主要流量发生在以下路径上:
从系统内存到 GPU
在多次 GPU 培训期间,在相同服务器上的 GPU 之间
在多节点培训期间 GPU 与网络适配器之间
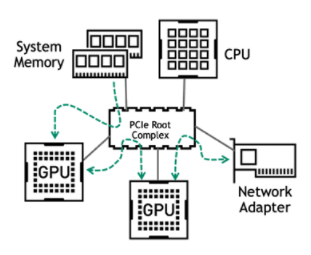
图 2 主 PCIe 数据通信路径
用于深度学习的服务器应具有平衡的 PCIe 拓扑结构, GPU 均匀分布在 CPU 插槽和 PCIe 根端口上。在所有情况下,每个 GPU 的 PCIe 通道数应为支持的最大数量。
如果存在多个 GPU ,且 CPU 的 PCIe 通道数量不足以容纳所有通道,则可能需要 PCIe 交换机。在这种情况下, PCIe 交换机层的数量应限制为一层或两层,以最小化 PCIe 延迟。
类似地,网络适配器和 NVMe 驱动器应与 GPU 处于同一 PCIe 交换机或 PCIe 根复合体之下。在使用 PCIe 交换机的服务器配置中,这些设备应与 GPU 位于同一 PCIe 交换机下,以获得最佳性能。
选择支持 DL 培训的经过验证的系统
设计一个为 DL 培训而优化的服务器很复杂。 NVIDIA 已经发布了 关于为各种类型的加速工作负载配置服务器的指南 ,基于多年在这些工作负载方面的经验,并与开发人员合作优化代码。
为了让你更容易上手,NVIDIA 开发了 NVIDIA-Certified Systems 程序。系统供应商合作伙伴已使用特定的 NVIDIA GPU 和网络适配器配置并测试了多种形式的服务器型号,以验证 优化设计以获得最佳性能 的有效性。
验证还包括生产部署的其他重要功能,如可管理性、安全性和可伸缩性。系统经过针对不同工作负载类型的一系列类别认证。 合格系统目录 有一份由 NVIDIA partners 提供的经 NVIDIA 认证的系统列表。数据中心类别的服务器已经过验证,可以为 DL 培训提供最佳性能。
NVIDIA 人工智能企业
除了合适的硬件,企业客户还希望为 AI 工作负载选择受支持的软件解决方案。 NVIDIA 人工智能企业 是一套端到端、云计算原生的人工智能和数据分析软件。它经过优化,因此每个组织都可以擅长人工智能,经过认证可以部署在从企业数据中心到公共云的任何地方。人工智能企业包括全球企业支持,以便人工智能项目保持正常运行。
当您在优化配置的服务器上运行 NVIDIA AI Enterprise 时,您可以放心,您正在从硬件和软件投资中获得最佳回报。
总结
在本文中,我向您展示了如何为 深度学习培训 选择具有特定计算需求的企业服务器。希望您已经学会了如何通过组件配置的最佳选择来满足这些需求。
关于作者
Charu Chaubal 在NVIDIA 企业计算平台集团从事产品营销工作。他在市场营销、客户教育以及技术产品和服务的售前工作方面拥有 20 多年的经验。 Charu 曾在云计算、超融合基础设施和 IT 安全等多个领域工作。作为 VMware 的技术营销领导者,他帮助推出了许多产品,这些产品共同发展成为数十亿美元的业务。此前,他曾在 Sun Microsystems 工作,在那里他设计了分布式资源管理和 HPC 基础设施软件解决方案。查鲁拥有化学工程博士学位,并拥有多项专利。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
5087浏览量
103915 -
云计算
+关注
关注
39文章
7856浏览量
138028 -
服务器
+关注
关注
12文章
9342浏览量
86206
发布评论请先 登录
相关推荐
如何选择合适的云服务器 --X 实例购买指南和配置详细说明
SMTP服务器配置教程
恒讯科技分享:独立服务器的选择技巧






 工商网监
工商网监
评论